




Comment multiplier par 200 les instances AWS disponibles en 90 secondes
Résumé : DataDome est une solution de cybersécurité basée sur l’IA qui protège les applications mobiles, les sites Web et les API contre la fraude perpétrée par le biais de bots. Lorsque les attaques contre nos clients génèrent des pics de trafic importants, nous devons augmenter notre capacité de calcul très rapidement.
Pour permettre une mise à l’échelle ultra-rapide et économique de nos instances AWS, nous avons optimisé notre architecture et développé une application de mise à l’échelle automatique interne pour remplacer CloudWatch, le service de surveillance d’Amazon. Notre application de mise à l’échelle automatique prend une décision toutes les secondes, et veille à ce que le nombre et la nature de nos instances soient toujours optimisés en termes d’efficacité et de coût.
Le défi : la mise à l’échelle rapide pour des pics de trafic imprévisibles
DataDome est une entreprise de cybersécurité mondiale. Notre solution logicielle protège les entreprises de commerce électronique et de petites annonces contre la fraude en ligne et les attaques de bots, y compris le scraping et le scalping, le account takeover, les attaques DDoS de la couche 7, et le carding.
Notre moteur de détection de bots utilise l’apprentissage automatique avancé et une combinaison de méthodes de détection à états (stateful) et sans état (stateless). Pour assurer une protection en temps réel et une latence minimale, nous exécutons nos modèles d’apprentissage automatique à la périphérie via plus de 25 points de présence à travers le monde et provenant de plusieurs fournisseurs de cloud, y compris AWS, Azure, GCP, OVH, Scaleway et Vultr.
Pour une précision de détection optimale, nous analysons chaque requête adressée aux applications mobiles, sites Web et APIs de nos clients. Cela signifie que chaque fois qu’une attaque de bots contre l’un de nos clients génère un pic de trafic massif, nous pouvons avoir besoin de multiplier très rapidement notre capacité de calcul (serveurs d’API) par 10, 50, voire plus de 200.

Des attaques de bots générant des pics de trafic massifs dans l’une de nos 26 régions.
Outre des exceptions rares comme le Black Friday ou les sneaker drops, les pics de trafic ne peuvent pas être prévus. Une attaque de bots peut frapper à tout moment. Nous devons donc être en mesure de nous adapter suffisamment rapidement pour exécuter notre détection d’apprentissage automatique à la périphérie :
- sans interruption
- pendant des attaques massives
- à n’importe quel moment du jour ou de la nuit
- sans aucun impact sur les utilisateurs humains
- tout en maîtrisant les coûts.
Ci-dessous, nous présentons le processus d’optimisation que nous avons suivi pour réaliser une mise à l’échelle automatique ultra-rapide sur nos points de présence périphériques AWS. Nous espérons que notre solution pourra inspirer d’autres équipes DevOps confrontées à des défis similaires.
Préalable : éliminer les points de défaillance uniques dans les composants couplés
Avant de rentrer dans le vif du sujet, voici un petit avertissement : les dépendances sont importantes !
Notre application est couplée à une base de données et à plusieurs autres composants. Et comme nous l’avons vite découvert, tous les composants couplés doivent être en mesure de gérer la mise à l’échelle de l’application.
Pour permettre une mise à l’échelle automatique fluide, nous devions d’abord éliminer tous les points de défaillance uniques (SPOFs) potentiels, c’est-à-dire les dépendances qui par nature ne sont pas extensibles. Cela comprenait des connexions directes à des bases de données, des systèmes de cache partagés, etc., mais même les outils asynchrones peuvent être des goulets d’étranglement.
C’était un grand projet en soi, mais en étroite collaboration avec nos DevOps, notre équipe de développement a réussi à éliminer tous les points de défaillance uniques potentiels. Par conséquent, notre architecture actuelle nous permet d’ajouter des centaines d’instances simultanément, et de les supprimer à nouveau lorsque nous n’en avons plus besoin, sans impact sur l’application.
