




Comment les nouvelles API Web AI de Chrome permettent le fingerprinting matériel
L’initiative de Google pour intégrer l’IA directement dans les navigateurs web a créé un effet secondaire inattendu : une nouvelle méthode puissante pour identifier et classer les appareils.
Google a récemment introduit de nouvelles API web qui permettent une interaction locale avec des modèles d’IA et des LLM via Gemini Nano, la variante du modèle intégré de Google au sein de la famille Gemini. Ces API permettent aux sites web de faire fonctionner des fonctionnalités d’IA – comme la synthèse de texte ou la traduction linguistique – directement sur l’appareil de l’utilisateur plutôt que d’envoyer des données aux serveurs cloud.
Cette approche réduit les coûts d’infrastructure de Google tout en empêchant les données sensibles des utilisateurs de quitter le navigateur. Un avantage pour la confidentialité et les performances.
Mais il y a un piège : ces fonctionnalités d’IA ne fonctionnent que sur du matériel haut de gamme. Et cette exigence matérielle est devenue une mine d’or pour la détection des bots.
Lorsqu’un site web vérifie si un appareil peut exécuter ces fonctionnalités d’IA, il vérifie essentiellement les capacités matérielles de l’appareil. Les bots qui falsifient leurs propriétés de navigateur prétendent souvent fonctionner sur des ordinateurs portables ou des téléphones grand public, mais leur matériel réel raconte une autre histoire. Ces nouvelles API rendent ces mensonges beaucoup plus faciles à détecter.
Plusieurs de ces API ont été introduites dans Chrome 138 :
- API de traduction: traduit le contenu généré par l’utilisateur et le contenu dynamique à la demande ;
- API de détection de langue : détecte la langue du texte d’entrée ;
- API de synthèse : condense le contenu long en résumés courts.
Les exigences matérielles créent un filtre naturel
L’API Summarizer est particulièrement intéressante du point de vue de la détection de bots. Selon la documentation de Chrome, cette API a des exigences matérielles spécifiques, ce qui signifie qu’elle ne fonctionne que sur des appareils haut de gamme.
- Système d’exploitation : Windows 10 ou 11; macOS 13+ (Ventura et suivants) ; Linux ; ou ChromeOS (à partir de la plateforme 16389.0.0 et suivants) sur les appareils Chromebook Plus. Chrome pour Android, iOS et ChromeOS sur des appareils non Chromebook Plus ne sont pas encore pris en charge par les API qui utilisent Gemini Nano.
- Stockage : au moins 22 Go d’espace libre sur le volume contenant votre profil Chrome.
- GPU ou CPU : les modèles intégrés peuvent fonctionner avec GPU ou CPU.
- GPU : strictement > 4 Go de VRAM.
- CPU : 16 Go de RAM ou +, et 4 cœurs CPU ou +.
- Remarque : l’API de prompt avec entrée audio nécessite un GPU.
- Réseau : données illimitées ou connexion non mesurée.
Qu’est-ce que cela signifie pour l’identification des appareils?
L’exécution de const availability = await Summarizer.availability(); donne l’un des plusieurs états:
- indisponible : l’appareil a moins de 4 Go de VRAM, moins de 16 Go de RAM ou moins de 4 cœurs CPU ;
- téléchargeable ou disponible : l’appareil dispose au moins de 4 Go de VRAM, ou 16 Go de RAM ou plus, et 4 cœurs CPU ou plus.
Cela nous indique que seuls les appareils grand public relativement haut de gamme pourront exécuter cette API, ce qui est déjà utile pour la segmentation du trafic. En vérifiant cette seule API, les sites web peuvent immédiatement catégoriser les appareils en niveaux de capacité.
Parce que cette fonctionnalité est actuellement exclusive à Chrome, nos analystes peuvent utiliser sa disponibilité pour isoler de manière fiable les sessions compatibles.
Le graphique ci-dessous montre que seulement 4% du trafic mondial est capable d’exécuter l’API Summarizer, 50 % ne le pouvant pas en raison de spécifications matérielles insuffisantes, et 46 % étant indéfinis.
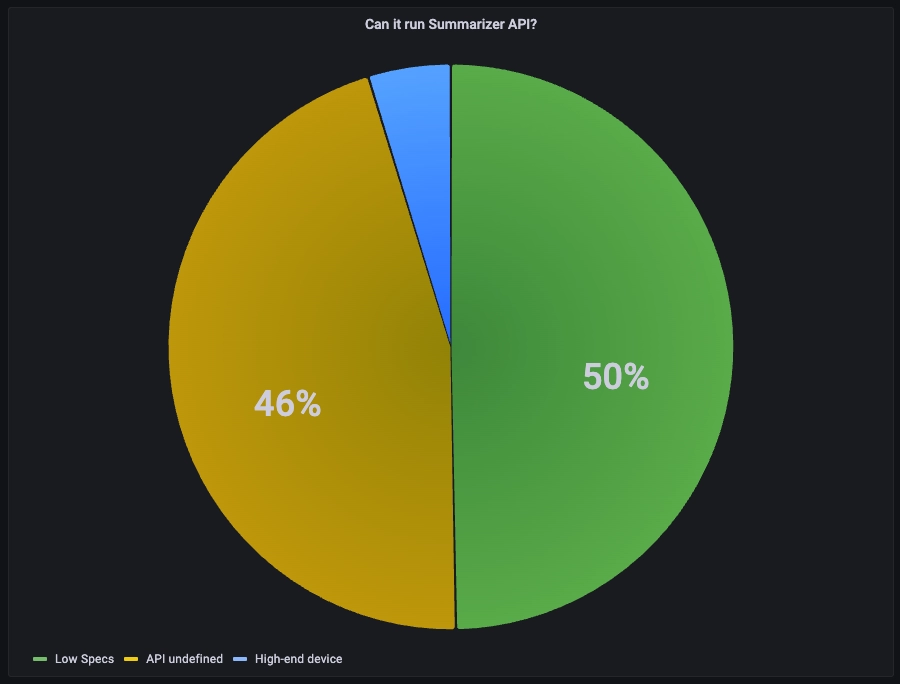
Le graphique indique que seulement 4% du trafic observé est capable d’exécuter l’API Summarizer.
Utiliser la disponibilité de l’API pour détecter les incohérences
Nous pouvons également rechercher des incohérences en comparant la disponibilité de l’API avec d’autres valeurs exposées par les propriétés d’autres API web. Par exemple :
