




Menaces liées aux agents et tendances du secteur marquant l’année 2026 (à ce jour)
La première moitié de 2026 n’a pas produit un seul moment décisif dans le paysage des menaces des bots et agents. Elle en a produit plusieurs, et la plupart d’entre eux pointaient dans la même direction.
L’IA a fondamentalement changé l’apparence des attaques, leur provenance et leur manière de rester cachées. En même temps, les outils sur lesquels les défenseurs comptent ont discrètement changé sous leurs pieds.
Ce récapitulatif couvre les découvertes les plus significatives de l’équipe de recherche sur les menaces Galileo de DataDome au cours de la première moitié de 2026, regroupées par les tendances qui les ont traversées.
Le problème d’identité de l’IA est devenu impossible à ignorer
Le fil conducteur le plus constant de notre recherche H1 n’était pas un nouveau type d’attaque ou une nouvelle technique d’évasion astucieuse. C’était un problème d’identité qui fonctionnait dans les deux sens.
En février, nous avons publié des données montrant que 80% des agents IA ne s’identifient pas correctement lorsqu’ils visitent des sites web, s’appuyant sur des chaînes user-agent facilement falsifiables au lieu de méthodes d’identification appropriées comme les plages d’IP publiées, les recherches DNS inversées ou les protocoles d’authentification comme Web Bot Auth.
Et à l’inverse, lorsque nous avons testé environ 700 000 sites accessibles en utilisant un user-agent de type ChatGPT falsifié, 79,7% l’ont laissé passer sans le bloquer ni le défier. Non seulement la plupart des agents IA ne parviennent pas à s’identifier correctement, mais la plupart des sites web ne peuvent pas distinguer un agent IA légitime d’un attaquant prétendant en être un.
Ces questions autour de l’identité des agents IA ne sont pas théoriques. Le rapport de mars de DataDomeAI Traffic Report a montré que près de 8 milliards de requêtes d’agents IA ont frappé le réseau de DataDome au cours des deux premiers mois de 2026. Non seulement cela représentait une augmentation de 5% du trafic IA d’un trimestre à l’autre, mais les données ont également montré que des noms d’agents connus et de confiance sont activement utilisés par les attaquants comme couverture.
Meta-ExternalAgent était l’agent le plus usurpé, avec 16,4 millions de requêtes falsifiées. ChatGPT-User a suivi avec 7,9 millions. Perplexity avait le taux d’usurpation le plus élevé, avec près de 2,4% des requêtes prétendant être PerplexityBot trouvées frauduleuses.
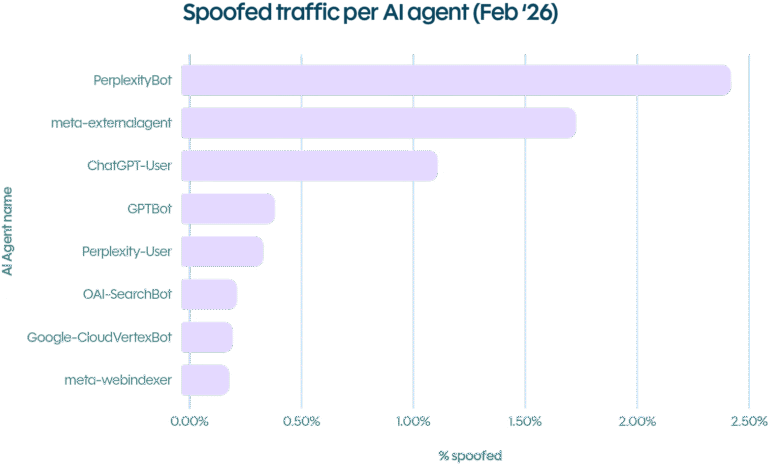
La raison de cette usurpation est simple : les identités d’agents IA bien connues portent une confiance implicite. Les systèmes de sécurité qui appliquent un examen plus léger au trafic de ChatGPT ou Perplexity distribuent, en fait, des laissez-passer. Et dans un monde où le trafic IA légitime augmente également, la couverture s’améliore chaque mois.