Étape 1 : adoptez une approche basée sur les données
Lorsque vous souhaitez améliorer les performances de n’importe quel système, vous devez d’abord identifier les bonnes métriques pour mesurer votre succès.
Chez DataDome, nous utilisons une pile standard en open source pour l’infrastructure et la surveillance des applications :
- Prometheus pour la surveillance des métriques d’application et des points de données
- Grafana pour les tableaux de bord et les alertes.
Nous suivons actuellement 9700 étiquettes Prometheus et agrégeons les métriques dans environ 180 tableaux de bord Grafana.
Notre objectif final était d’ajouter et de supprimer automatiquement de la capacité de calcul à nos points de présence le plus rapidement possible, pour exécuter efficacement nos modèles d’apprentissage automatique à la périphérie, même lors d’attaques massives de bots. Mais qu’est-ce qui constitue réellement une attaque, et surtout, quelle serait la métrique la plus efficace pour déclencher la décision de mise à l’échelle ?
Nous avons décidé que notre métrique idéale serait le signe le plus précoce d’un besoin d’augmenter la capacité de calcul, et la métrique la plus fiable pour estimer la nécessité de mise à l’échelle.
Étape 2 : évaluez les limites des outils disponibles
En règle générale, nous essayons d’éviter la sur-ingénierie pour répondre à nos défis DevOps. Nous préférons commencer simplement, en utilisant les outils que nous avons déjà, et en évaluant leurs limites avant de décider éventuellement de les remplacer.
Dans ce cas précis, nous avons consacré beaucoup de temps et d’effort à tester diverses mesures AWS : à quelle vitesse nous permettaient-elles d’atteindre la capacité de calcul dont nous avons besoin à tout moment ?
Charge CPU de l’instance
Avant de commencer ce projet, nous basions nos décisions de mise à l’échelle sur la charge CPU des instances.
En théorie, c’est une bonne métrique, surtout parce que toutes les requêtes ne requièrent pas la même quantité de ressources. La charge CPU nous fournit des données précises sur le coût de traitement d’une requête donnée.
Cependant, ce que cette métrique ne peut pas nous apprendre, c’est ce qui va se passer par la suite.
Lorsqu’une attaque arrive, la charge CPU peut rapidement atteindre 100 % : toutes les instances à la périphérie sont surchargées. Et si cela se produit, la charge CPU ne peut pas nous indiquer si nous devons multiplier nos instances par 2, par 10, ou peut-être par 100.
À chaque fois que la charge CPU passait à 100 %, nous devions estimer la capacité supplémentaire à ajouter, observer si cela était suffisant, ajouter plus si nécessaire, et ainsi de suite. Ce n’était ni rapide ni fiable. Nous devions trouver une meilleure métrique pour déclencher la mise à l’échelle.
Trafic moyen d’EC2
Une idée que nous avons testée était de mesurer le volume de trafic global dans la machine, mais devant l’application DataDome. C’était également une métrique prometteuse en théorie, car elle fournit une représentation très précoce et assez précise de l’augmentation du trafic.
Hélas, cela n’a pas fonctionné pour notre cas d’utilisation. La raison est que le trafic moyen d’EC2 inclut le flux de trafic entre les machines, et non pas seulement le trafic qui vient de l’extérieur. Les instances communiquent entre elles et avec l’application DataDome, ce qui a ajouté trop de données au périmètre. Nos tentatives d’isoler le trafic des clients du trafic des applications avec une précision satisfaisante ont été infructueuses.
Par conséquent, la métrique trafic moyen d’EC2 a satisfait notre critère « précoce », mais pas le critère « fiable ».
Trafic entrant de l’équilibreur de charge réseau
Au niveau du réseau, le trafic arrive sur le site Web de notre client, passe par l’équilibreur de charge de DataDome (NLB), puis par nos instances AWS, et enfin il arrive à l’application DataDome pour l’analyse. Tout cela se produit en quelques microsecondes, mais ça reste un parcours linéaire, ce qui signifie que certaines métriques peuvent détecter une augmentation de trafic un peu plus tôt que d’autres.
