




Utiliser Sliceline pour repérer les erreurs des modèles de ML
Dans un article de blog précédent, l’équipe de data science de DataDome a dévoilé Sliceline, un package Python open-source conçu pour le débogage des modèles ML (apprentissage automatique).
Applications de Sliceline sur des ensembles de données open-source
Nous avions annoncé que nous présenterions Sliceline sur un jeu de données emblématique, le Titanic, ce que nous avons fait. Mais nous ne nous sommes pas arrêtés là. Nous avons également appliqué Sliceline à l’ensemble de données California Housing, tiré de la célèbre bibliothèque scikit-learn.
Nous avons choisi ces deux ensembles de données parce qu’ils ont été conçus pour deux tâches d’apprentissage automatique (ML) différentes :
- Classification supervisée (Titanic) : le modèle prédit la classe à laquelle appartient chaque instance.
- Régression supervisée (California Housing) : le modèle prédit une valeur numérique pour chaque instance.
Pour chaque jeu de données, Sliceline nous aide à identifier les sous-populations sur lesquelles notre modèle de ML rencontre des difficultés.
Illustration d’une régression linéaire sur un ensemble de données.
Illustration d’un modèle de classification (K-Nearest Neighbors) sur un ensemble de données.
Classification supervisée (Titanic)
L’ensemble de données Titanic comprend 1 309 enregistrements de passagers, avec des informations telles que l’âge, le sexe, le nombre d’enfants à bord, etc. Vous pouvez consulter tous les détails sur les colonnes de l’ensemble ici.
L’ensemble de données contient également une information essentielle : si les passagers ont survécu ou non à la tragédie du Titanic.
En se basant sur ces informations, on peut tenter de construire un modèle capable de prédire si un passager aurait survécu ou non. Pour cette étude, l’équipe de data science de DataDome a mis en place un pipeline simple en utilisant un classificateur par forêts aléatoires pour la prédiction avec des paramètres par défaut. L’objectif de notre analyse n’est pas d’élaborer le meilleur modèle d’IA possible, mais plutôt de se concentrer sur l’analyse des erreurs de ce modèle.
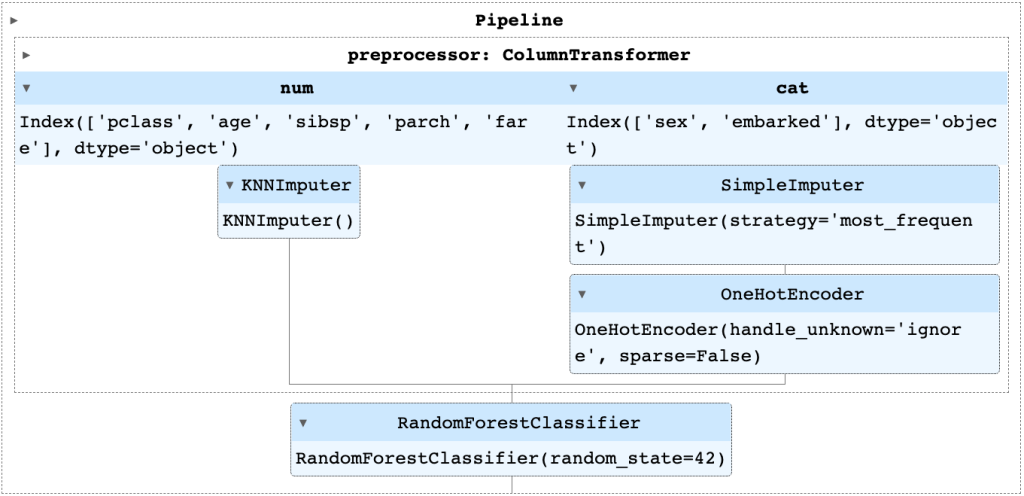
Pipeline complet utilisé dans notre exemple du Titanic :
– les valeurs inconnues des variables numériques et catégorielles sont imputées, mais avec des stratégies différentes ;
– les caractéristiques catégorielles sont ensuite encodées en one-hot afin que la forêt aléatoire puisse traiter efficacement les données.
Le pipeline ci-dessus a estimé les probabilités de survie pour chaque passager, ce qui nous a permis de calculer la log loss (perte logarithmique) pour chaque passager, utilisée comme métrique d’erreur d’entraînement du modèle. Plus la log loss est faible, meilleure est la performance du modèle.
En fournissant à Sliceline l’ensemble de données d’entraînement ainsi que les erreurs d’entraînement individuelles, nous avons pu identifier les sous-populations sur lesquelles le modèle est nettement moins performant.
Le segment le plus difficile à prédire concerne un sous-ensemble de 38 passagers qui :
- voyageaient en troisième classe,
- avaient 39,5 ans ou plus,
- n’avaient ni parents ni enfants à bord,
- et avaient embarqué à Queenstown.
La perte logarithmique du modèle sur l’ensemble des données est de 0,14. Sur cette tranche, elle est de 0,50.
Pour améliorer le modèle, il serait judicieux de se concentrer sur la réduction des erreurs pour ce sous-ensemble de 38 passagers. Une piste pourrait être d’ajouter ou de créer des caractéristiques supplémentaires pour aider le modèle à mieux différencier ce groupe.
Régression supervisée (California Housing)
L’ensemble de données California Housing est un autre ensemble bien connu dans le monde de l’apprentissage automatique. Comme pour le Titanic, il permet de prédire la valeur des maisons en Californie en fonction des caractéristiques des habitations.
Nous avons utilisé le HistGradientBoostingRegressor de scikit-learn comme estimateur, et la Root Mean Square Error (RMSE) comme mesure de performance. Comme pour l’erreur de perte logarithmique, plus la RMSE est faible, mieux c’est.
Sur l’ensemble des données (20 640 maisons), la RMSE d’entraînement est de 0,16.
La tranche sur laquelle notre modèle a le plus de mal à faire des prédictions est celle des maisons où le nombre moyen de membres par foyer est de 2 ou moins. Cette tranche représente 1 756 maisons et la valeur moyenne de l’erreur quadratique moyenne est de 0,37.
Il est intéressant de noter que le segment identifié dans le dataset California Housing repose sur un seul critère, tandis que celui du modèle Titanic était défini par quatre critères.
Pour une compréhension plus approfondie de l’ensemble de données California Housing, nous vous invitons à consulter cette analyse de scikit-learn. Nous avons également mis notre code en open-source pour permettre aux lecteurs curieux d’explorer les détails de l’implémentation :
Conclusion
Dans cet article, nous avons appliqué Sliceline à deux ensembles de données de référence en apprentissage automatique. Grâce à cette approche, nous avons réussi à identifier des sous-populations pour lesquelles nos modèles ML supervisés ont obtenu des résultats significativement moins bons que ceux obtenus sur les ensembles de données complets.
Les segments ont été définis de manière claire et intelligible, en utilisant des jeux de constraste, c’est-à-dire des règles définies par un ensemble de critères. Dans le prochain article de cette série, nous explorerons une application de Sliceline dans un contexte de cybersécurité et plongerons plus en profondeur dans la configuration et les subtilités de l’outil.

Articles liés

Menaces liées aux agents et tendances du secteur qui ont marqué l'année 2026 (jusqu'à présent)
En savoir plus

Les attaques contre les plateformes de paris sportifs s'intensifient à l'approche de la Coupe du monde de la FIFA 2026
En savoir plus

Libération utilise DataDome + Arc XP pour neutraliser le scraping IA malveillant en moins de 2 millisecondes
En savoir plus

Présentation de Proof of Browser: comment DataDome a bloqué 14 millions de tentatives de contournement
En savoir plus