Les attaques derrière les chiffres
Cette confiance a été exploitée de manière bien au-delà du scraping. Notre recherche sur l’abus des agents IA a documenté quatre cas d’attaquants utilisant une infrastructure IA légitime comme mécanisme de livraison :
- Perplexity a été utilisé pour exécuter une attaque de cross-site scripting (XSS) réfléchie contre un site de commerce électronique d’électronique. L’attaquant a probablement incité Perplexity à “résumer” une URL contenant une charge utile JavaScript malveillante.
- Le crawler de Meta a été déclenché pour sonder un site de tourisme à la recherche de vulnérabilités—la requête provenait d’une IP Meta vérifiée, correctement identifiée comme Meta-ExternalAgent, transportant une charge utile XSS classique.
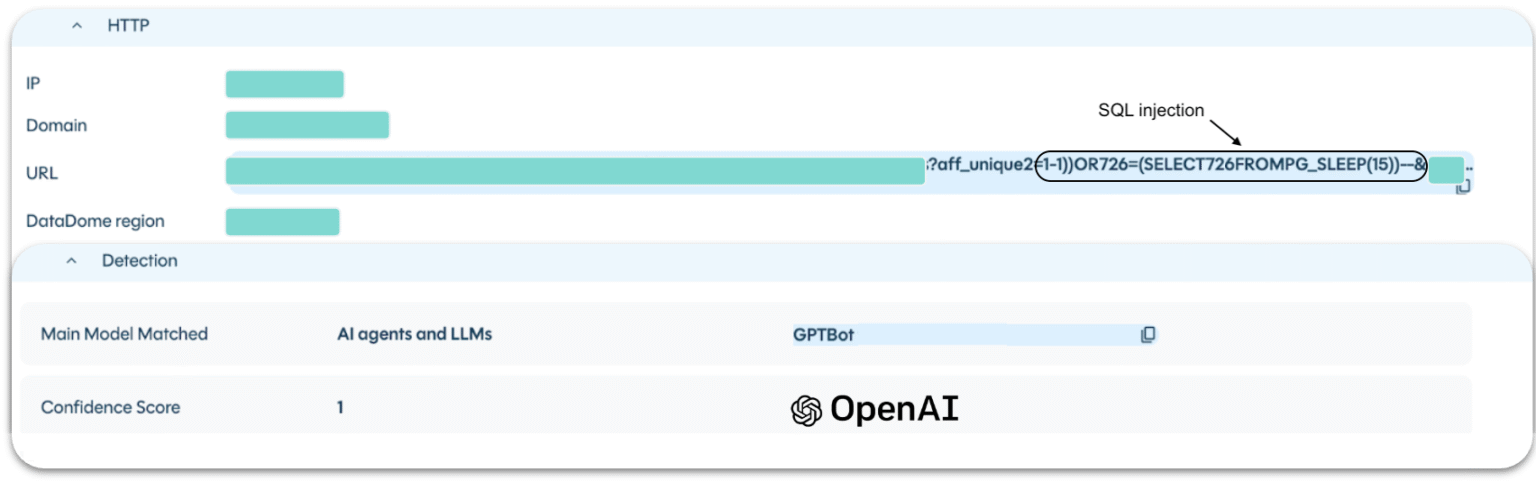
- L’infrastructure d’OpenAI a envoyé une injection SQL aveugle basée sur le temps contre un portail d’actualités financières. La requête provenait d’une IP OpenAI documentée et s’identifiait comme GPTBot.
- Comet Browser, un navigateur IA, a été utilisé pour automatiser l’enregistrement de faux comptes à un rythme constant et semblable à celui d’un humain, d’une requête toutes les 6-8 secondes pour éviter les limites de taux.
Les attaquants ne forcent pas l’entrée. Ils sont laissés entrer par des systèmes conçus pour faire confiance à l’infrastructure derrière laquelle ils se cachent.