Notre tout premier point de contact avec la requête est au niveau de l’équilibreur de charge réseau AWS ; c’est là que la requête entre dans notre infrastructure. Puisque le NLB encaisse également tout ce que nous lui envoyons, il semblait être l’endroit idéal pour collecter nos métriques de décision de mise à l’échelle.
Cependant, lorsque nous avons commencé à vraiment creuser dans les données de l’équilibreur de charge, nous avons découvert qu’il faut 2 minutes rien que pour recevoir les métriques du NLB. Ensuite, CloudWatch a besoin d’encore une minute pour analyser et alerter. Nous avons discuté avec AWS pour voir s’il était possible de raccourcir ce délai, mais en vain. C’est non négociable.
Et bien que 3 minutes ne paraissent pas une grande affaire, pendant ces minutes, une attaque de bots peut changer complètement de caractère.
Par exemple, nos données d’il y a 3 minutes pourraient indiquer que nous devrions ajouter 20 machines pour faire face à la charge supplémentaire, alors qu’en ce moment même, le besoin réel est peut-être plus proche de 120.
Plus vite nous pourrons déclencher la décision de mise à l’échelle et plus notre moteur de détection sera performant.
La bonne métrique : le volume de requêtes par seconde
Au final, la solution que nous avons trouvée était de fonder nos décisions de mise à l’échelle sur une métrique qui ne provient pas du groupe de mise à l’échelle automatique ou de l’équilibreur de charge, mais de notre propre application : le volume de requêtes par seconde (RPS).
Nous mesurons en permanence le volume de requêtes qui entrent dans notre propre application, et nous pouvons obtenir les informations en temps réel. Donc, même si les requêtes atteignent le NLB avant d’arriver à notre application, le RPS est de loin la métrique la plus précoce à laquelle nous pouvons réellement accéder.
Le RPS satisfait également notre critère de fiabilité. Notre application nous informe « À l’heure actuelle, je gère x requêtes par seconde ». Cela nous donne une idée très fiable de l’augmentation de trafic entrant telle qu’elle se produit, et non pas telle qu’elle se produisait il y a trois minutes.
Synthèse des mesures évaluées
- Charge CPU : Une bonne première mesure pour identifier une attaque, mais qui ne nous permet pas d’anticiper l’ampleur de l’attaque et d’y répondre de façon appropriée.
- Trafic moyen d’EC2 : Inclut le flux de trafic entre les machines, ce qui ajoute trop de données au champ d’application.
- Trafic entrant NLB : En relation directe avec le comportement des attaquants, mais uniquement exposé via le pipeline AWS-CloudWatch, qui ajoute un délai de 3 minutes et nous conduit à dimensionner notre réponse pour une situation passée.
- Requêtes par seconde : Agrégée pour tous les hôtes du groupe de mise à l’échelle automatique, cette mesure est idéale, car elle reflète avec précision la situation actuelle et nous permet de réagir de manière appropriée.
Étape 3 : remplacez les composants limitants.
Nous avons découvert les limites de nos outils existants lors de notre quête de la métrique parfaite. Les métriques de CloudWatch ne nous permettaient pas de déclencher une mise à l’échelle en moins de 3 minutes, même si nous optimisions tout le reste. Nous devions remplacer CloudWatch pour prendre nos décisions de mise à l’échelle au bon moment.
Créer une application Autoscaler interne
Comme CloudWatch ne pouvait pas fournir l’agilité dont nous avions besoin, nous en avons conclu qu’il nous fallait créer notre propre application de mise à l’échelle automatique pour remplacer ce composant limitatif. Et c’est ce que nous avons fait.
