




Comment identifier des modèles temporels suspects dans les données de trafic ?
Chez DataDome, nous utilisons des modèles d’apprentissage automatique (machine learning, ou ML) pour détecter les menaces en tirant parti de l’incroyable quantité de signaux collectés auprès de nos clients. En fait, notre moteur de détection traite plus de 5 trillions de signaux par jour ! Plus nous pouvons rassembler de données, mieux nos modèles fonctionnent contre les menaces connues et inconnues.
Une méthode que nous utilisons pour traiter les données est une analyse de séries temporelles, qui identifie les comportements suspects sur différentes échelles de temps – des pics énormes aux bots « lents et faibles » – en se concentrant sur les modèles temporels (basés sur le temps) dans le trafic.
Segmentation du trafic
Pour commencer, de quelles séries temporelles parlons-nous ?
Le trafic web que nous recueillons peut être segmenté en plusieurs sous-séries temporelles.
1. Recueillir une vue d’ensemble du trafic global
Tout d’abord, chaque client de DataDome a ses propres spécificités – ils font face à des défis particuliers et à diverses menaces. Par conséquent, nous analysons le trafic par client : c’est le premier niveau de segmentation.

Trafic d’une journée pour un client DataDome spécifique.
2. Répartition du trafic global par catégorie choisie
Pour un client donné, nous divisons le trafic global en plusieurs segments. La cardinalité du champ catégoriel (c’est-à-dire son nombre de modalités) est essentielle pour définir combien de sous-groupes (séries temporelles) sont considérés. Plus la cardinalité est élevée, plus nous obtenons de séries temporelles. Cependant, il y a un compromis : si la segmentation est trop granulaire, elle devient beaucoup moins utile.
Dans cet article, nous avons choisi les systèmes autonomes (AS) comme champ de segmentation. Un AS est constitué d’au moins un (généralement plusieurs) préfixe IP géré par un ou plusieurs opérateurs de réseau, qui appliquent tous une politique de routage unique et clairement définie. Aux États-Unis, AT&T, Comcast et Verizon sont des exemples de systèmes autonomes.
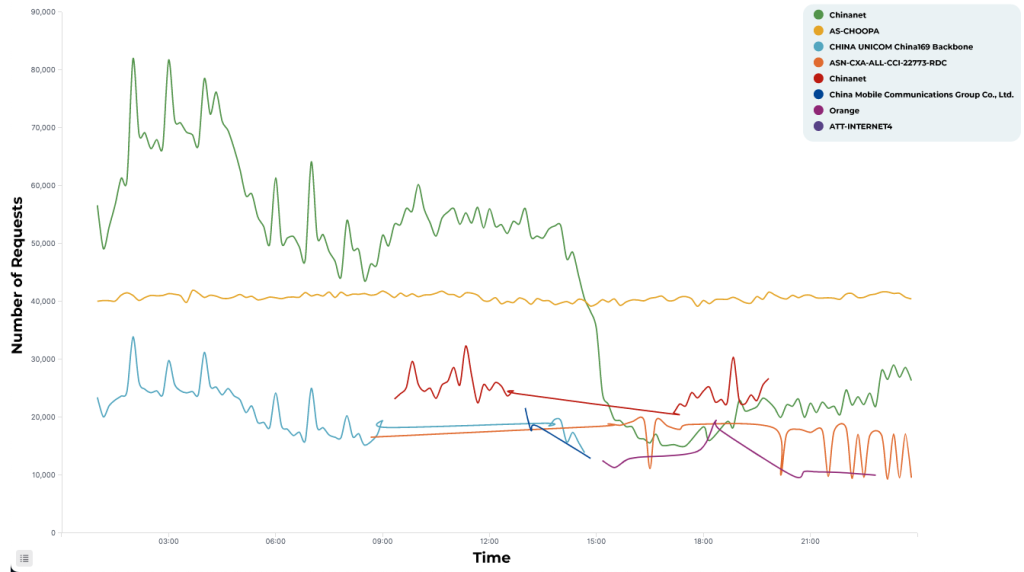
Un jour de trafic pour un client spécifique, segmenté par AS. Pour une meilleure lisibilité, seule une partie des AS est affichée.
3. Appliquer un ou plusieurs modèle(s) de ML
À partir de là, plusieurs modèles ML sont possibles. Nous en présenterons deux :
- Une approche d’Apprentissage non-supervisé
- Une approche d’Apprentissage supervisé
Modélisation de l’apprentissage automatique
Exemple d’apprentissage non-supervisé
Les méthodes d’apprentissage non-supervisé cherchent à détecter automatiquement des motifs d’activité intéressants dans des données non étiquetées. Une approche d’apprentissage non-supervisé est le clustering — c’est-à-dire le regroupement des séries temporelles similaires. En analysant les clusters et les distances par rapport aux clusters, nous pouvons identifier des modèles et/ou des séries temporelles suspects.