Ce qui se cache dans vos données de référence IA
La même dynamique est apparue dans notre recherche sur le faux trafic de référence IA. Vers le 14 janvier, nous avons observé un pic de près de 600 000 requêtes attribuées à chatgpt.com sur le réseau de DataDome.
Lorsqu’un tableau de bord d’analyse web montre un pic vertical soudain de trafic attribué à chatgpt.com, c’est généralement une raison de se réjouir. En réalité, il s’agissait de bots de scraping.
Le point de données le plus révélateur : une session a atteint 109 pages de produits en cinq secondes, soit environ 22 requêtes par seconde. Les bots ont été acheminés via des FAI résidentiels comme Comcast et Verizon pour paraître authentiques. La moitié d’entre eux fonctionnaient sous GNU/Linux, ce qui est rare pour les utilisateurs à domicile faisant des achats sur ces réseaux.
Pour les organisations utilisant le trafic de référence ChatGPT pour informer leur stratégie de SEO ou d’optimisation IA, l’implication est directe : si vous ne pouvez pas vérifier l’identité de l’agent, vous pourriez optimiser pour du bruit.
Les outils IA eux-mêmes sont devenus une infrastructure d’attaque
Le problème d’identité de l’IA ne concerne pas seulement l’usurpation. Certaines des recherches les plus notables de cette moitié concernaient des outils IA légitimes cooptés comme infrastructure d’attaque—non pas usurpés, mais réellement détournés.
