




Le label Engineering pour les Modèles de Détection de Bots Supervisés
Chez DataDome, nous exploitons quotidiennement des trillions de signaux (signatures, comportements, anomalies, etc.) avec différents types de modèles de ML et des règles d’experts en la matière pour bloquer le trafic malveillant pour nos clients.
La détection basée sur les signatures est une partie essentielle de notre solution, et nous utilisons des milliers de règles d’experts en la matière, mises à jour quotidiennement, pour identifier les bots et les bloquer immédiatement. Rassembler et maintenir notre immense ensemble de règles est une opportunité formidable pour un data scientist, car cela permet de définir le précieux “label” pour un jeu de données.
Dans les cas d’utilisation de la détection de bots, le label indique si la requête est malveillante ou non. Les outils internes de DataDome et les règles basées sur les signatures permettent à notre solution de générer des labels pour des milliards de requêtes quotidiennement—ce qui ouvre des opportunités d’appliquer le machine learning (ML) de manière supervisée.
Créer des labels de qualité pour des milliards de requêtes est un processus complexe nécessitant diverses tâches d’ingénierie. Ce processus d’ingénierie est souvent appelé label engineering dans la communauté des data scientists. Passons en revue certains problèmes intéressants d’ingénierie des labels que nous avons rencontrés et les moyens efficaces de les résoudre.
Labels d’Experts en la Matière & Considérations de Qualité
Règles Basées sur les Signatures des Experts en la Matière
Nos premiers labels proviennent des experts en la matière qui établissent des règles basées sur les signatures pour identifier les bots malveillants. Pour ce faire, ils utilisent les données provenant des signatures des requêtes.
Exemple d’une signature de requête simple :
![]()
Ensuite, pour identifier les bots malveillants, les experts en la matière expriment une déclaration correspondant à un ensemble spécifique de valeurs d’attributs.
Browser=Chrome AND BrowserVersion < 100
Chaque requête correspondant au modèle ci-dessus peut être étiquetée comme une requête de bot en utilisant la règle exprimée. Combiner des milliers de règles nous permet d’identifier très précisément divers types de signatures de bots.
Le processus est appelé « programmatic labeling » (par opposition au manual labeling) et il nous permet de faire évoluer le labeling tout en réduisant les coûts.
Améliorer les Labels des Experts en la Matière
Les labels provenant des règles basées sur les signatures des experts en la matière sont très utiles comme première approche. Mais, comme nous souhaitons faire du ML supervisé, nous devons considérer la qualité d’un label en fonction de son importance dans le processus d’entraînement d’un modèle de ML. Lorsqu’on considère l’entraînement du ML, la cohérence et la justesse des labels sont fondamentales.
- Cohérence signifie que deux échantillons de données identiques doivent avoir le même label.
- Justesse signifie que le label doit refléter la vérité terrain.
Dans de nombreux cas, la vérité terrain n’est pas disponible mais peut être approximée en utilisant un consensus d’experts en la matière.
Exemple :
Pour illustrer la cohérence et la justesse, nous pouvons utiliser le label de détection de bots et considérer un échantillon de données comme un ensemble d’attributs provenant des en-têtes de requêtes HTTP.

- Problème de Cohérence : L’échantillon 1 et l’échantillon 2 sont identiques (considérant les attributs disponibles) mais ont des labels différents. Ainsi, le label est incohérent et nous devons agir. Par exemple, nous pouvons considérer que nous avons trop peu d’attributs de données pour les différencier, nous devons donc collecter plus d’attributs pour avoir des échantillons distincts, ce qui résoudrait notre conflit de labels. Ou bien, nous pouvons écarter les deux échantillons pour éviter l’incohérence.
- Problème de Justesse : L’échantillon 3 semble correct, mais un expert en la matière pourrait établir que la version 10 pour un navigateur Mobile Safari est vraiment ancienne, donc cela pourrait être considéré comme une anomalie. En considérant que l’expert en la matière est un bon proxy pour la vérité terrain, le label de l’échantillon 3 ne doit pas être correct. Nous pouvons agir pour corriger ce label.
Incohérence peut influencer la phase d’apprentissage et avoir un impact négatif sur les performances du modèle. Dans le cas de la détection de bots basée sur les signatures, le modèle ne serait pas capable de faire la distinction entre les bots légitimes et malveillants (augmentation des faux positifs et des faux négatifs).
Inexactitude peut entraîner l’apprentissage de modèles non désirés et des comportements de modèle indésirables. Dans le cas de la détection de bots basée sur les signatures, le modèle serait convaincu qu’un bot malveillant est en fait un utilisateur légitime (augmentation des faux négatifs).
Comment Améliorer la Cohérence et la Justesse des Labels
Améliorer la Cohérence
Les labels proviennent de l’agrégation des règles basées sur les signatures des experts en la matière. Malheureusement, certaines règles peuvent se chevaucher et se contredire, entraînant des incohérences.
Dans ce cas, la cohérence peut être améliorée en écartant les échantillons incriminés, ou en utilisant une approche plus avancée comme les algorithmes de weak supervision.
Améliorer la Justesse
Les règles créées peuvent ne pas couvrir la diversité des signatures de bots car les hackers innovent constamment. Par conséquent, créer et mettre à jour nos règles quotidiennement est très important à long terme.
En raison de la nature inhérente de la détection de bots, il existe toujours de multiples sources de défauts dans la justesse des labels. Certains bots ne peuvent pas être détectés en utilisant uniquement une approche basée sur les signatures car les attaquants forgent tout pour que leurs requêtes paraissent légitimes. Ainsi, de nombreuses requêtes sont mal étiquetées même après l’application des règles basées sur les signatures, ce qui est un point focal principal lorsque nous effectuons l’ingénierie des labels.
Création de Labels pour Entraîner un Modèle de Détection de Bots avec le ML
Évidemment, nous voulons concevoir un processus d’ingénierie des labels qui peut améliorer à la fois la cohérence et la justesse de nos labels provenant des règles des experts en la matière.

