




Comment détecter les attaques à l’aide de caractéristiques à gros grain ?
Chez DataDome, nous explorons les données de trafic sous différents angles pour mieux comprendre comment les bots malveillants se cachent à la vue de tous. Les caractéristiques coarse-grained, ou « à gros grain » – c’est-à-dire, des caractéristiques qui sont plus larges que d’habitude – nous aident à saisir chaque contexte de client et à détecter des attaques distribuées qui passeraient inaperçues si nous analysions uniquement des caractéristiques à grain fin, comme le trafic de session ou IP. Les attaques détectées par les caractéristiques à gros grain peuvent être utilisées par des systèmes et analystes en aval pour analyser le trafic d’attaque et le bloquer. Les techniques de remédiation des attaques seront détaillées dans des articles ultérieurs.
Techniques de détection traditionnelles
La détection des bots repose fortement sur l’analyse des requêtes HTTP enrichies, bien que d’autres signaux tels que les empreintes de navigateur et le comportement utilisateur puissent être utilisés pour détecter les bots. Vous pouvez examiner les requêtes enrichies une par une, et également analyser le comportement des attaquants en regardant des plages temporelles plus larges. Nous analysons généralement le comportement au niveau IP ou de session et calculons des agrégations sur des fenêtres temporelles, telles que le nombre de :
- requêtes,
- user-agents distincts,
- en-têtes accept-language distincts.
Lors de l’analyse au niveau de la requête individuelle, nous recherchons des incohérences dans les différents attributs. Cela permet de détecter des bots simples, mais des bots plus sophistiqués peuvent parfaitement falsifier leurs en-têtes HTTP en utilisant des bases de données d’attributs de requête cohérents. Pour détecter ces bots, nous pouvons recourir à l’IP comportementale ou à la détection basée sur la session. De cette manière, nous pouvons détecter si une IP/session est suspecte—mais cela ne permet pas de découvrir les bots qui utilisent plusieurs sessions et/ou IP, qui apparaîtraient comme des utilisateurs ne faisant que quelques requêtes par session.
Prendre du recul
Pour obtenir une vue d’ensemble, nous devons faire un zoom arrière — à la fois en termes de temps que des caractéristiques de trafic que nous analysons. Étant donné que le trafic de chaque client est unique, nous analysons le comportement au niveau du client. Cela nous permet de visualiser des caractéristiques à gros grain qui vont bien au-delà d’une IP ou d’une session particulière et de saisir plus de contexte.
Nous calculons plusieurs agrégations sur de petites fenêtres successives. La séquence de ces agrégations forme une série temporelle, où chaque point est le résultat de l’agrégation sur une fenêtre particulière.
Ensuite, nous utilisons l’analyse de séries temporelles pour détecter les attaques et identifier les caractéristiques uniques qui permettent d’identifier les attaquants.
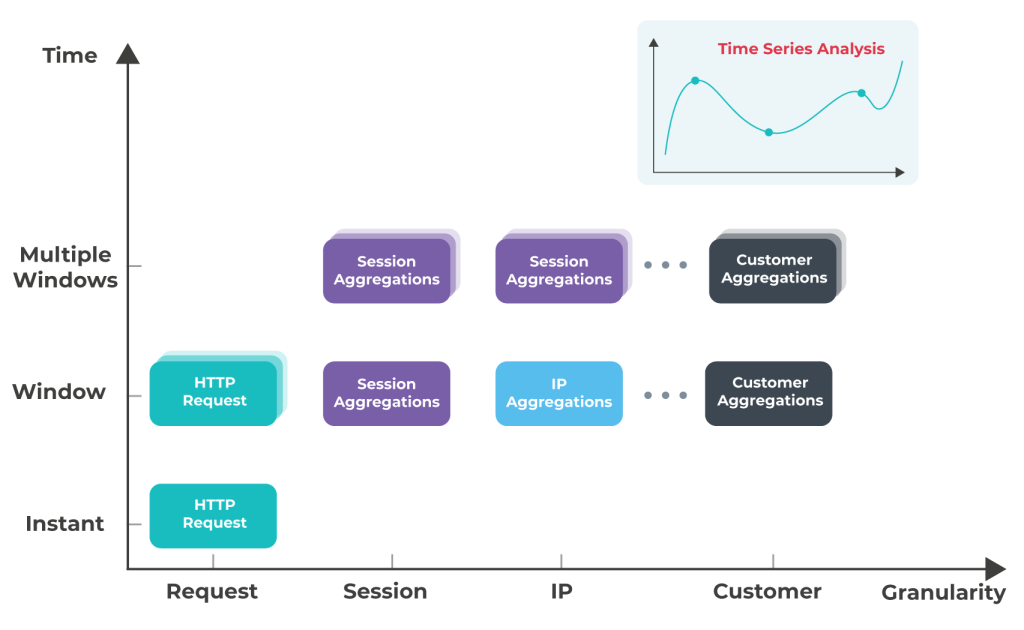
L’agrégation la plus courante que nous pouvons calculer est le nombre de requêtes. Lorsqu’elle est calculée pour des sessions ou IP, nous pouvons l’utiliser pour appliquer une détection basée sur la limitation du débit.
