




Création d’un SlackBot RAG sur Notion en une journée : retour sur notre hackathon interne
Pendant les périodes de pointe, il peut être difficile de trouver des procédures techniques dans Notion. DataDome utilise Notion pour documenter plus de 500 procédures techniques internes, notamment les étapes de déploiement et les manuels d’intervention. Bien que cette documentation soit exhaustive, son volume peut rendre difficile la recherche rapide d’informations pertinentes.
Pour résoudre ce problème, nous avons lancé un projet de hackathon d’une journée afin de créer un système interne de génération augmentée par la recherche (RAG), accessible directement depuis Slack. Le résultat ? DomeRunner.
Cet assistant IA est léger, sécurisé et économique. Il peut répondre à des questions techniques complexes et fournir des liens contextuels vers les pages Notion les plus pertinentes, ce qui nous permet de consacrer notre temps à des tâches qui apportent une réelle valeur ajoutée. Ce qui nous prenait auparavant des heures de recherche dans Notion ne prend désormais que quelques minutes grâce à des requêtes en langage naturel.
Dans cet article, nous expliquerons l’architecture, les modèles IA et la configuration de l’infrastructure derrière notre système RAG maison.
Comment nous gérons les incidents chez DataDome
Chez DataDome, la gestion des incidents consiste à minimiser l’impact, à résoudre rapidement les problèmes afin de respecter nos accords de niveau de service (SLA) et à garantir une expérience client fluide. Lorsqu’un incident se produit, il est signalé dans un canal Slack dédié, où la réponse est coordonnée.
Le premier objectif dans tout incident est d’en atténuer l’impact. L’équipe documente chaque action entreprise afin de créer un calendrier clair de ce qui a été fait et à quel moment, ce qui permet de maintenir la transparence tout au long du processus.
Les incidents sont principalement le résultat de systèmes de surveillance internes, mais peuvent également être déclenchés par l’équipe d’assistance ou nos clients. La surveillance interne est essentielle pour détecter les problèmes avant qu’ils n’affectent les utilisateurs, ce qui permet une gestion proactive et réduit le risque d’impact sur les clients.
Le fonctionnement du RAG
Avant d’explorer la mise en œuvre technique, commençons par expliquer ce qu’est le RAG et pourquoi l’utiliser.
Qu’est-ce que le RAG ?
La génération augmentée par la recherche (RAG) diffère des grands modèles linguistiques autonomes (LLM) en améliorant la génération avec des données externes pertinentes, au lieu de s’appuyer uniquement sur les connaissances internes du modèle. Dans notre cas, ces données externes comprennent plus de 500 pages Notion.
Le système fonctionne en trois étapes principales :
- Recherche : la requête de l’utilisateur est transformée en vecteur et comparée à une base de données FAISS (Facebook AI Similarity Search) pré-indexée pour récupérer le contenu Notion pertinent.
- Augmentation : le contenu récupéré est ajouté à la requête originale afin de fournir un contexte supplémentaire.
- Génération : la requête combinée (question originale et contexte) est transmise à un LLM hébergé sur AWS Bedrock pour générer la réponse finale.
Pourquoi utiliser le RAG ?
Les LLM sont connus pour leurs connaissances statiques. Par exemple, les derniers modèles d’OpenAI, y compris GPT-5, sont entraînés sur des données allant jusqu’en juin 2024.
Si vous souhaitez intégrer vos propres données dans un LLM, vous avez généralement deux options :
- Réentraîner le modèle avec vos données et votre documentation internes : un processus long et coûteux qui ne s’adapte pas bien lorsque vous devez ajouter, mettre à jour ou supprimer des informations.
- Fournir manuellement du contexte dans chaque requête en incluant les informations pertinentes.
Le RAG offre une alternative évolutive et économique. Il permet d’étendre dynamiquement les connaissances d’un LLM en injectant un contexte à jour et spécifique au domaine dans chaque requête, sans avoir besoin de réentraîner le modèle.
Modèles utilisés
Comme indiqué dans la section précédente, un RAG se compose de trois éléments : un LLM, un modèle d’intégration et un magasin de vecteurs.
Dans cette section, nous nous concentrerons sur les différents choix effectués lors du développement de notre RAG interne.
