




The Agentic Threats & Industry Trends Defining 2026 (So Far)
The first half of 2026 didn’t produce a single defining moment in the bot and agent threat landscape. It produced several, and most of them pointed in the same direction.
AI fundamentally changed what attacks look like, where they come from, and how they try to stay hidden. At the same time, the tools defenders rely on quietly shifted under their feet.
This recap covers the most significant findings from DataDome’s Galileo threat research team across the first half of 2026, grouped by the trends that ran through them.
The AI identity problem became impossible to ignore
The most consistent thread across our H1 research wasn’t a new attack type or a clever new evasion technique. It was an identity problem that ran in both directions.
In February, we published data showing that 80% of AI agents don’t properly identify themselves when visiting websites, relying on easily spoofed user-agent strings instead of proper identification methods like published IP ranges, reverse DNS lookups, or authentication protocols like Web Bot Auth.
And on the flip side, when we tested roughly 700,000 reachable sites using a spoofed ChatGPT-style user-agent, 79.7% let it through without blocking or challenging it. Not only do most AI agents fail to properly identify themselves, but most websites can’t tell a legitimate AI agent from an attacker pretending to be one.
These questions around AI agent identity aren’t theoretical. DataDome’s March AI Traffic Report showed that nearly 8 billion AI agent requests hit DataDome’s network in just the first two months of 2026. Not only did this represent a 5% increase in AI traffic quarter over quarter, but the data also showed that known, trusted agent names are actively being used by attackers as cover.
Meta-ExternalAgent was the most impersonated agent, with 16.4 million spoofed requests. ChatGPT-User followed at 7.9 million. Perplexity had the highest impersonation rate, with nearly 2.4% of requests claiming to be PerplexityBot found to be fraudulent.
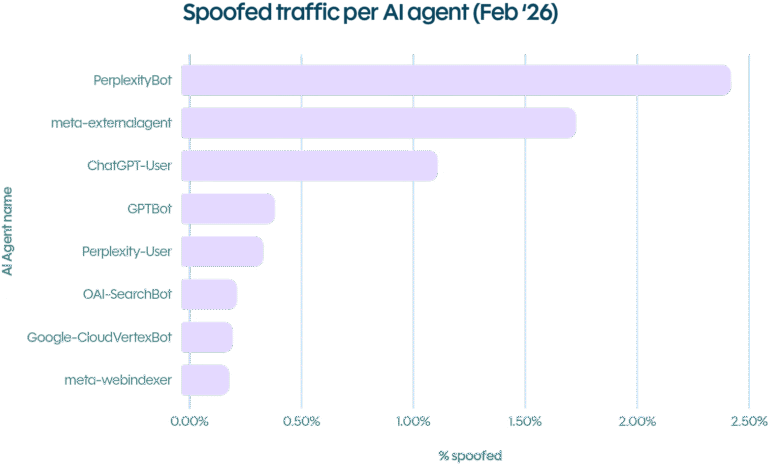
The reason for this spoofing is straightforward: well-known AI agent identities carry implicit trust. Security systems that apply lighter scrutiny to traffic from ChatGPT or Perplexity are, in effect, handing out hall passes. And in a world where the legitimate AI traffic is also growing, the cover gets better every month.
The attacks behind the numbers
That trust was exploited in ways that went well beyond scraping. Our AI agent abuse research documented four cases of attackers using legitimate AI infrastructure as a delivery mechanism:
- Perplexity was used to execute a reflected cross-site scripting (XSS) attack against an electronics e-commerce site. The attacker likely prompted Perplexity to “summarize” a URL containing a malicious JavaScript payload.
- Meta’s crawler was triggered to probe a tourism site for vulnerabilities—the request came from a verified Meta IP, correctly identified as Meta-ExternalAgent, carrying a textbook XSS payload.
- OpenAI’s infrastructure sent a time-based blind SQL injection against a financial news portal. The request originated from a documented OpenAI IP and identified itself as GPTBot.
- Comet Browser, an AI browser, was used to automate fake account registration at a steady, human-like pace of one request every 6-8 seconds to avoid rate limits.