Cependant, le comportement ne se caractérise pas seulement par le nombre de requêtes, nous calculons donc des agrégations au niveau du client, telles que le nombre de :
- pays distincts,
- sessions distinctes,
- systèmes autonomes.
Exemples
Examinons quelques exemples qui démontrent l’efficacité des caractéristiques à gros grains.
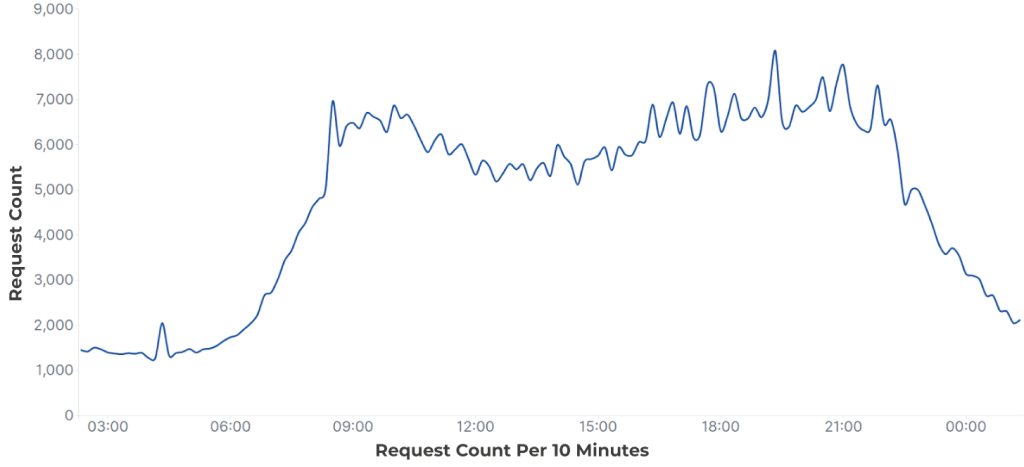
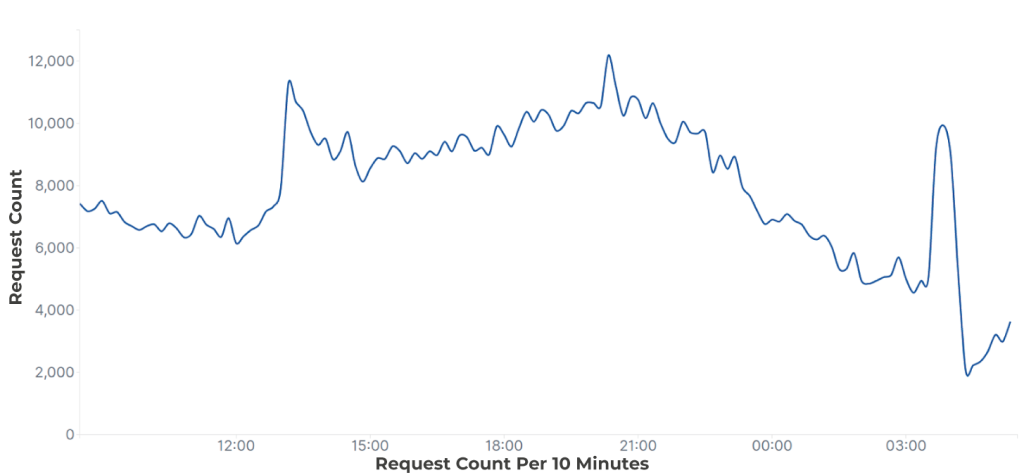
Nombre de requêtes dans une fenêtre de temps donnée :
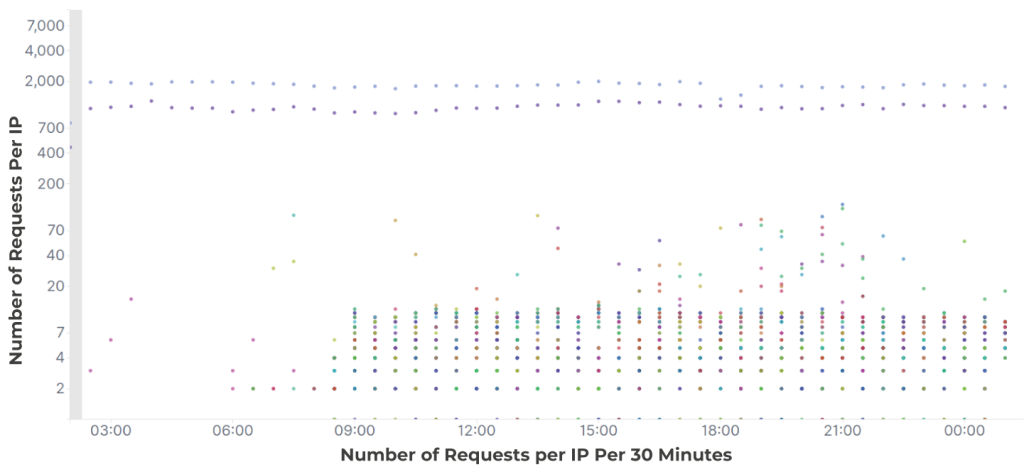
Le premier exemple est une attaque hautement distribuée. Nous pouvons observer un pic dans le trafic, mais aucun changement significatif dans le nombre de requêtes par IP. Dans de tels cas, la limitation du débit n’est pas très utile, car le comportement de chaque IP