




The AI Traffic Report: High Volume, Low Visibility, and a Growing Risk
AI agents are no longer a future concern. They are crawling, indexing, and interacting with websites at a scale that most organizations have not fully registered. Since the beginning of 2026, DataDome’s network has processed nearly 8 billion AI agent requests. The traffic is not slowing down; what is changing is its complexity.
This report draws on DataDome’s network data, culled from 5 trillion signals analyzed daily across 400+ enterprises, to examine the state of AI agent traffic in early 2026: where it is coming from, how much of it can be trusted, and why volume alone is a poor guide to value.
Key findings
- DataDome’s network recorded 7.9 billion AI agent requests in January and February 2026, a 5% increase QoQ.
- Known, trusted agent names are being actively used as cover. Meta-ExternalAgent was the most impersonated, followed by ChatGPT-User. PerplexityBot had the highest rate of impersonation in February 2026.
- The industries seeing the highest agentic browser traffic are the same ones sitting on the most valuable transactional data: e-commerce and retail (roughly 20% of volume), real estate (17%), and travel and tourism (15%).
- Meta ExternalAgent accounted for nearly 25% of top AI agent traffic on DataDome’s network in February 2026. ChatGPT-User followed at 19.1%, with Meta WebIndexer at 14.3%.
AI agent traffic: Volume & value
The volume is already significant. DataDome’s network recorded 7.9 billion AI agent requests in January and February 2026, a 5% increase since Q4 2025. For any organization running a website at scale, this is not edge-case traffic. For one customer, agentic traffic represented an average of 9.75% of total traffic in a 30-day window. AI agents now represent a consistent and growing share of total requests across e-commerce, media, financial services, and beyond.
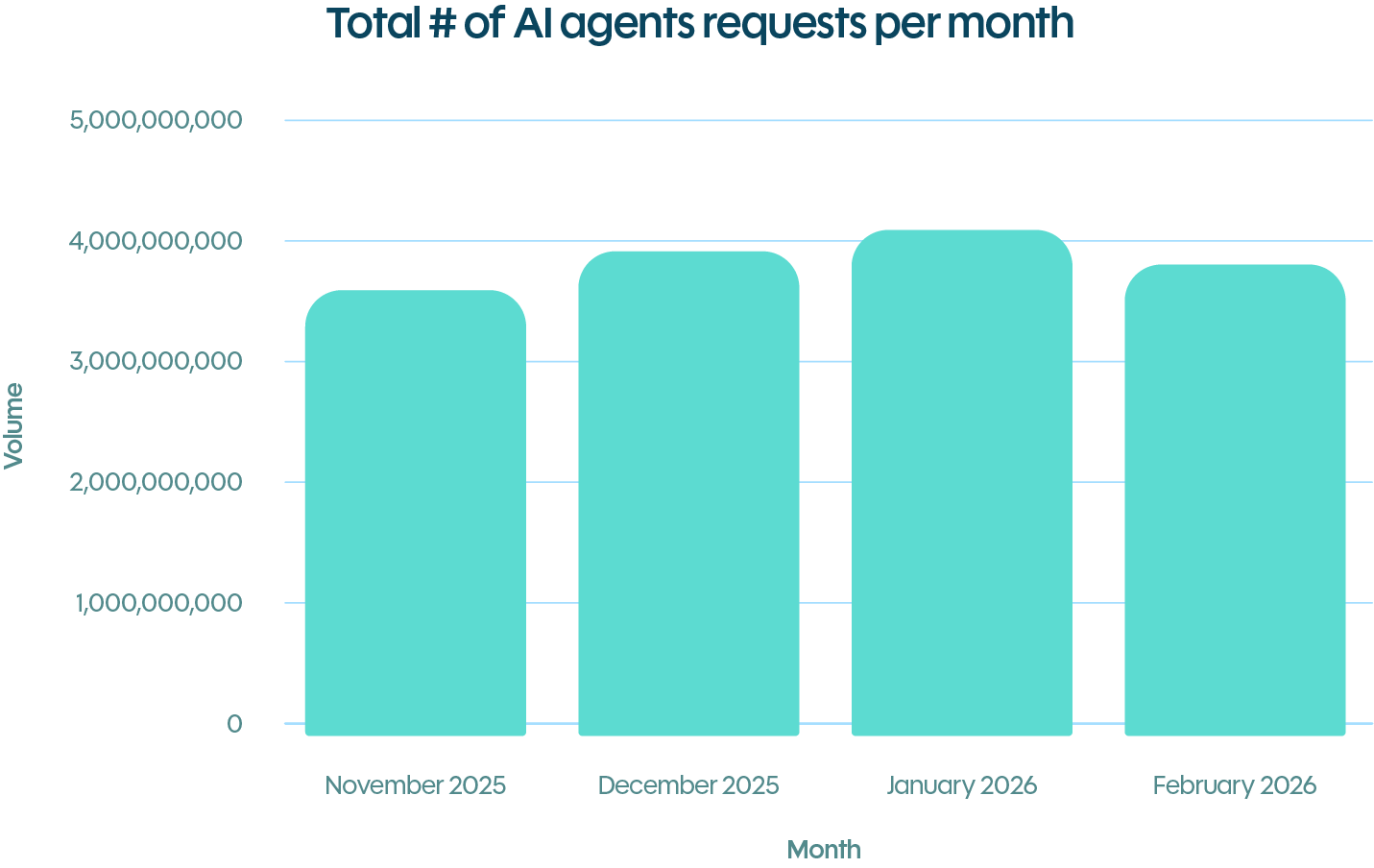
Volume does not equal value. Not all AI agent traffic serves the same purpose, and treating it as a single category is a mistake.