Notre application Autoscaler interne est un script Python qui s’exécute sur une machine dédiée dans chaque région AWS. Elle effectue des calculs purs et simples : elle compte le nombre de requêtes traitées par notre application à un moment donné, et indique à AWS le nombre d’instances dont nous avons besoin. Si le volume de trafic est X, nous avons besoin de Y machines.
L’intervalle d’une seconde est suffisamment court pour prendre les bonnes décisions. Une fréquence de prise de décision plus élevée risquerait d’aller à l’encontre des limites d’utilisation de l’API d’AWS, et nous pourrions nous retrouver face à une limitation du débit ou être bloqués.
Surveiller et optimiser la solution de mise à l’échelle automatique
Toute solution efficace de mise à l’échelle automatique doit être ultra-précise. Elle nécessite donc un suivi minutieux. Nous devons savoir :
- Prend-elle ses décisions aux bons moments ?
- Ajoute-t-elle le bon nombre d’instances pour le volume de requêtes mesuré ?
- Combien de temps lui faut-il pour prendre une décision ?
- Etc.
Cette opération est assez simple si vous utilisez le tableau de bord CloudWatch, car toutes les alertes que vous configurez sont déjà des indicateurs de performance. Si vous décidez de procéder à une mise à l’échelle en fonction de l’utilisation du CPU ou du réseau, surveillez le temps de réponse des applications et le taux d’erreur pour comprendre ce qui se passe lorsque les décisions de mise à l’échelle sont prises.
Nous avons dû faire preuve d’encore plus de vigilance lorsque nous sommes passés à notre solution d’Autoscaler personnalisée, car nous gérions désormais la solution entièrement par nos propres moyens.
Nous avons donc créé ce tableau de bord :
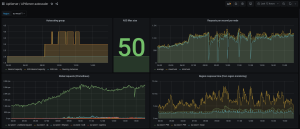
Le tableau de bord indique tout ce que nous devons savoir sur notre PoP :
- État actuel du groupe de mise à l’échelle automatique
- RPS par instance
- RPS global et temps de réponse.
Nous avons également ajouté quelques métriques relatives à l’Autoscaler lui-même, qui permettent de détecter des problèmes potentiels.

Par exemple, comment l’Autoscaler doit-il se comporter si un serveur est surchargé lors d’une attaque de bot et ne peut pas nous communiquer son volume de requêtes ? Cela peut être une source d’erreurs potentielles que nous devons prendre en compte dans nos calculs. Nous avons également consacré beaucoup de temps à rendre nos composants aussi résistants que possible à la surcharge… mais nous reviendrons sur ce sujet un autre jour. 🙂
Notre priorité est toujours de protéger autant de trafic que possible. Dans ce cas, nous acceptons donc que notre Autoscaler puisse surprovisionner des instances pendant une courte période de temps.
Tampons décisionnels
Comme vous pouvez le voir sur la première capture d’écran ci-dessus, notre solution a d’abord légèrement hésité entre deux valeurs de capacité souhaitées lorsque nous étions proches de la limite.
Par exemple, si notre seuil était de 1 200 requêtes par seconde par instance et que nous avions 1 210 requêtes par seconde, nous devrions ajouter une instance. Si le volume de trafic redescendait à 1 180 requêtes par seconde, nous devrions en supprimer une.
Ajouter et supprimer constamment des instances était un peu laborieux, il nous fallait donc trouver un moyen d’atténuer ce problème. Nous voulions également éviter de réduire l’échelle trop rapidement, car pendant les attaques massives il y a souvent de courtes périodes d’activité réduite avant que les bots ne reviennent en force.
Nous utilisons maintenant deux types de tampons :
- Tampon de volume : L’Autoscaler ajoutera des machines uniquement si le volume dépasse notre seuil d’au moins 50 requêtes par seconde, et les supprimera quand le volume est 50 requêtes en-dessous du seuil.
- Tampon de temps (pour réduire l’échelle) : L’Autoscaler réduira l’échelle uniquement si aucune autre action d’augmentation ou de réduction d’échelle n’a été effectuée au cours des 10 dernières minutes.