prise isolément est normal. Dans le deuxième graphique, nous pouvons voir seulement deux IP présentes avant l’attaque, puis plusieurs autres IP effectuant un très petit nombre de requêtes chacune lorsque l’attaque commence.
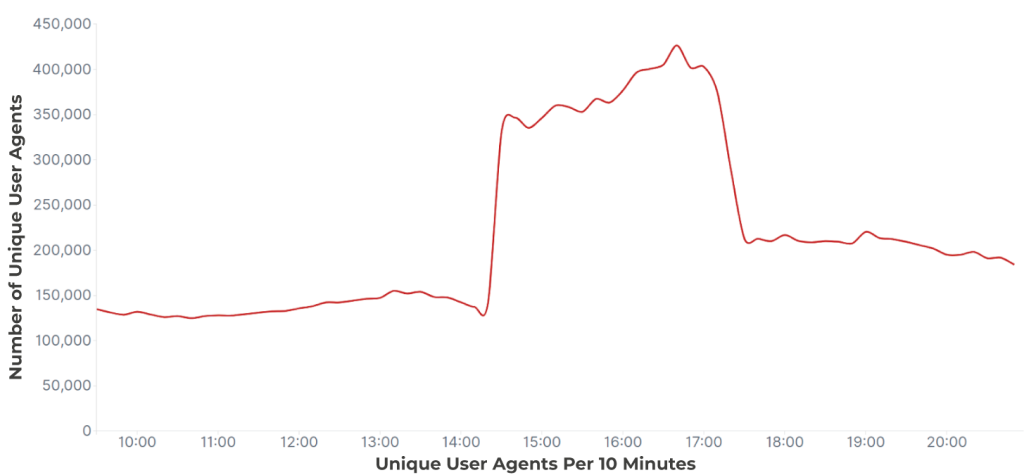
Agents utilisateurs distincts :
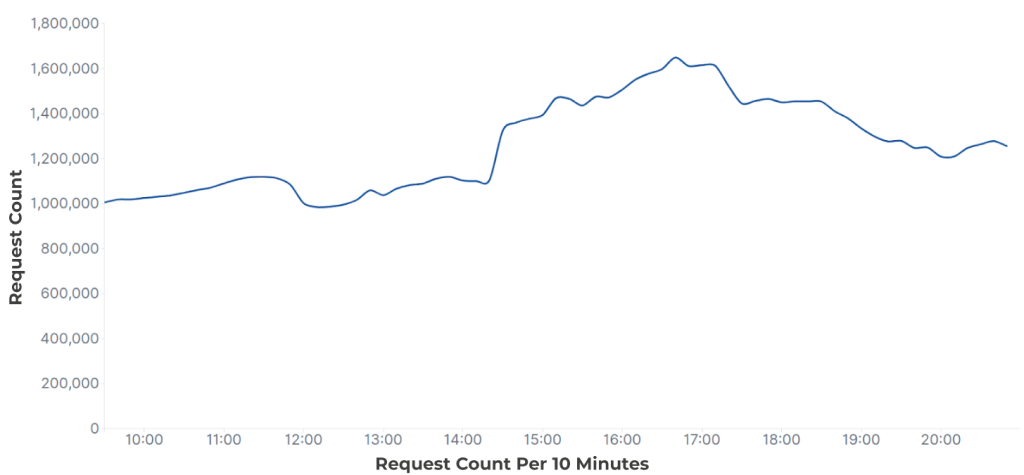
Un autre exemple est celui où il n’y a pas de pic clair dans le trafic, mais le nombre d’agents utilisateurs distincts nous permet d’identifier clairement l’attaque. Comme vous pouvez le voir ci-dessous, il y a une variation dans le nombre de requêtes qui pourrait être attribuée à des fluctuations normales. Mais l’examen de l’agent utilisateur (en rouge ci-dessous) au cours de la même période montre clairement qu’il s’agit d’une attaque.