Meta ExternalAgent accounted for nearly 25% of top AI agent traffic on DataDome’s network in February 2026. ChatGPT-User followed at 19.1%, with Meta WebIndexer at 14.3%.
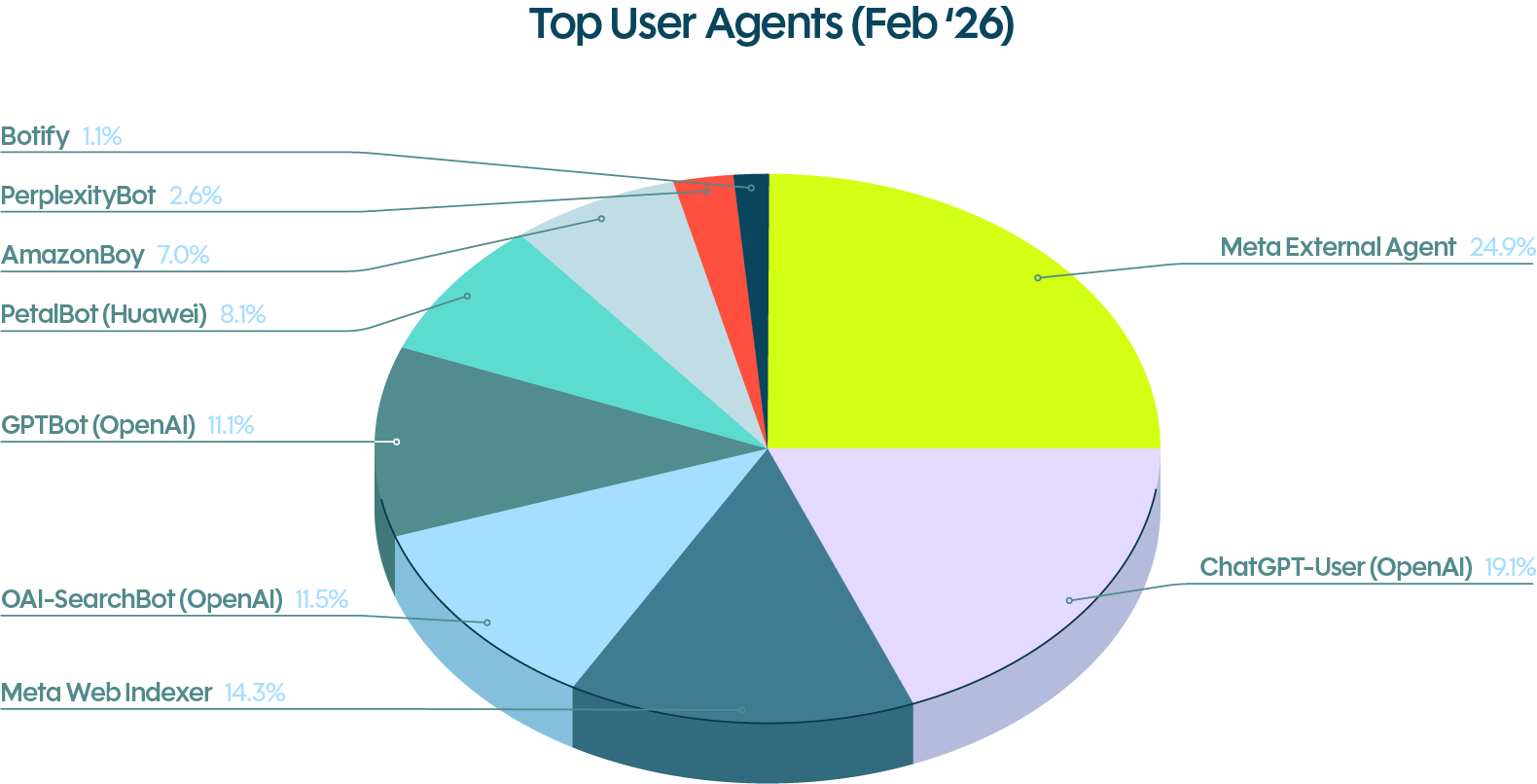
But volume tells only part of the story. Meta WebIndexer and MetaExternal Agent are built for fundamentally different purposes. Meta WebIndexer focuses on improving AI-driven search relevance, which carries potential referral value for publishers. Meta ExternalAgent is oriented toward large-scale data collection for AI model training, with no traffic benefit to the sites it visits. Two agents from the same company, appearing in similar volumes, with very different implications for site owners.