Un processus d’ingénierie des labels pour la détection de bots.
Étape 1 : Créer le premier label à partir des règles des experts en la matière.
Nous commençons par rassembler les règles des experts en la matière pour créer un premier label (programmatique), ce qui permet d’identifier de nombreux échantillons comme des bots malveillants.

Les cercles oranges représentent les bots malveillants identifiés par les règles des experts en la matière.
Étape 2 : Améliorer la justesse en utilisant la détection comportementale.
Chez DataDome, nous utilisons non seulement la détection basée sur les signatures, mais aussi la détection comportementale—ce qui signifie que nous pouvons identifier un bot malveillant en fonction de son comportement au fil du temps. En conséquence, le bot peut effectuer plusieurs requêtes avant d’être étiqueté comme bot.
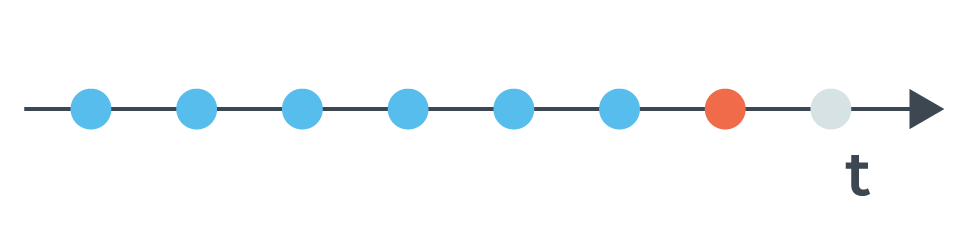
Un bot effectue plusieurs requêtes en peu de temps avant d’être identifié comme malveillant.
Lorsque le bot est identifié, nous répercutons le nouveau label dans le temps pour étiqueter chaque hit précédent du même bot, améliorant ainsi la justesse du label.
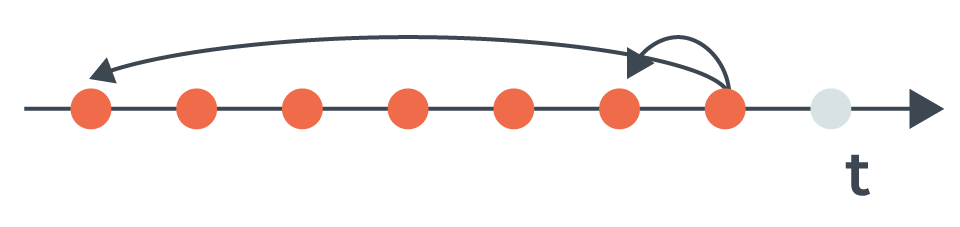
Propagation du label de bot malveillant aux hits précédents.
La propagation entraîne plus de requêtes étiquetées comme des bots malveillants dans l’ensemble des données.

Bots malveillants identifiés par des règles basées sur les signatures et la propagation de la détection comportementale.
Étape 3 : Améliorer la cohérence en projetant les requêtes dans l’espace des caractéristiques.
Lorsque nous entraînons un modèle de machine learning, nous effectuons souvent une certaine ingénierie des données/caractéristiques pour réduire le nombre de dimensions. Ainsi, les données brutes sont projetées dans un espace N dimensions (espace des caractéristiques).
Cette projection entraîne des points de données identiques (1 point de données = 1 requête brute) ayant des labels incohérents.

Pour résoudre le problème, nous agrégeons les deux points tout en conservant le label positif. L’intuition derrière ce choix est que la règle de signature d’origine pourrait avoir été trop restrictive pour capturer les points incriminés dans l’espace d’origine.
Cette étape augmente la cohérence (assure la cohérence dans l’espace des caractéristiques), et diminue légèrement la justesse en raison de l’hypothèse faite.

Points de données étiquetés résultants après correction de la cohérence des labels.
Étape 4 : Créer le jeu de données final étiqueté.
Maintenant, nous pouvons supposer que chaque requête non étiquetée comme bot malveillant provient d’un utilisateur légitime. Notre supposition donne notre jeu de données final—qui peut être utilisé pour entraîner un modèle de ML.