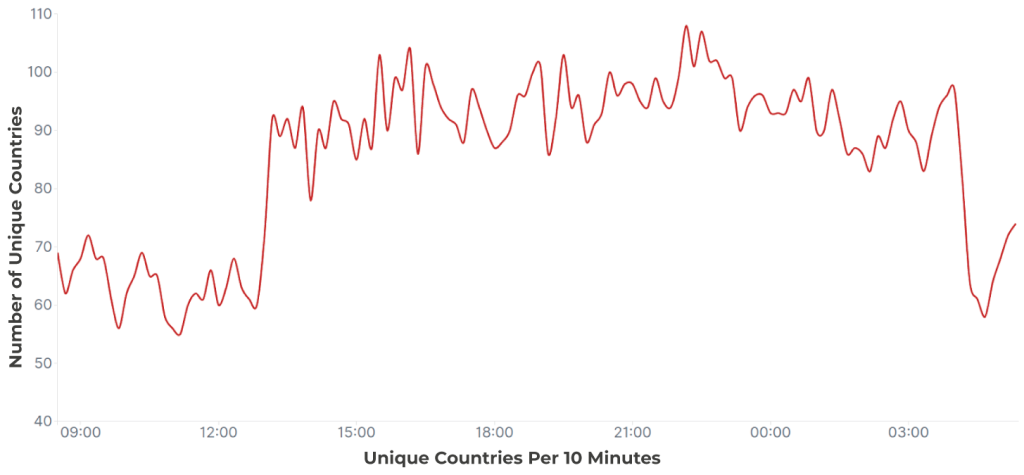
Pays distincts :
Enfin, nous avons un exemple où la caractéristique cruciale est le nombre de pays uniques. Nous pouvons observer un petit pic dans le nombre de requêtes—mais puisque le trafic fluctue, cela n’est pas toujours suffisant pour identifier l’attaque avec confiance. Cependant, on peut voir que le nombre de pays uniques présente un pic clair qui nous permet d’identifier l’attaque et de délimiter le début et la fin.
Conclusion
Bien qu’une grande partie de la détection de bots consiste à examiner les caractéristiques les plus fines de chaque requête, comme le comportement pour chaque adresse IP ou session, nous pouvons détecter des attaques plus sophistiquées en utilisant des caractéristiques à gros grain, comme le nombre de requêtes au fil du temps.
La première étape pour arrêter les bots malveillants est de les trouver, même s’ils se cachent dans un trafic « normal » — et les caractéristiques coarse-grained aident. Le puissant moteur de détection de bots de DataDome est constamment amélioré au fur et à mesure que nous analysons de nouvelles données issues d’attaques sur les sites web de nos clients.
Si vous êtes responsable de la sécurité en ligne ou de la prévention de la fraude dans votre organisation, vous devriez voir si vous pouvez repérer des bots dans vos modèles de trafic. Pour obtenir une vue d’ensemble de votre trafic et évaluer ce qui est (et n’est pas) une activité utilisateur « normale » sur votre plateforme, consultez le tableau de bord de détection de bots et de fraude en ligne de DataDome gratuit pendant 30 jours.

Articles liés

Menaces liées aux agents et tendances du secteur qui ont marqué l'année 2026 (jusqu'à présent)
En savoir plus

Les attaques contre les plateformes de paris sportifs s'intensifient à l'approche de la Coupe du monde de la FIFA 2026
En savoir plus

Présentation de Proof of Browser: comment DataDome a bloqué 14 millions de tentatives de contournement
En savoir plus

Comment les éditeurs de navigateurs rendent discrètement l'automatisation plus difficile à détecter
En savoir plus