LLM : DeepSeek R1 avec AWS Bedrock
Nous avons opté pour DeepSeek R1 hébergé sur AWS Bedrock. Il offre des performances compétitives dans des contextes techniques multilingues et prend en charge l’inférence à faible latence à grande échelle. La solide base du modèle en matière de texte procédural structuré le rendait particulièrement bien adapté à notre cas d’utilisation.
Au cours de la phase initiale du projet, nous avons utilisé LLama 3.1 405b en raison de notre expérience préalable avec ce modèle dans le cadre d’un autre projet, l’automatisation de la création de post-mortem : Comment DataDome a automatisé la création de Post-Mortem avec l’agent IA DomeScribe.
Modèle d’intégration : gte-multilingual-base
En ce qui concerne les intégrations, nous avons évalué les modèles du classement Hugging Face MTEB (Massive Text Embedding Benchmark) et avons sélectionné
gte-multilingual-base.
Ce modèle présente deux avantages pour notre usage :
- il permet d’utiliser de longs contextes, avec des textes allant jusqu’à 8192 tokens ;
- il supporte le multilingue, ce qui est utile car certains utilisateurs posent des questions en français même si la documentation est en anglais.
Stockage vectoriel : FAISS
Nous utilisons FAISS pour stocker et récupérer les intégrations. Il s’agit d’un logiciel open source, hautement optimisé pour la recherche approximative du plus proche voisin (ANN), qui fonctionne bien pour les bases de données en mémoire avec une surcharge opérationnelle minimale.
En ce qui concerne la quantité limitée de données à ingérer, de l’ordre de plusieurs centaines de documents, FAISS a donné des résultats prometteurs en termes d’ingestion et de durée de recherche.
Les processus d’ingestion et de recherche sont exécutés en quelques millisecondes pour chaque document.
Infrastructure, sécurité et coûts
Examinons maintenant les fondements qui permettent à DomeRunner de fonctionner sans heurts. Nous allons détailler les choix d’infrastructure, les mesures de sécurité que nous avons mises en place et la manière dont nous avons réussi à maintenir un coût global étonnamment bas.
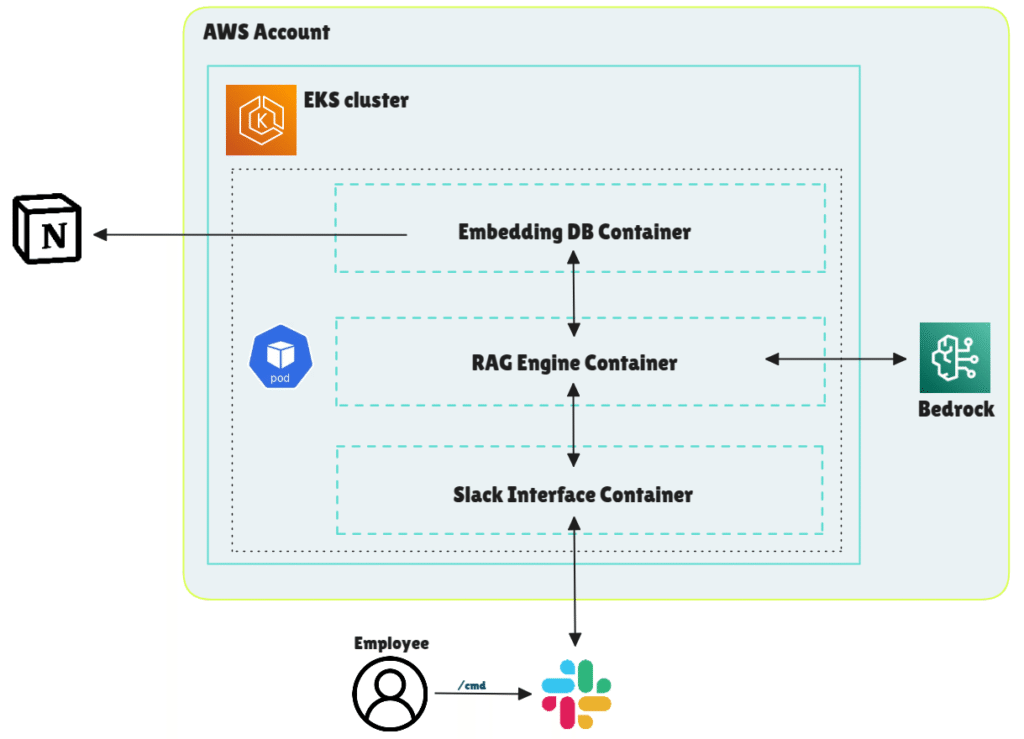
Architecture Kubernetes sur AWS EKS
L’application s’exécute dans un pod déployé sur notre cluster Kubernetes géré (EKS). Le pod contient trois conteneurs distincts :
- Conteneur d’interface Slack
- Gère les interactions avec l’API Slack
- Reçoit et répond aux interactions des utilisateurs
- Conteneur moteur RAG
- Reçoit la question de l’utilisateur et l’envoie au moteur d’embedding
- Récupère le contexte et formule le prompt
- Envoie le prompt à AWS Bedrock et retourne la réponse finale
- Conteneur base de données d’embeddings
- Contient la base FAISS avec les embeddings pré-calculés des pages Notion