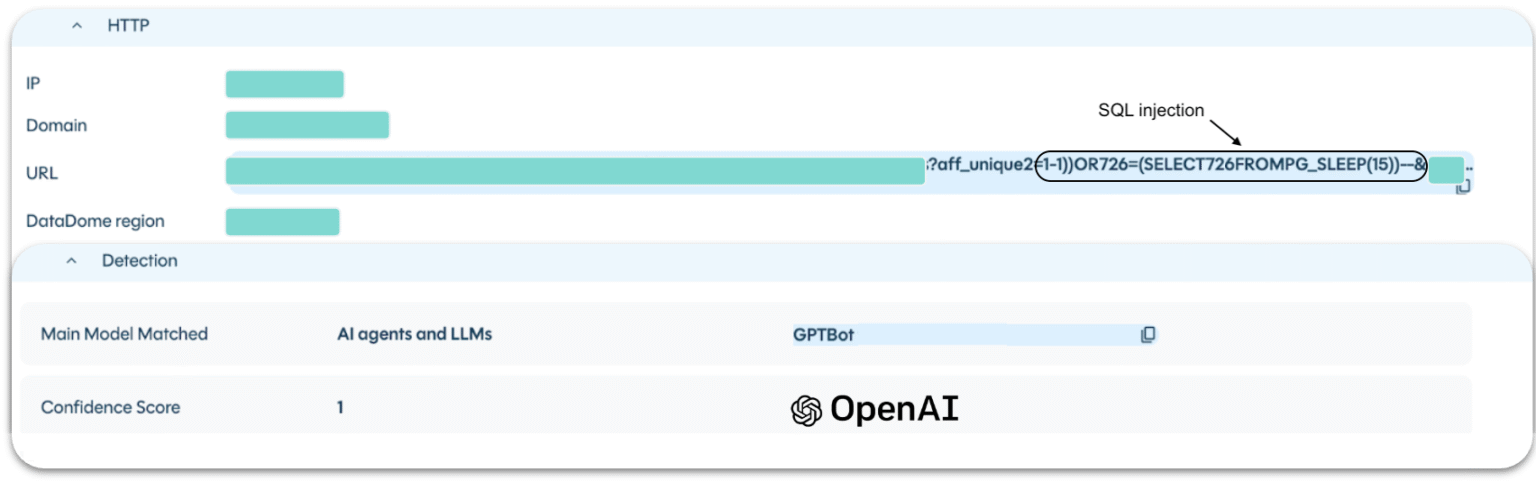
Attackers aren’t breaking in. They’re being let in by systems designed to trust the infrastructure they’re hiding behind.
What’s hiding in your AI referral data
The same dynamic surfaced in our research on fake AI referral traffic. Around January 14, we observed a spike of nearly 600,000 requests attributed to chatgpt.com across DataDome’s network.
When a web analytics dashboard shows a sudden vertical spike in traffic attributed to chatgpt.com, it is usually cause for celebration. In reality, they were scraping bots.
The most revealing data point: one session hit 109 product pages in five seconds, or roughly 22 requests per second. The bots routed through residential ISPs like Comcast and Verizon to look authentic. Half of them ran GNU/Linux, which is uncommon for home users shopping on those networks.
For organizations using ChatGPT referral traffic to inform SEO or AI optimization strategy, the implication is direct: if you can’t verify agent identity, you may be optimizing for noise.
AI tools themselves became attack infrastructure
The AI identity problem isn’t only about spoofing. Some of the most notable research this half involved legitimate AI tools being co-opted as attack infrastructure—not impersonated, but actually hijacked.
OpenClaw launched in late January 2026, an open-source AI agent that promised to let users command a personal AI server from any messaging app. It gained 60,000 GitHub stars in three days. It also launched with default configurations that left thousands of instances wide open on the internet, a security audit that turned up over 500 vulnerabilities, and a plugin marketplace flooding with malicious extensions.
Our Galileo team’s analysis found that threat actors began hijacking exposed OpenClaw instances within weeks, recruiting them into a botnet concentrated in South and Southeast Asia, with significant clusters in the US and Europe.