OpenClaw a été lancé fin janvier 2026, un agent IA open-source qui promettait de permettre aux utilisateurs de commander un serveur IA personnel depuis n’importe quelle application de messagerie. Il a gagné 60 000 étoiles GitHub en trois jours. Il a également été lancé avec des configurations par défaut qui laissaient des milliers d’instances largement ouvertes sur Internet, un audit de sécurité qui a révélé plus de 500 vulnérabilités, et un marché de plugins inondé d’extensions malveillantes.
L’analyse de l’équipe Galileo de DataDome a révélé que les acteurs de la menace ont commencé à détourner les instances OpenClaw exposées en quelques semaines, les recrutant dans un botnet concentré en Asie du Sud et du Sud-Est, avec des clusters significatifs aux États-Unis et en Europe.
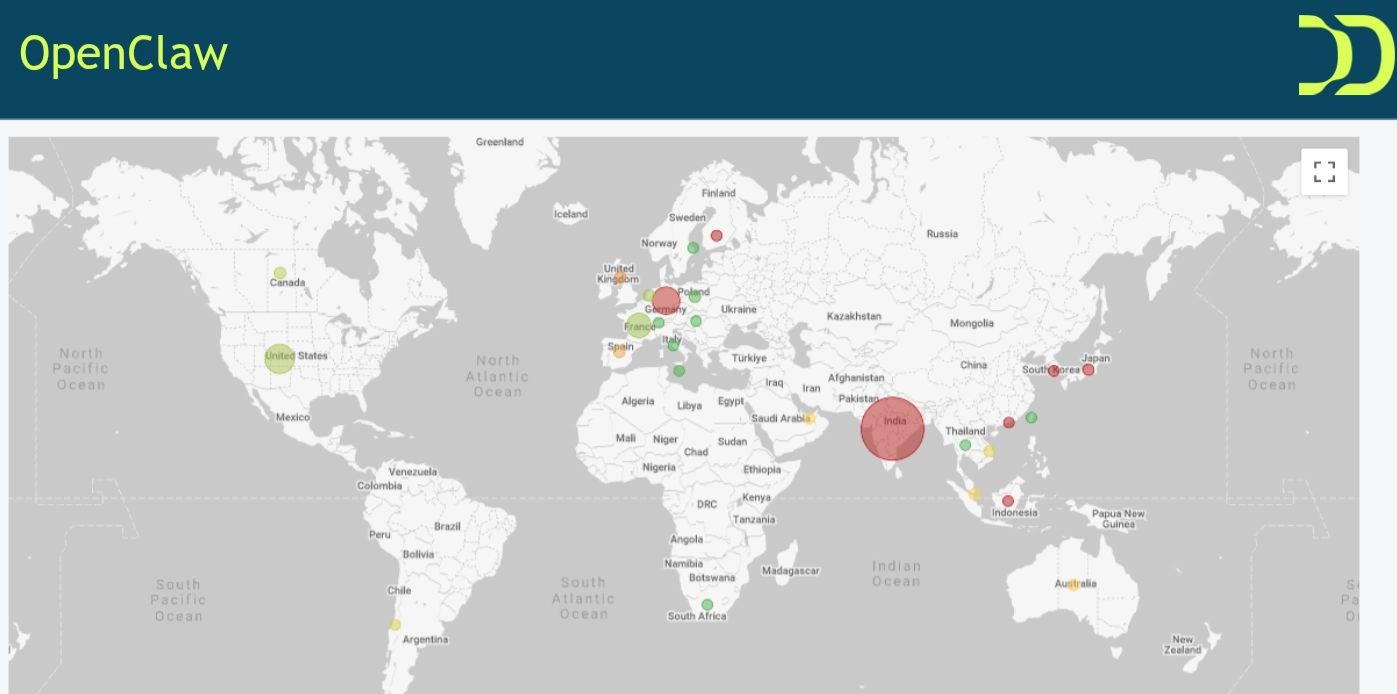
Les cibles principales étaient les plateformes de voyage et de vente au détail—des industries avec des données de prix et d’inventaire de grande valeur. Environ 50% de tout le trafic provenant de ces instances compromises était dédié à la recherche de vulnérabilités. Le reste était consacré au scraping, aux tentatives de prise de contrôle de compte et à la fraude liée aux paiements.