- Accepte les requêtes de recherche vectorielle du conteneur RAG
Contrôles de sécurité
- Accès Slack restreint : le bot est exclusivement accessible aux membres du département technique via Slack, garantissant un contrôle strict de l’accès à l’information.
- Résidence des données : toutes les données sont traitées et stockées dans notre VPC. AWS Bedrock garantit que nos données ne seront pas utilisées pour l’entraînement des modèles ni transmises à des fournisseurs de modèles.
- Principe du moindre privilège : les rôles IAM sont limités aux permissions strictement nécessaires pour chaque conteneur, et la communication entre services est restreinte au localhost à l’intérieur du pod.
FinOps : Haute efficacité, faible coût
Malgré l’utilisation de modèles d’apprentissage automatique avancés et de l’infrastructure AWS, le projet est étonnamment abordable :
- Ressources de calcul : les trois conteneurs ont des besoins minimaux en ressources. FAISS fonctionne en mémoire avec une faible consommation CPU.
- Coût d’inférence : après calcul du nombre de tokens envoyés à AWS Bedrock, le coût est d’environ 0,01 $ par requête. Cela reste largement inférieur aux offres commerciales comparables, généralement de 20 à 25 $ par utilisateur et par mois.
Coût total de l’infrastructure ? Presque négligeable.
Sélection des documents
Chez DataDome, la grande majorité de notre documentation technique est créée à l’aide de Notion.
Une approche naïve aurait pu consister à simplement importer toutes nos pages techniques Notion dans FAISS. Cependant, une analyse des pages a révélé que beaucoup d’entre elles ne contiennent pas les informations et le contexte nécessaires pour un LLM.
Prenons l’exemple des pages sur l’état d’avancement des projets. Ces bases de données contiennent des rapports issus de réunions hebdomadaires ou bimensuelles. Les pages traitent des sujets suivants : les prochaines étapes, les défis à relever et les tâches accomplies.
Bien que ces informations puissent être précieuses, elles risquent de perturber le LLM en introduisant des informations inexactes.
Nous avons donc décidé de nous concentrer sur une base de données interne bien connue : nos procédures techniques.
Cette base de données Notion contient toutes les informations nécessaires pour :
- faire évoluer l’exploitation en production,
- créer une infrastructure,
- les meilleures pratiques ou documentation pour des outils tels qu’Atlantis ou Jenkins ;
- gérer un incident de production.
Nous avons veillé à ce que le LLM ne soit alimenté que par des informations actualisées et pertinentes en sélectionnant de manière sélective la documentation intégrée dans FAISS.
Utilisation et résultats
Maintenant que tous les éléments de notre RAG ont été décrits, voyons les résultats.