Jeu de données résultant après l’ingénierie des labels (requêtes malveillantes en orange, requêtes légitimes en bleu).
Améliorer la Justesse des Labels avec le Feedback CAPTCHA
Même si nous sommes confiants dans les règles appliquées pour étiqueter les requêtes, nous voulons combler l’écart avec la vérité terrain. Heureusement, chaque fois que nous soupçonnons un utilisateur d’envoyer des requêtes malveillantes, nous pouvons le défier avec un CAPTCHA.

Un utilisateur fait plusieurs requêtes avant d’être considéré comme malveillant et confronté à un défi CAPTCHA.
Ainsi, le résultat du CAPTCHA est un signal qui aide à qualifier un être humain, et nous pouvons introduire une nouvelle étape de traitement dans notre processus d’ingénierie des labels.
Chaque fois qu’un utilisateur est défié par un CAPTCHA, si le CAPTCHA est réussi, nous pouvons propager un label négatif à toutes les requêtes précédentes du même utilisateur.

Les requêtes précédemment suspectes sont étiquetées comme légitimes après un CAPTCHA réussi.
Au contraire, si le CAPTCHA échoue, nous pouvons propager un label positif à toutes les requêtes précédentes du même utilisateur.

Les requêtes précédemment suspectes sont étiquetées comme malveillantes après un CAPTCHA échoué.
Cela nous permet d’améliorer la justesse des labels en tenant compte du feedback CAPTCHA, et réduira finalement notre taux de faux positifs.

Prendre en compte le feedback CAPTCHA dans l’ingénierie des labels de détection de bots.
Aller Plus Loin avec le Weak Supervision
Nous avons détaillé comment nous élaborons des labels de haute qualité pour nos charges de travail ML. Dans l’étape précédente de notre processus d’ingénierie des labels, nous avons fait l’hypothèse audacieuse que tout ce qui n’est pas étiqueté est légitime.
Cependant, il est probable que certaines requêtes malveillantes ne soient toujours pas étiquetées correctement. Nous voulons que notre approche ML détecte les requêtes malveillantes précédemment non détectées, ce qui signifie améliorer encore plus la justesse des labels.
Ainsi, au lieu de considérer les requêtes non étiquetées comme légitimes, nous pourrions envisager de créer des règles pour identifier les requêtes légitimes, similaires à celles que nous avons créées pour les requêtes malveillantes.

Ajout de règles pour étiqueter les requêtes légitimes (en bleu).
Comme illustré, cela conduirait à des règles qui se chevauchent et à des labels incohérents pour certains points de données, et entraînerait également de nombreuses requêtes non étiquetées. Ces deux problèmes peuvent affecter le développement de modèles ML efficaces—c’est là que le weak labeling (WL) entre en jeu.
WL est le processus de combinaison de labels bruyants provenant de divers systèmes (comme les systèmes basés sur des règles) afin d’obtenir des labels probabilistes. Le WL nous permet d’améliorer la cohérence en réduisant le bruit dans les labels générés via des règles.

Les labels probabilistes nous permettent de prendre des décisions sur des cas incohérents.
Le WL nous permet également de générer des labels faibles (probabilistes) pour des points de données précédemment non étiquetés, ce qui augmente finalement la taille de notre jeu de données étiqueté tout en préservant des labels de haute qualité.

De nouveaux labels peuvent être définis avec confiance sur des points de données précédemment non étiquetés.
Une fois terminé, nous pouvons utiliser le jeu de données étiqueté généré pour entraîner un modèle de machine learning dans un processus connu sous le nom de weak supervision.
Exploiter les Labels Créés
Chez DataDome, nous exploitons les processus d’ingénierie des labels pour entraîner des algorithmes de ML supervisé pour la détection de bots. Prendre soin de la cohérence et de la justesse dans une approche centrée sur les données nous permet d’améliorer nos modèles. Par exemple, nous avons amélioré la performance (métrique AUC) d’un modèle de ML classifiant les requêtes comme malveillantes ou non de 3 % en utilisant uniquement l’amélioration de la cohérence.
En fin de compte, générer des labels de haute qualité pour les données d’entraînement ouvre de nombreuses possibilités d’amélioration des performances pour toutes nos applications de ML.
Conclusion
L’ingénierie des labels est une partie essentielle d’un pipeline de ML. Elle aide à tirer parti des labels programmatiques à grande échelle tout en améliorant la cohérence et la justesse des labels. Nous avons démontré que l’ingénierie des labels dans le contexte de la détection de bots implique une expertise en la matière, mais les avantages globaux dépassent largement les efforts requis.

Articles liés

Création d'un SlackBot RAG sur Notion en une journée : retour sur notre hackathon interne
En savoir plus

Comment DataDome a automatisé la création de post-mortems avec l'agent d'IA DomeScribe
En savoir plus

Pourquoi la conformité PCI est essentielle pour la protection des données de paiement, et comment DataDome Page Protect peut vous aider
En savoir plus

Extension de la protection mondiale : DataDome s’étend à plus de 30 points de présence à travers le monde
En savoir plus