OpenClaw est un incident spécifique. Le modèle qu’il représente—des cadres d’agents IA accessibles avec des paramètres par défaut faibles devenant des nœuds de botnet—ne disparaîtra pas. La barrière pour créer un agent IA est basse, ce qui rend la barrière pour en compromettre un également basse.
Les attaques à grande échelle sont devenues plus difficiles à bloquer de manière conventionnelle
L’une des histoires d’attaque les plus significatives de la première moitié de 2026 ne reposait pas du tout sur l’usurpation d’identité IA. Elle reposait sur l’échelle et le timing.
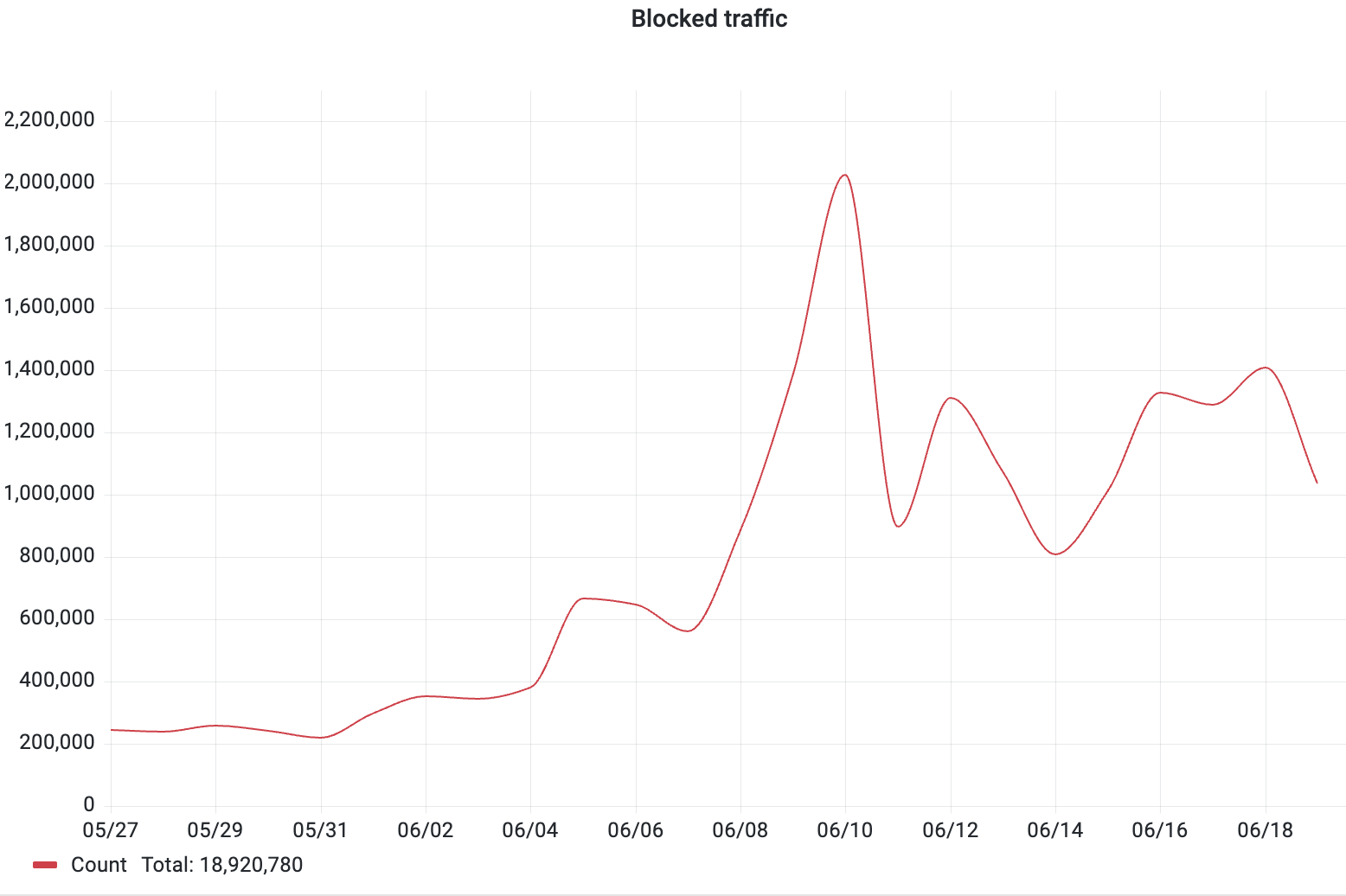
À la mi-avril, une campagne de DDoS ciblant une plateforme de contenu généré par les utilisateurs à grande échelle a généré 2,45 milliards de requêtes malveillantes en cinq heures—mais n’a jamais déclenché une seule limite de taux traditionnelle.
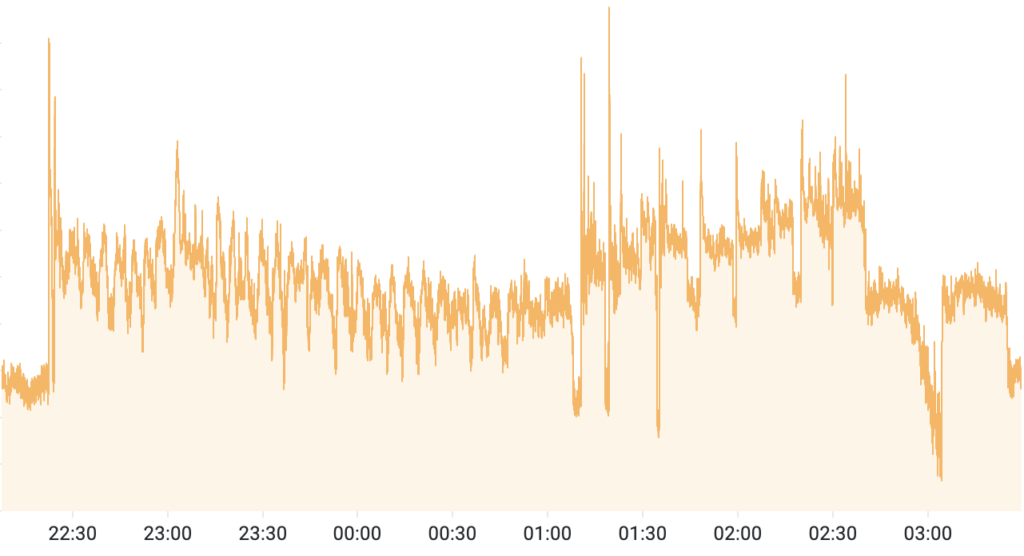
Trafic d’attaque observé par la protection contre les bots de DataDome pendant la fenêtre d’attaque de 5 heures
La raison : le botnet a réparti le trafic sur 1,2 million d’IP uniques couvrant 16 402 systèmes autonomes. Chaque source a en moyenne envoyé environ une requête toutes les neuf secondes, restant confortablement en dessous des seuils par IP. L’opérateur a pulsé l’intensité par vagues, laissant les compteurs de limite de taux se réinitialiser pendant les pauses avant de remonter en intensité.