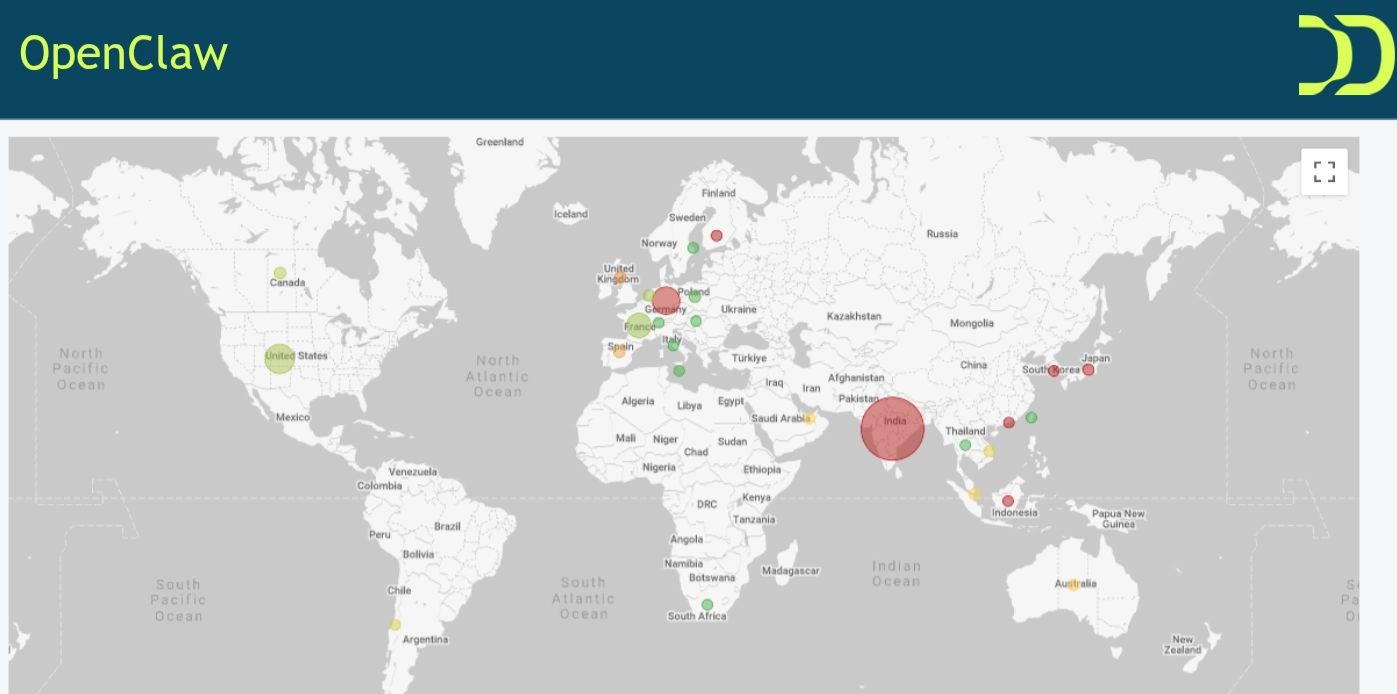
The primary targets were travel and retail platforms—industries with high-value pricing and inventory data. About 50% of all traffic from these compromised instances was dedicated to vulnerability scanning. The rest went to scraping, account takeover attempts, and payment-related fraud.
OpenClaw is a specific incident. The pattern it represents—accessible AI agent frameworks with weak defaults becoming botnet nodes—isn’t going away. The barrier to spinning up an AI agent is low, which makes the barrier to compromising one low too.
Large-scale attacks got harder to block the conventional way
One of the most significant attack stories from the first half of 2026 didn’t rely on AI impersonation at all. It relied on scale and timing.
In mid-April, a DDoS campaign targeting a large-scale user-generated content platform generated 2.45 billion malicious requests in five hours—but never triggered a single traditional rate limit.
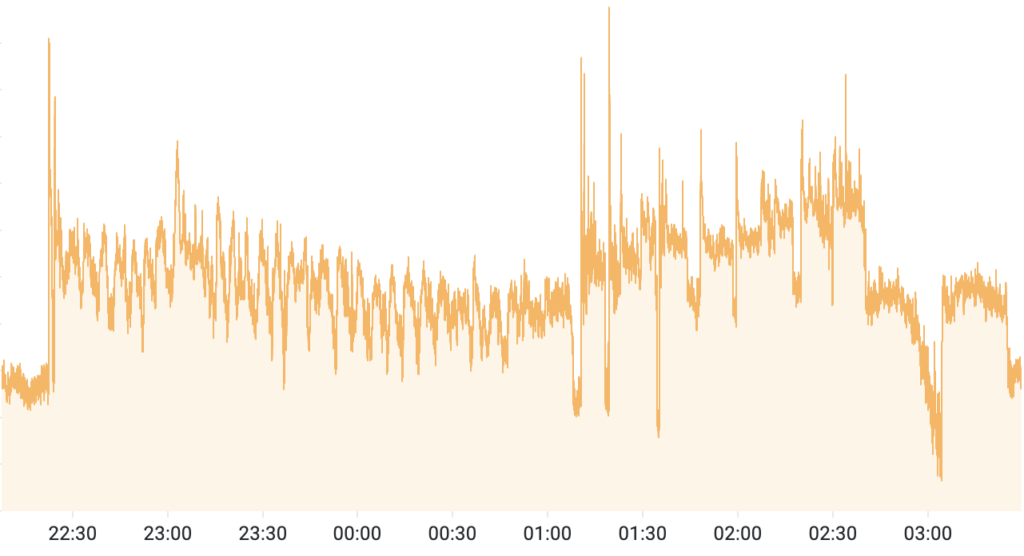
Attack traffic observed by DataDome’s bot protection across the 5-hour attack window
The reason: the botnet spread traffic across 1.2 million unique IPs spanning 16,402 autonomous systems. Each source averaged roughly one request every nine seconds, staying comfortably below per-IP thresholds. The operator pulsed intensity in waves, letting rate-limit counters reset during pauses before ramping back up.