Without the ability to tell them apart, organizations cannot make informed decisions about either one.
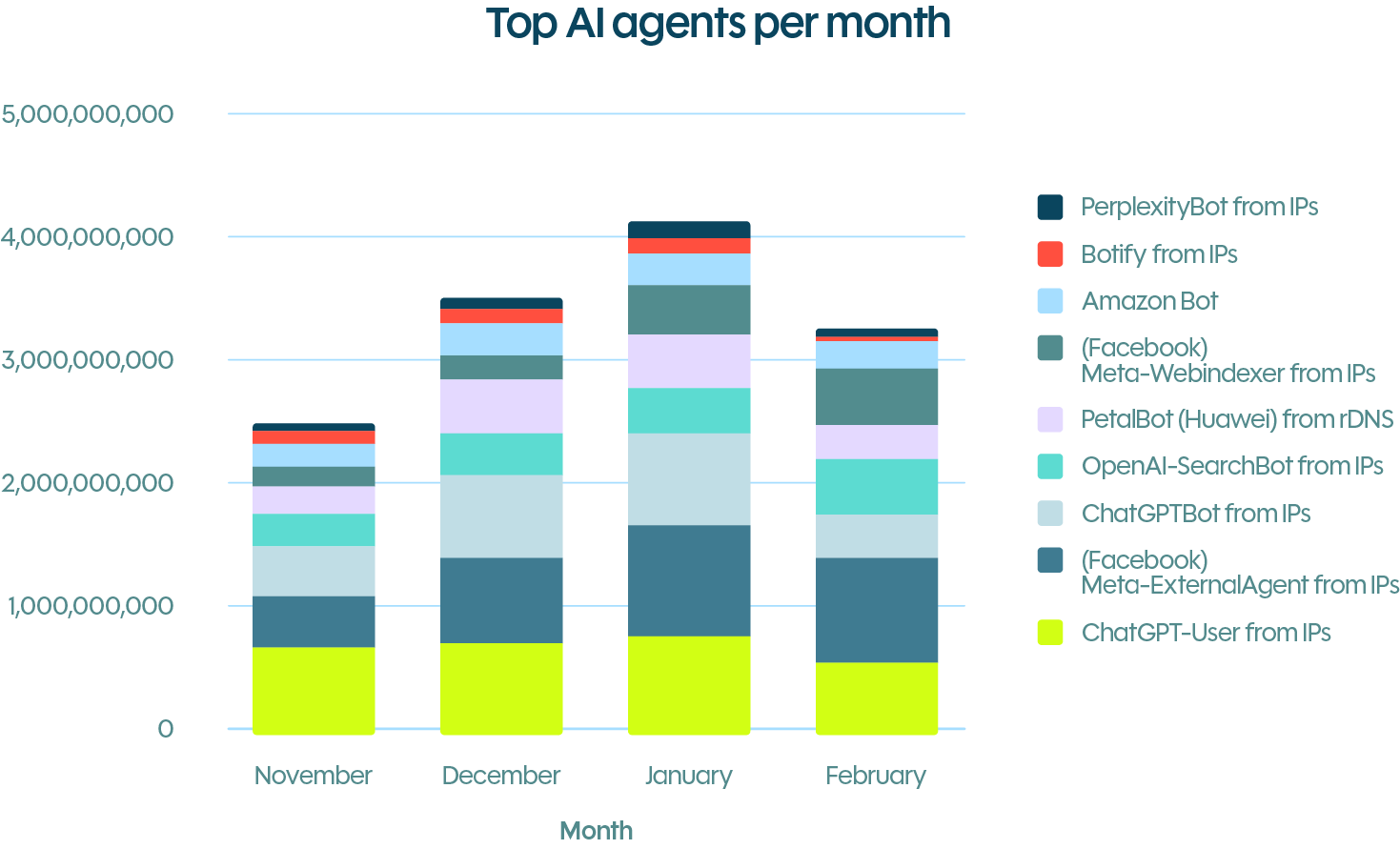
The rise of AI agent spoofing
You cannot trust that AI agents are who they say they are. One of the biggest obstacles to managing AI agent traffic is identification. Based on DataDome’s findings included in the Future of Search and Discovery Report, 80% of AI agents do not properly identify themselves, and 80% of sites do not verify agent identity. That gap creates a fundamental visibility problem. Without accurate identification, sites cannot distinguish between a legitimate indexer, a training data scraper, and a bad actor using a spoofed agent string to avoid detection.