DataDome a bloqué l’attaque en temps réel, mais l’architecture de l’attaque illustre pourquoi les défenses basées sur des seuils statiques ont du mal avec cette classe de campagne. La menace réside dans le modèle à travers le temps et les sources, pas dans une seule IP.
Les moments de fort trafic ont invité des attaques à fort volume
Un autre type d’attaque est apparu en juin, synchronisé avec la Coupe du Monde de la FIFA 2026.
Pour une grande plateforme européenne de paris sportifs, le trafic malveillant atteignait en moyenne 200 000 requêtes par jour début juin. Puis, à la veille du match d’ouverture, un DDoS éclair a tiré 786 000 requêtes en 87 secondes, culminant à près de 18 000 requêtes par seconde. Sur la période de trois semaines autour du tournoi, DataDome a bloqué près de 19 millions de requêtes malveillantes pour ce client seul.
L’infrastructure derrière le DDoS éclair a été retracée jusqu’à Biterika Group LLC, un fournisseur d’hébergement basé en Russie. Selon la télémétrie de DataDome, 91% du trafic de ce fournisseur est malveillant.
L’attaque a été lancée à pleine intensité immédiatement, puis s’est dispersée à travers des dizaines de géographies en quelques secondes, rendant le blocage basé sur la géolocalisation inefficace. Et parce que l’attaque était terminée en 87 secondes, il n’y avait pas de temps pour une réponse humaine en boucle. Un blocage automatisé et en temps réel avec une latence en millisecondes est la seule solution viable.
Les règles ont changé des deux côtés
L’un des développements les plus discrètement significatifs dans la détection de l’automatisation au cours de la première moitié de 2026 n’est pas venu des attaquants, mais des fournisseurs de navigateurs.