DataDome blocked the attack in real time, but the architecture of the attack illustrates why static threshold-based defenses struggle with this class of campaign. The threat lives in the pattern across time and sources, not in any single IP.
High-traffic moments invited high-volume attacks
A different kind of attack showed up in June, timed to the 2026 FIFA World Cup.
For one major European sports-betting platform, malicious traffic was averaging 200,000 requests per day in early June. Then, on the eve of the opening match, a flash DDoS fired 786,000 requests in 87 seconds, peaking at nearly 18,000 requests per second. Over the three-week window around the tournament, DataDome blocked nearly 19 million malicious requests for this customer alone.
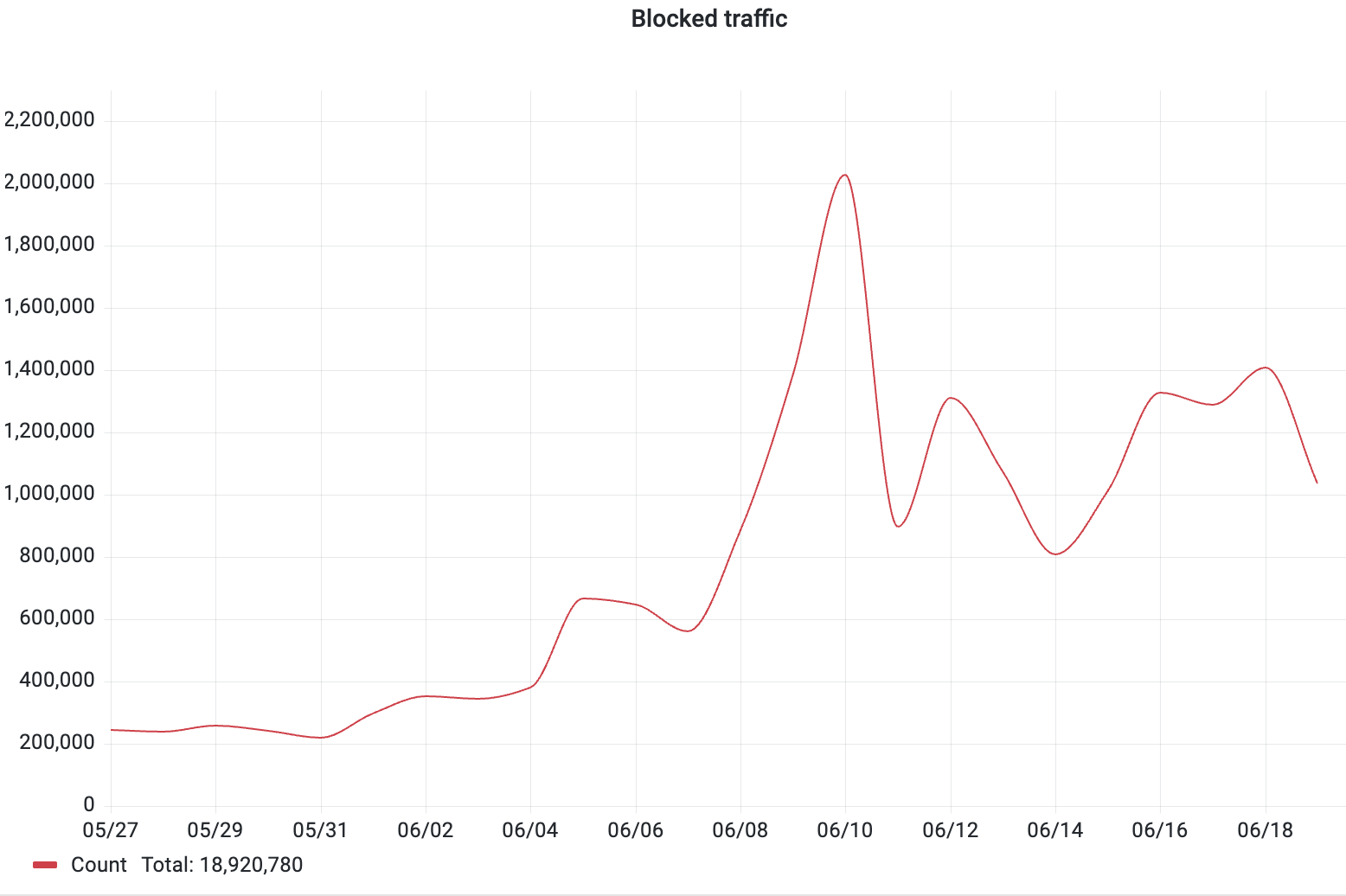
The infrastructure behind the flash DDoS traced back to Biterika Group LLC, a Russia-based hosting provider. According to DataDome telemetry, 91% of traffic from this provider is malicious.