DataDome’s network data reinforces the point. Well-known, widely trusted agent identities are being actively used as cover. Meta-externalagent was the most impersonated, with 16.4M spoofed requests, followed by ChatGPT-User with 7.9M. Perplexity had the highest rate of impersonation, with nearly 2.4% of requests claiming to be PerplexityBot found to be fraudulent.

The exposure on the receiving end is just as significant. Using an external data set, Galileo, DataDome’s threat research team, tested how roughly 700,000 of the world’s most-visited websites respond to spoofed AI agent requests. The majority returned a “200 OK” status, granting full access with no indication that the request was being treated any differently than human traffic. Major e-commerce platforms were broadly open.
For most sites, a spoofed agent string is effectively a free pass.
The rise of agentic browsers
Agentic browsers are a new and underappreciated vector. Beyond traditional crawlers, agentic browsers are now generating meaningful traffic across a wide range of industries. These tools simulate full browser sessions, rendering JavaScript and interacting with pages in ways that are harder to detect and harder to distinguish from real users.
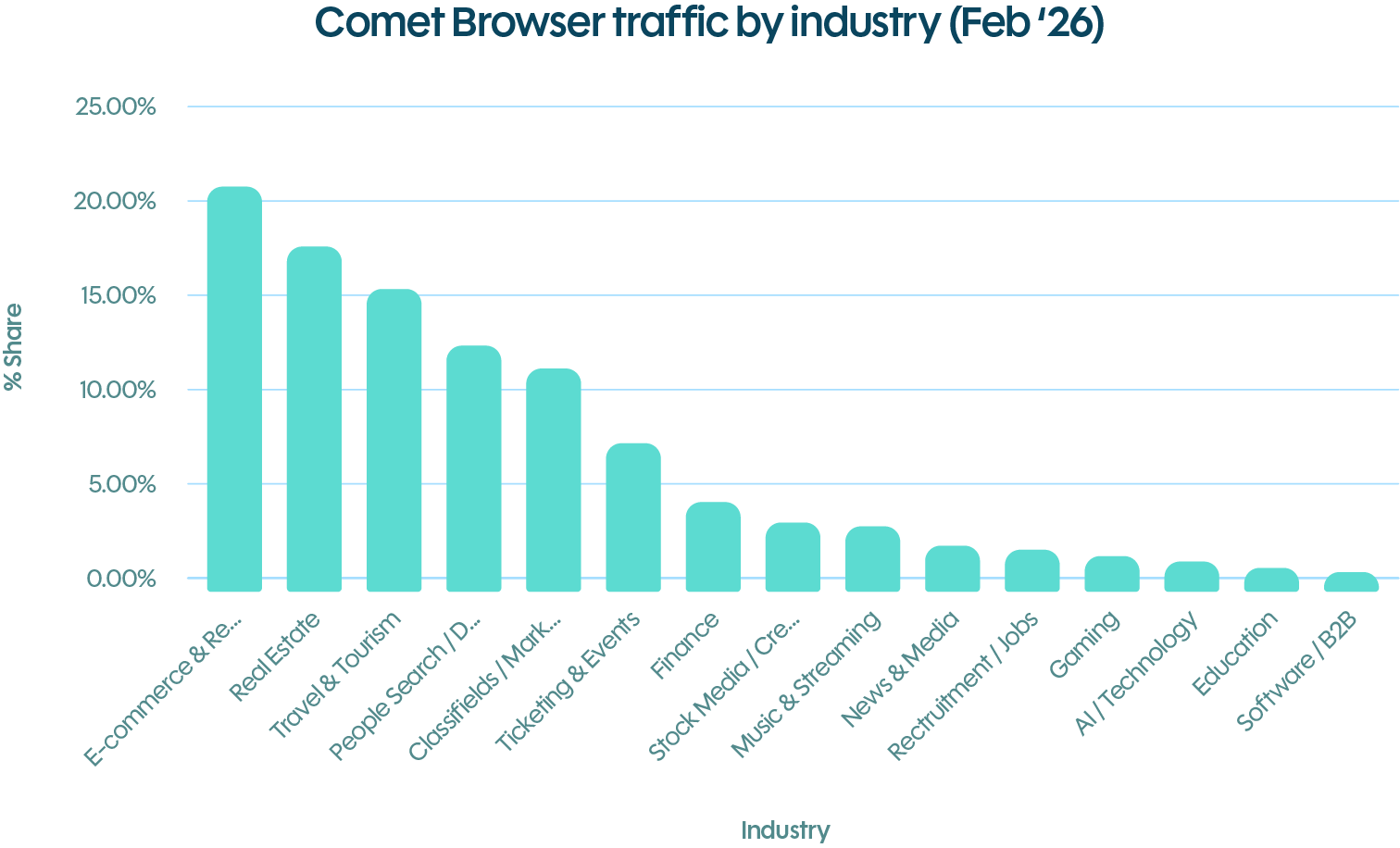
DataDome’s data from February 2026 shows this traffic concentrated in e-commerce and retail (roughly 20% of volume), real estate (17%), and travel and tourism (15%), with additional exposure in classifieds, ticketing, and finance.
The industries seeing the highest agentic browser traffic are the same ones sitting on the most valuable transactional data.
Implications & risks
- Invisible traffic is unmanaged traffic. Organizations that cannot accurately identify AI agent traffic cannot decide what to do with it, whether that means blocking, throttling, monetizing, or allowlisting.
- Spoofed agents exploit trust. Sites that allowlist known AI crawlers by user-agent string are exposed. For example, if a bad actor uses PerplexityBot or ChatGPT-User as cover, that allowlist becomes an attack surface.
- Agentic browsers raise the detection bar. Because these tools simulate full browser behavior, traffic analysis that relies on simple bot signals will not catch them. Detection requires behavioral analysis that accounts for session patterns, timing, and interaction signatures.