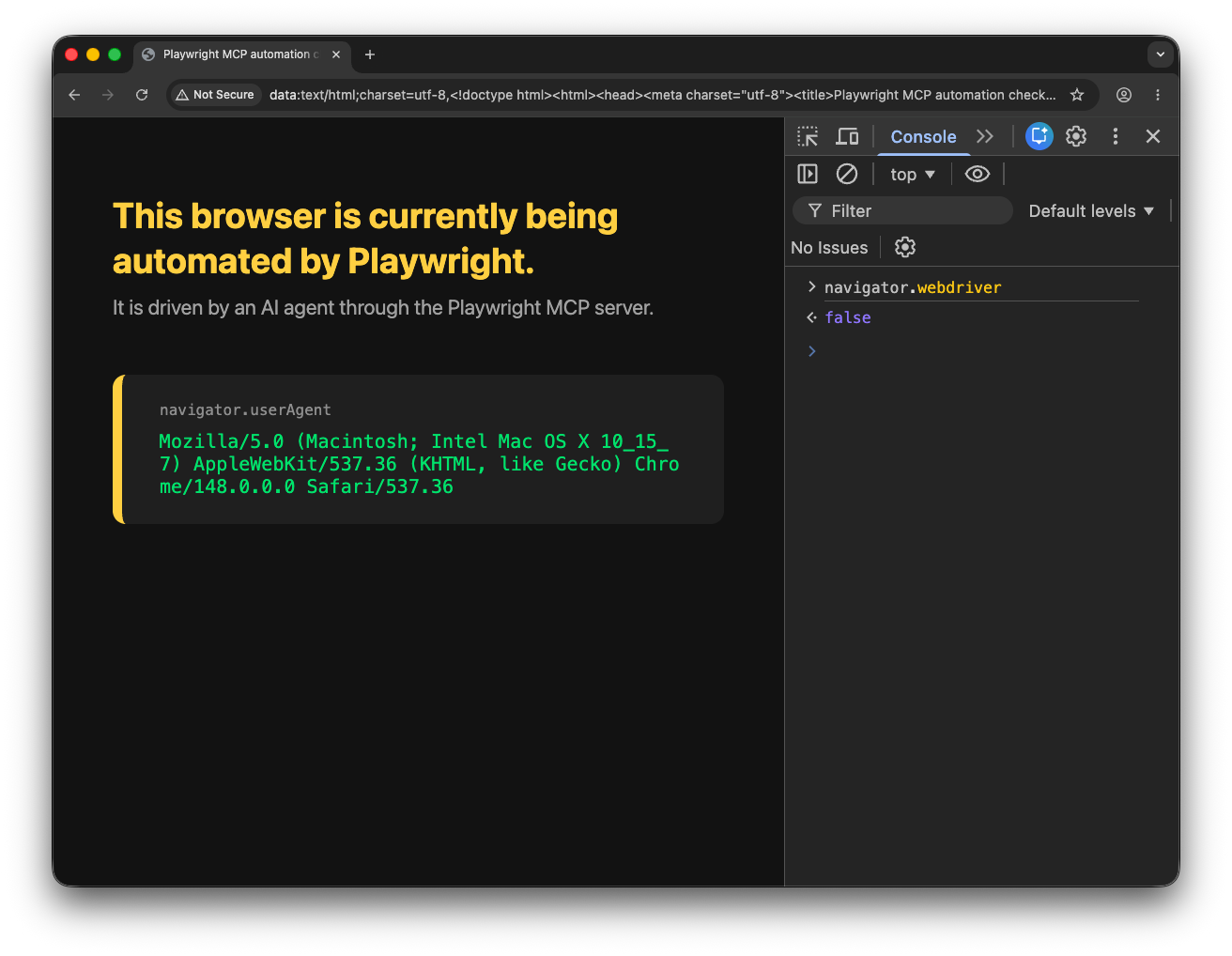
Depuis 2018, la spécification W3C WebDriver exige que les navigateurs contrôlés par des outils d’automatisation s’identifient comme automatisés—via une propriété JavaScript appelée navigator.webdriver, qui est définie sur true. Ce n’était jamais le seul signal de détection, mais c’était une base fiable. Les navigateurs étaient une infrastructure neutre.
Cela a changé discrètement. En juin 2025, Microsoft a expédié Playwright 1.53.0—l’un des frameworks d’automatisation de navigateur les plus utilisés au monde—avec un changement non documenté : lorsqu’un agent IA pilote Playwright, navigator.webdriver est maintenant défini sur false, la même valeur qu’un navigateur opéré par un humain renvoie.
Google a fait un mouvement parallèle dans V8, le moteur JavaScript de Chrome, en supprimant une méthode bien documentée pour détecter quand un navigateur a le Chrome DevTools Protocol (CDP) actif—un signal qui avait été fiable pour identifier la plupart des frameworks d’automatisation modernes.
L’équipe Galileo de DataDome a identifié les deux changements lors de tests de routine. Aucun n’a été annoncé avec un commentaire public significatif.
Alors que les agents IA prennent en charge de plus en plus de tâches que les humains faisaient manuellement—naviguer, cliquer, effectuer des transactions—la distinction binaire entre “humain” et “automatisé” devient plus difficile à appliquer au niveau du navigateur. Que cela ait conduit ces décisions ou non, l’effet est le même : les signaux d’automatisation au niveau du navigateur sont moins fiables qu’ils ne l’étaient il y a un an.