L’exemple ci-dessus d’un pipeline de clustering se compose de 3 étapes :
- Extraction des caractéristiques : traitement et agrégation des signaux bruts des séries temporelles. Les variables explicatives, qui peuvent être des caractéristiques statistiques telles que la moyenne, la variance, le minimum, le maximum, etc., alimentent le modèle ML.
- Clustering : regroupement des séries temporelles similaires, ce qui nécessite le choix d’une mesure de similarité (distance euclidienne, corrélation, etc.) ainsi que le choix d’un algorithme (K-means, DBSCAN, etc.).
- Visualisation : la compréhension des résultats peut être plus difficile qu’il n’y paraît, car il faut réduire la dimensionnalité de notre ensemble d’apprentissage pour pouvoir le représenter sur un plan. Des algorithmes spécifiques existent pour accomplir cette tâche : ACP, t-SNE, etc.

Un exemple de visualisation des résultats potentiels en utilisant l’algorithme de clustering K-means, avec K fixé à 4.
Quatre clusters ont été identifiés ci-dessus. Deux sont composés d’une majorité de séries temporelles identifiées comme des bots, les deux autres comme humains. La proportion de chaque classe peut être utilisée pour évaluer l’étiquette du cluster.
Pour chaque cluster, la série temporelle la plus proche du centroïde du cluster — le « lieu » imaginaire représentant le centre du cluster — est affichée. Le centroïde est le point le plus similaire aux autres échantillons dans le même cluster.
- Un cluster de bots correspond à un motif “On/Off”, tandis que l’autre correspond à un motif très périodique.
Une série temporelle se trouve entre les deux clusters de bots. Elle partage des similitudes avec les deux clusters : un motif périodique “On/Off”.
Exemple d’apprentissage supervisé
L’apprentissage supervisé utilise des ensembles de données étiquetées pour entraîner des algorithmes à classer les données ou à prédire les résultats avec précision. Nous introduisons l’étiquette bot/humain de la solution DataDome pour diviser nos séries temporelles AS en série temporelle bot et série temporelle humaine. Le modèle évaluera ensuite chaque série temporelle pour déterminer si elle appartient à un bot ou à un humain.
Notez que cette approche va doubler le nombre de séries temporelles : séries temporelles de bots par AS et séries temporelles humaines par AS.

Ci-dessus, un exemple d’une chaîne de traitement supervisée composée de 3 étapes :
- Extraction des caractéristiques : peut être similaire au clustering, traitant et agrégeant les signaux bruts des séries temporelles. Les variables explicatives, qui peuvent être des caractéristiques statistiques telles que la moyenne, la variance, le minimum, le maximum, etc., alimentent le modèle ML.
- Entraînement du modèle : l’apprentissage de la relation entre nos caractéristiques et l’étiquette bot/humain à partir des données d’entraînement comprend des modèles linéaires, des méthodes d’ensemble, etc.
- Évaluation du modèle : notation d’un sous-ensemble de séries temporelles pour lesquelles nous disposons de l’étiquette connue existante.
Pour arrêter davantage de bots, nous nous intéressons aux séries temporelles étiquetées comme humaines par le système de détection actuel de DataDome, mais avec un score élevé du modèle. Cela peut soit être une erreur du modèle nouvellement formé, soit une mauvaise classification du moteur de détection existant.
Une enquête plus approfondie est nécessaire pour comprendre d’où vient l’erreur et la régler.