- High-volume agents are not necessarily high-value agents. Without agent-level classification, site owners have no way to weigh the cost of AI agent traffic against any benefit it delivers. Data-collection-focused agents consume resources with no return.
Recommendations
- Get visibility before making policy. Logging and classifying AI agent traffic by agent type, purpose, and behavior is the prerequisite for everything else. You cannot make sound decisions about traffic you cannot clearly see.
- Do not rely on user-agent strings alone. Both blocklists and allowlists built solely on user-agent values are unreliable. Behavioral signals should complement identity claims.
- Treat agent classification as an ongoing practice. The AI agent ecosystem is evolving quickly. New agents are appearing regularly, and existing ones are changing their behavior. Point-in-time assessments go stale fast.
- Establish a tiered access framework. Different agents warrant different treatment. Agents that drive search visibility may merit access. Agents focused on bulk data collection may not. A tiered policy based on agent purpose and behavior gives organizations more control over what they are giving away for free.
Conclusion
AI agent traffic is not theoretical, and it is not simple. Billions of requests are hitting sites every month, from agents with different identities, different purposes, and varying degrees of transparency about who they are. The organizations best positioned to manage this are the ones that can actually see it clearly. Right now, most cannot.
Run DataDome’s free Vulnerability Scan today to ensure your site is properly protected against malicious AI agents and bad bots.

Related posts

Introducing Priority Protect: The Only Virtual Waiting Room Built for the Agentic Era
Tell me more

How "Buy For Me" AI Agents Are Locking Up Inventory Before Customers Can Check Out
Tell me more

Why Virtual Waiting Rooms Fail: How Malicious Automation Beats Basic Queue Protection
Tell me more

How to Choose the Right Online Queue Management System for Your Business
Tell me more