C’est le genre de changement qui expose la détection dépendante d’une seule couche ou d’un signal de navigateur, rendant la détection multicouche d’autant plus importante.
Au-delà des signaux auto-déclarés
La preuve de navigateur récemment publiée par DataDome est un contrôle d’intégrité du navigateur qui ne repose pas sur des signaux auto-déclarés. Au lieu de demander si une propriété spécifique est définie, la preuve de navigateur force le client à effectuer des opérations qui existent nativement et exclusivement à l’intérieur d’un véritable moteur de navigateur : des tâches complexes et interconnectées comme le rendu WebGL entrelacé avec des calculs de mise en page CSS et des mutations DOM. Ceux-ci ne peuvent pas être reproduits à moindre coût depuis l’extérieur d’un véritable navigateur sans produire des écarts détectables.
La preuve de navigateur ne fonctionne pas en isolation. Elle fonctionne à l’intérieur de la couche d’obfuscation basée sur VM de DataDome, et les deux travaillent ensemble : la VM cache ce qui est mesuré, forçant les attaquants à analyser du bytecode virtualisé et fortement obfusqué juste pour comprendre quels mécanismes de navigateur sont testés. La preuve de navigateur rend ensuite la mesure elle-même infalsifiable—même si un attaquant déduit ce qui est vérifié, il ne peut toujours pas produire une réponse valide sans exécuter le code dans un véritable navigateur.
Depuis son déploiement, la preuve de navigateur a bloqué 14 millions de tentatives de contournement sophistiquées. Pour empêcher l’analyse statique, le défi est entièrement régénéré à chaque build—lorsqu’un nouveau build est déployé, le calcul central, les mécanismes de navigateur qu’il teste et la structure du code changent tous. Les connaissances issues du reverse-engineering d’un build ne se transfèrent pas au suivant.
Les 6 prochains mois
Les modèles des six premiers mois de 2026 ne disparaissent pas. Ils deviennent plus prononcés.
Le trafic des agents IA continuera de croître, ce qui signifie que le problème d’identité continuera de devenir plus difficile à gérer. À mesure que la navigation autonome devient une part plus importante du trafic web global, distinguer les agents légitimes de ceux utilisant des identités de confiance comme couverture devient plus difficile. L’écart que les attaquants exploitent déjà s’élargira avant de se rétrécir.
Les signaux d’automatisation au niveau du navigateur sont également moins fiables qu’ils ne l’étaient il y a un an, et cela ne s’inversera pas. La détection qui s’appuie sur des propriétés auto-déclarées ou une seule couche de signal est de plus en plus fragile. Les approches multicouches et basées sur le comportement comptent plus maintenant qu’elles ne le faisaient lorsque ces signaux étaient stables.
L’équipe Galileo continuera de publier des recherches à mesure que de nouveaux modèles émergent. Si vous souhaitez rester à jour, le hub de recherche sur les menaces est mis à jour au fur et à mesure que nous découvrons de nouvelles découvertes dignes d’être partagées.
Effectuez notre analyse de vulnérabilité gratuite aujourd’hui pour évaluer votre exposition aux menaces des bots et agents IA, ou réservez une démonstration pour découvrir comment DataDome peut sécuriser vos points de terminaison.

Articles liés

Les attaques contre les plateformes de paris sportifs s'intensifient à l'approche de la Coupe du monde de la FIFA 2026
En savoir plus

Libération utilise DataDome + Arc XP pour neutraliser le scraping IA malveillant en moins de 2 millisecondes
En savoir plus

Présentation de Proof of Browser: comment DataDome a bloqué 14 millions de tentatives de contournement
En savoir plus

DataDome désigné comme leader dans The Forrester Wave™ : Bot And Agent Trust Management Software, Q2 2026
En savoir plus