- si navigator.hardwareConcurrency donne le nombre de processeurs logiques, et s’il est inférieur à 4 mais que la disponibilité de la synthèse indique un support, cette propriété pourrait avoir été falsifiée ;
- si canvas.getContext(‘webgl’).getExtension(‘WEBGL_debug_renderer_info’).UNMASKED_RENDERER_WEBGL suggère un MacBook récent et navigator.deviceMemory rapporte 16 Go ou plus, mais que la disponibilité de la synthèse est négative, la session peut nécessiter un examen supplémentaire.
Ces vérifications croisées rendent beaucoup plus difficile pour les bots de maintenir un profil matériel cohérent.
D’autres fuites arrivent
Une nouvelle API nommée LanguageModel est prévue pour être lancée dans Chrome 148. Encore une fois, elle semble offrir des possibilités de fingerprinting intéressantes, avec des exigences matérielles encore plus granulaires.
Cette API offre un support multimodal pour les entrées/sorties audio, image et texte.
Étant donné que ces capacités dépendent fortement des performances matérielles, vérifier la disponibilité de LanguageModel depuis JavaScript teste implicitement si l’appareil peut les prendre en charge. Chaque capacité agit comme un test de seuil pour différents niveaux de matériel.
Un examen du code source de Chromium dans components/optimization_guide/core/model_execution/performance_class.cc montre les exigences associées à chaque capacité.
- La prise en charge de l’inférence de texte nécessite soit:
bool PerformanceClassifier::IsDeviceCapable() const {
return IsDeviceGPUCapable() || on_device_model::IsCpuCapable();
}
- Un GPU avec une classe de performance d’au moins 3, 4, 5 ou 6, correspondant en pratique à environ 3 Go ou plus de VRAM
- Un CPU avec RAM ≥ 15 Go, ≥ 4 cœurs, et au moins 64 bits
- La prise en charge des images nécessite les mêmes spécifications pour l’instant
- Le support audio, en revanche, nécessite de meilleures spécifications avec une exigence GPU plus élevée : plus de 6 Go de VRAM ou le même support CPU que les autres
bool PerformanceClassifier::SupportsAudioInput() const {
// Check if the device is GPU capable and has enough VRAM.
if (IsDeviceGPUCapable() &&
base::FeatureList::IsEnabled(kOnDeviceModelGpuAudioInput)) {
uint64_t vram_mb = local_state_->GetUint64(
model_execution::prefs::localstate::kOnDeviceVramMb);
return vram_mb >=
static_cast<uint64_t>(kOnDeviceModelAudioInputVramMin.Get());
}
// Check if the device is CPU capable and the feature is enabled.
return on_device_model::IsCpuCapable() &&
base::FeatureList::IsEnabled(kOnDeviceModelCpuAudioInput);
}
Par conséquent, en fonction du résultat donné par cette API, nous pouvons déduire la classe de performance du GPU :
- aucune prise en charge : GPU avec moins de 3 Go de VRAM et CPU avec moins de 4 cœurs et <15 Go de RAM ;
- prise en charge texte & image uniquement : GPU entre 3 Go et 6 Go de VRAM et CPU avec moins de 4 cœurs et <15 Go de RAM ;
- prise en charge texte, image & audio : GPU ≥ 6 Go de VRAM ou CPU ≥ 4 cœurs et ≥ 15 Go de RAM.
Bien que cela nous donne une très bonne vue de l’architecture de l’appareil utilisateur, LanguageModel peut révéler des informations encore plus intéressantes sur le matériel sous-jacent.
Chronométrage de l’inférence : classifier les appareils selon leurs performances réelles
LanguageModel expose une méthode intéressante appelée promptStreaming, qui diffuse la réponse du modèle morceau par morceau.
Dans le contexte de l’inférence de modèle de langage local, deux métriques sont particulièrement pertinentes :
- temps jusqu’au premier jeton (TTFT) : la latence entre le moment où le prompt a été soumis et la réception du premier morceau de sortie. Cela mesure à quelle vitesse l’appareil peut traiter l’entrée ;
- débit de décodage : le taux de génération de sortie, généralement mesuré en jetons/seconde.
Les deux données sont mesurables directement depuis JavaScript en utilisant performance.now() autour du flux promptStreaming. En mesurant la vitesse réelle de l’IA, nous pouvons créer une empreinte de performance beaucoup plus difficile à falsifier que les propriétés déclaratives.
for (let i = 0; i < measureRuns; i++) {
let firstTokenTime = null;
let totalChars = 0;
const start = performance.now();