The attack fired at full intensity immediately, then dispersed across dozens of geographies within seconds, making geo-based blocking ineffective. And because the attack was over in 87 seconds, there was no time for a human-in-the-loop response. Automated, real-time blocking at millisecond latency is the only viable solution.
The rules changed on both sides
One of the more quietly significant developments in automation detection in the first half of 2026 came not from attackers, but from browser vendors.
Since 2018, the W3C WebDriver specification has required browsers controlled by automation tools to identify themselves as automated—via a JavaScript property called navigator.webdriver, which gets set to true. It was never the only detection signal, but it was a reliable baseline. Browsers were neutral infrastructure.
That changed quietly. In June 2025, Microsoft shipped Playwright 1.53.0—one of the world’s most widely used browser automation frameworks—with an undocumented change: when an AI agent drives Playwright, navigator.webdriver is now set to false, the same value a human-operated browser returns.
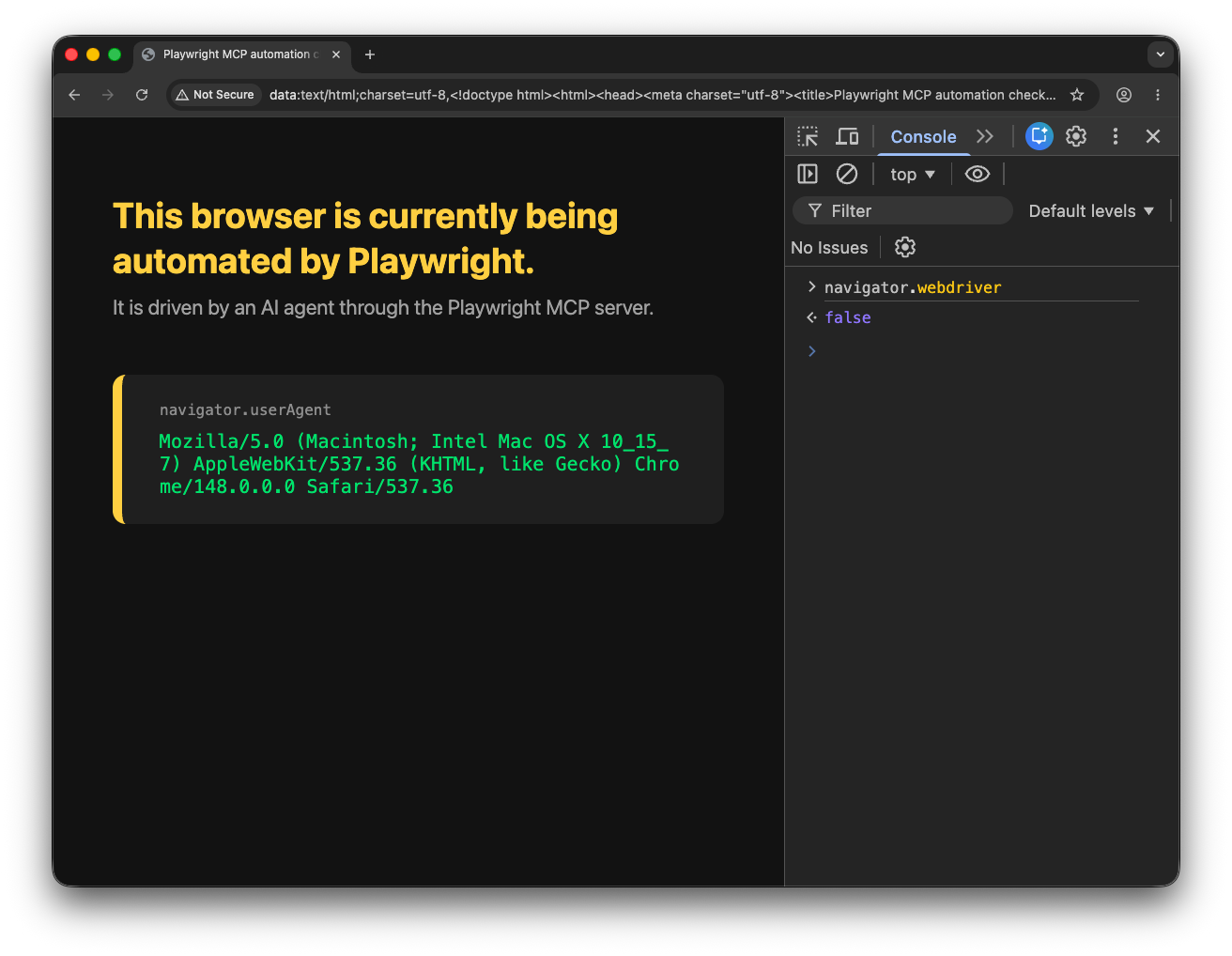
Google made a parallel move in V8, Chrome’s JavaScript engine, patching out a well-documented method for detecting when a browser has the Chrome DevTools Protocol (CDP) active—a signal that had been reliable for identifying most modern automation frameworks.
DataDome’s Galileo team identified both changes during routine testing. Neither was announced with significant public commentary.
As AI agents take on more of what humans used to do manually—browsing, clicking, completing transactions—the binary distinction between “human” and “automated” is becoming harder to enforce at the browser level. Whether that drove these decisions or not, the effect is the same: browser-level automation signals are less reliable than they were a year ago.
This is the kind of shift that exposes single-layer or browser-signal-dependent detection, making multilayered detection all the more important.
Beyond self-reported signals
DataDome’s recently released proof of browser is a browser integrity check that doesn’t rely on self-reported signals. Instead of asking whether a specific property is set, proof of browser forces the client to perform operations that exist natively and exclusively inside a real browser engine: complex, interlocking tasks like WebGL rendering intertwined with CSS layout calculations and DOM mutations. These can’t be cheaply replicated from outside a real browser without producing detectable discrepancies.