Une journée de trafic pour un client et un AS spécifiques (Chinanet) divisé par étiquette de trafic. En rouge, le trafic identifié comme bot par DataDome.
Modèles bloqués par le modèle
Ensuite, nous combinons la modélisation supervisée décrite ci-dessus avec Sliceline, qui est le paquet open-source que nous avons publié l’année dernière, conçu pour la recherche rapide de tranches pour le débogage des modèles ML. (Une tranche est un sous-espace de l’ensemble des données d’entrée défini par un ou plusieurs prédicats. Vous pouvez en savoir plus sur la façon dont Sliceline détecte les erreurs des modèles ML sur notre blog et dans notre documentation Sliceline.)
En combinant la modélisation supervisée décrite ci-dessus avec Sliceline, nous sommes capables de générer automatiquement des règles de blocage basées sur des modèles temporels.
- À partir des séries temporelles, nous identifions deux populations d’AS :
- AS avec des séries temporelles de type humain, où le moteur de détection et le modèle ML sont d’accord sur l’étiquette humaine.
- AS avec des séries temporelles de type bot, où le moteur de détection voit un humain, mais le modèle ML indique un bot potentiel.
- Ensuite, nous passons de la détection comportementale basée sur les séries temporelles à une détection basée sur les signatures. Au lieu d’appliquer Sliceline aux séries temporelles AS et aux caractéristiques précédemment calculées, nous l’appliquons aux signatures des requêtes HTTP constituant les séries temporelles.
Le modèle ML apprend à identifier les comportements temporels anormaux. Il évalue chaque AS pour identifier les tendances manquées des bot. Ensuite, Sliceline découvre ce qui fait d’une requête provenant de notre AS suspect une requête de bot. De cette manière, nous tirons parti de la grande diversité des signaux au niveau de la maille de la requête : user-agent, méthode, hôte, etc.
Une fois que le modèle ML a appris ce qui constitue un comportement temporel suspect, nous obtenons une règle de blocage comme celle-ci : Autonomous System = « AMAZON-02 » & User-agent = « Mozilla/5.0 (X11; Ubuntu; Linux i686; rv:24.0) Gecko/20100101 Firefox/24.0 » & Méthode = « POST »
Nous généralisons ensuite plusieurs schémas suspects que nous avons identifiés. En voici quelques-uns :
- Trafic plat : en général, le trafic humain respecte un modèle jour/nuit. Certains trafics de bots apparaîtront plus « plats » au fil du temps.
- Trafic périodique : un trafic ayant des pics pendant de courtes périodes de temps ressemble à un programme automatisé.
- Pic soudain : il peut s’agir d’une attaque ou d’une sortie très attendue, selon le client.
Les graphiques suivants montrent le nombre de requêtes bloquées au fil du temps par différents modèles de blocage, tous générés par nos modèles d’apprentissage automatique basés sur des séries temporelles.
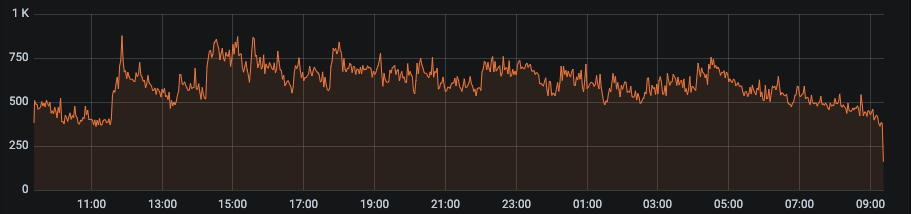
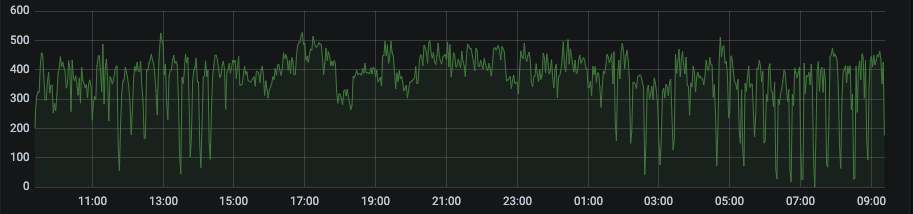
Trafic plat
Exemples de séries temporelles de bots bloquées par notre IA en raison d’un trafic trop plat :