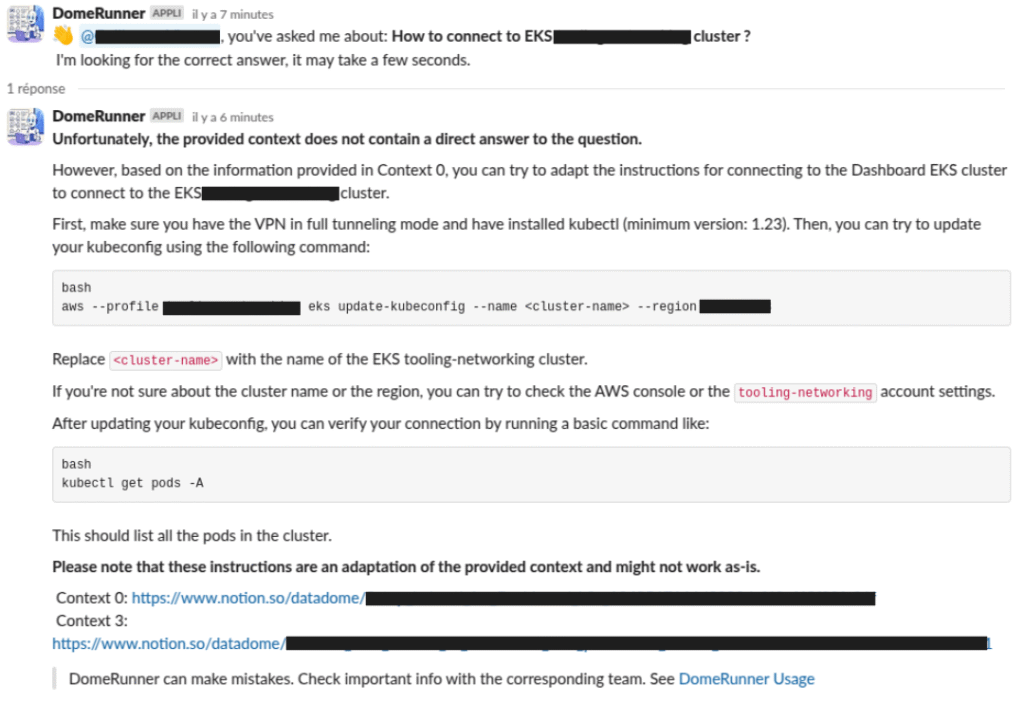
DomeRunner peut être invoqué dans un canal Slack via la commande /ask. La réponse est générée en moins d’une minute.
Actuellement, tous les messages et interactions avec DomeRunner sont visibles par l’ensemble du département technique. Cela permet d’évaluer rapidement la qualité des réponses tout en s’assurant qu’aucun utilisateur n’est trompé par des hallucinations.
Après notre benchmark interne initial, nous avons constaté que DomeRunner répond correctement à toutes les questions pour lesquelles nous disposions d’une documentation pertinente.
Points clés à retenir
Si la création d’un système RAG peut sembler nécessiter plusieurs semaines de travail, notre hackathon d’une journée a prouvé le contraire. Grâce à une infrastructure cloud moderne, des outils open source et les bons LLM, il est tout à fait possible de créer un assistant IA interne en moins de 24 heures.
Les résultats ont été étonnamment bons pour un projet aussi court, avec des réponses précises chaque fois que le contexte était correct. Il aide déjà plusieurs collègues dans leur travail quotidien en leur faisant gagner du temps et en réduisant la charge de travail liée à la recherche dans la documentation. Il promet également de rendre l’intégration des nouveaux membres de l’équipe plus rapide et plus fluide.
L’impact sur l’efficacité opérationnelle est immédiat et le coût est minime. À mesure que nous continuons à développer le système, nous sommes convaincus qu’il deviendra un élément clé de notre écosystème d’outils internes.
Si votre équipe passe beaucoup de temps à gérer ou à parcourir la documentation, un assistant RAG basé sur Slack pourrait être un ajout puissant à votre flux de travail.

Articles liés

Libération utilise DataDome + Arc XP pour neutraliser le scraping IA malveillant en moins de 2 millisecondes
En savoir plus

Comment les éditeurs de navigateurs rendent discrètement l'automatisation plus difficile à détecter
En savoir plus

Comment les agents IA "By for Me" bloquent les stocks avant même que les clients puissent finaliser leur commande
En savoir plus

Salles d'attente virtuelles : la faille que les bots exploitent
En savoir plus