Proof of browser doesn’t operate in isolation. It runs inside DataDome’s VM-based obfuscation layer, and the two work together: the VM hides what is being measured, forcing attackers to analyze heavily obfuscated, virtualized bytecode just to understand which browser mechanisms are under test. Proof of browser then makes the measurement itself unfakeable—even if an attacker deduces what’s being checked, they still can’t produce a valid response without executing the code in a real browser.
Since deployment, proof of browser has blocked 14 million sophisticated bypass attempts. To prevent static analysis, the challenge is fully regenerated on every build—when a new build deploys, the core computation, the browser mechanisms it tests, and the structure of the code all change. Knowledge from reverse-engineering one build doesn’t carry to the next.
The next 6 months
The patterns from the first six months of 2026 aren’t going away. They’re becoming more pronounced.
AI agent traffic will keep growing, which means the identity problem will continue to get more difficult to manage. As autonomous browsing becomes a larger share of overall web traffic, distinguishing legitimate agents from those using trusted identities as cover becomes more difficult. The gap that attackers are already exploiting will widen before it narrows.
Browser-level automation signals are also less reliable than they were a year ago, and that won’t reverse. Detection that leans on self-reported properties or a single signal layer is increasingly fragile. Layered, behavior-based approaches matter more now than they did when those signals were stable.
The Galileo team will keep publishing research as new patterns emerge. If you want to stay current, the threat research hub is updated as we uncover new findings worth sharing.
Run our free Vulnerability Scan today to assess your exposure to bot and AI agent threats, or book a demo to learn how DataDome can keep your endpoints secure.

Related posts

Attacks on Sports-Betting Platforms Ramp Up Amid 2026 FIFA World Cup
Tell me more

Libération Leverages DataDome + Arc XP to Neutralize Malicious AI Scraping in <2 Milliseconds
Tell me more

Introducing Proof of Browser: How DataDome Blocked 14 Million Bypass Attempts
Tell me more

The Forrester Wave™: Bot And Agent Trust Management Software, Q2 2026: Key Findings & DataDome's Recognition as a Leader
Tell me more