Trafic périodique
Exemples de séries temporelles de bots bloquées par notre IA en raison d’un trafic périodique de courte période :


Pic soudain
Exemple de séries temporelles de bots bloquées par notre IA en raison de pics soudains et élevés de trafic :


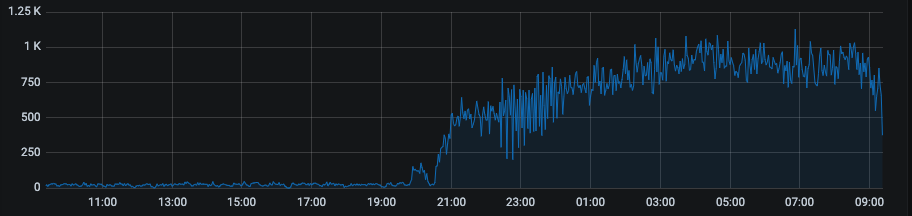
Trafic On/Off
Le modèle ML a réussi à bloquer un quatrième modèle – un modèle « On/Off » directement lié à la qualité de la segmentation. Exemples :

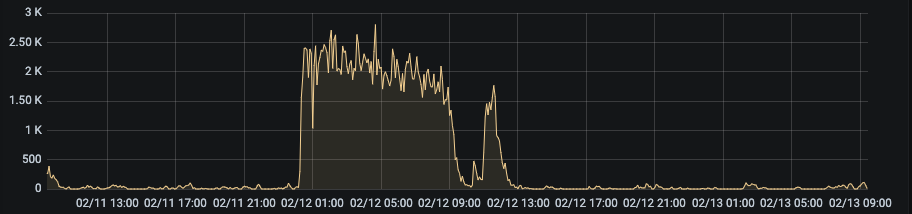
Combinaisons de modèles
Les modèles présentés ci-dessus peuvent être observés simultanément.
Modèles « On/Off » + « pic »

Modèles « plat » + « On/Off »

Modèles périodiques « On/Off » + « pic » + « plat »

Dans le dernier exemple ci-dessus, nous pouvons voir que le bot effectue très peu de requêtes la nuit. Pendant la journée, il passe à un trafic plat. Mais cela n’exclut pas les pics de requêtes, comme dans la nuit du 12 au 13 février à 1h00 du matin.
Conclusion
Dans cet article, nous avons présenté certains résultats de nos modèles ML actuels dédiés à l’analyse de séries temporelles. En nous concentrant sur des champs de segmentation spécifiques, nous sommes en mesure d’identifier automatiquement des modèles temporels suspects et de bloquer le trafic.
Nous avons utilisé l’intelligence artificielle (IA) pour aborder plusieurs problèmes connexes en même temps. Au lieu d’avoir des modèles séparés pour identifier le trafic plat, le trafic périodique, etc., nous avons conçu un seul modèle qui identifie tous les modèles temporels de bots. Pour en savoir plus sur l’utilisation par DataDome du ML et de l’IA pour protéger nos clients contre les bots malveillants et la fraude en ligne, explorez davantage nos aperçus de recherche sur les menaces.

Articles liés

Menaces liées aux agents et tendances du secteur qui ont marqué l'année 2026 (jusqu'à présent)
En savoir plus

Les attaques contre les plateformes de paris sportifs s'intensifient à l'approche de la Coupe du monde de la FIFA 2026
En savoir plus

Libération utilise DataDome + Arc XP pour neutraliser le scraping IA malveillant en moins de 2 millisecondes
En savoir plus

Présentation de Proof of Browser: comment DataDome a bloqué 14 millions de tentatives de contournement
En savoir plus