const stream = session.promptStreaming("Count from 1 to 20, one number per line.");
for await (const chunk of stream) {
if (firstTokenTime === null) firstTokenTime = performance.now() - start;
totalChars += chunk.length;
}
const totalTime = performance.now() - start;
const estimatedTokens = Math.ceil(totalChars / 4); // Approximate token count: ~4 characters per token for English
console.log(`Time to first token: ${firstTokenTime} ms`);
console.log(`Throughput: ${(estimatedTokens / (totalTime / 1000)).toFixed(1)} tokens/sec`)
}
Quelques points méritent d’être notés ici. Des passes de préchauffage sont nécessaires pour charger les poids du modèle en mémoire. De plus, le nombre de jetons est approximatif car la fonction produit des morceaux de texte, pas des jetons.
Pour un matériel donné, le débit pourrait varier en raison de la limitation thermique, des modes d’alimentation ou de la charge du système. Cependant, d’après nos mesures expérimentales, nous avons trouvé que les valeurs étaient relativement stables dans le temps.
Pour déduire une famille de matériel à partir de ces signaux, les équipes de détection de bots pourraient maintenir une structure de recherche qui associe les plages de débit et de TTFT à des clusters matériels, une technique comparable à Picasso de Google, ou aux techniques antérieures de fingerprinting par chronométrage AudioContext.
Ce qui rend cette approche particulièrement intéressante, ce n’est pas le fingerprinting parfait, mais l’augmentation des coûts pour les attaquants. Reproduire un profil d’inférence cohérent qui reste aligné avec le reste de l’empreinte du navigateur est bien plus exigeant que de modifier quelques propriétés JavaScript. Un attaquant devrait soit :
- posséder réellement le matériel qu’il prétend avoir (cher à grande échelle) ;
- simuler parfaitement les modèles de timing d’inférence de l’IA (extrêmement difficile) ;
- accepter que leurs propriétés falsifiées seront incohérentes avec les tests de performance (facilement détecté).
Cette méthode reste hautement expérimentale car les implémentations de navigateurs évoluent encore, le chronométrage reste bruyant, et les futures atténuations de confidentialité pourraient réduire sa précision. Néanmoins, elle reste une perspective intéressante dans le jeu sans fin du chat et de la souris.
Pourquoi cela compte pour la détection des bots
Pour les défenseurs, cela crée une nouvelle classe de signaux qui peuvent renforcer l’intelligence des appareils lorsqu’ils sont utilisés en combinaison avec la télémétrie existante. Contrairement à de nombreux attributs déclaratifs de navigateur, ces signaux basés sur la performance sont liés à la capacité d’exécution réelle, ce qui les rend considérablement plus coûteux à falsifier à grande échelle.
Pour les fournisseurs de navigateurs, cela soulève une question commune : combien d’informations la plateforme peut-elle exposer avant que les fonctionnalités utiles ne deviennent de l’entropie de fingerprinting ? À mesure que l’IA locale devient une fonctionnalité de navigateur de plus en plus importante, cette tension sera probablement de plus en plus difficile à ignorer.
Chez DataDome, nous surveillons en permanence les changements de navigateur pour identifier de nouvelles façons de détecter les bots, les agents IA, et de lutter contre la cyberfraude. Ces API d’IA représentent un changement significatif : au lieu de demander aux navigateurs ce qu’ils prétendent être, nous pouvons maintenant tester ce qu’ils peuvent réellement faire.
Effectuez un scan de vulnérabilité gratuit aujourd’hui pour voir si votre site web est correctement protégé contre les bots et agents d’IA malveillants, ou réservez une démo pour en savoir plus sur DataDome.

Articles liés

The Forrester Wave™: logiciel de gestion de la confiance des bots et agents, T2 2026: conclusions clés & reconnaissance de DataDome en tant que leader
En savoir plus

Comment BPX a protégé des API essentielles contre 6,6 millions d'attaques de scraping de prix
En savoir plus

Etix bloque le scalping de billets sans ralentir les vrais fans
En savoir plus

Présentation de Priority Protect : la seule salle d'attente virtuelle conçue pour l'ère agentique
En savoir plus