Réduire le temps de démarrage de l’application
Outre les limites liées aux indicateurs de performances de CloudWatch, nous avons identifié une contrainte au sein de notre propre application : son temps de démarrage.
Pour détecter et bloquer correctement les bots malveillants à la périphérie, nos serveurs API utilisent des modèles de référence. Ces référentiels changent en permanence, car nos modèles d’apprentissage automatique identifient sans cesse de nouveaux modèles de bots et mettent constamment à jour les algorithmes.
Les référentiels étaient, jusqu’à récemment, présentés à nos serveurs API sous format binaire, ce qui nécessitait un calcul dédié sur chaque instance. Chaque fois qu’un nouveau serveur API démarrait, il devait compiler son propre référentiel à partir de ces descriptions des derniers modèles avant de pouvoir commencer à filtrer le trafic. Ce processus pouvait durer quelques minutes, voire parfois plus.
Nous avons donc introduit dans notre architecture un élément intermédiaire qui crée des référentiels prêts à utiliser pour le serveur API à partir des descriptions brutes afin de réduire ce temps de démarrage. Désormais, un nouveau serveur API n’a plus besoin de construire son propre référentiel lorsqu’il démarre. Il peut simplement récupérer la description déjà compilée des modèles de blocage les plus récents. Il sera ensuite mis à jour via des correctifs toutes les millisecondes (en utilisant les sujets Kafka), car nos modèles apprennent en permanence des attaques de bots en cours et des nouvelles attaques.
Les résultats ont dépassé nos attentes les plus folles : Le changement d’architecture a réduit le temps de démarrage de notre application d’une minute !
Étape 4 : optimiser les coûts
Les optimisations précédentes out toutes un coût. Nous avons parfois besoin de centaines d’instances supplémentaires en l’espace de quelques minutes, ce qui a des répercussions immédiates sur nos factures AWS. L’étape suivante était donc de rechercher des moyens d’optimiser ces coûts.
Les avantages et les inconvénients des instances Spot
Les instances Spot (ou instances ponctuelles) sont des machines AWS disponibles à la demande, nettement moins chères que les instances standard — la différence de prix peut atteindre 60 à 80 %. Il y a cependant une bonne raison à cela : les instances Spot peuvent à tout moment être interrompues et réattribuées à quelqu’un d’autre s’il y a une demande pour ces instances à un prix plus élevé. C’est un peu comme une vente aux enchères : si vous n’êtes pas le plus offrant, tant pis pour vous.
Nous voulons tout de même utiliser des instances Spot en production, car elles sont beaucoup moins chères. Mais si nous perdons une telle instance, nous ne la récupérerons pas. Une autre instance sera créée pour la remplacer, ce qui prend du temps.
Pour minimiser l’impact de ces interruptions, notre application doit être capable d’échouer sans tout interrompre. C’est là que notre architecture sans état commence à porter ses fruits ! Notre équipe de développement a également réussi à minimiser l’impact sur notre application en cas de perte d’un serveur : notre application est placée derrière un équilibreur de charge sur chaque POP, et des contrôles d’intégrité garantissent que toute instance défaillante sera retirée de la liste de l’équilibreur de charge.
Une combinaison de machines optimisée
Autre condition à l’utilisation d’instances Spot : nous devions pouvoir les remplacer très rapidement si nous en perdions plusieurs simultanément.
Cette fois, c’est AWS qui a préconisé la solution : utiliser différents types de machines. Nos machines ont toutes la même taille, mais elles sont de types différents.
Si nous utilisons, par exemple, 100 instances d’un même type, nous risquerons de les perdre toutes en même temps si quelqu’un d’autre a soudainement besoin de 200 machines de ce type précis. AWS reprendra toutes nos instances à ce POP si un autre utilisateur est prêt à payer plus. Et si nous perdons 100 instances en même temps, nous aurons des soucis.
Nous demandons donc désormais trois types différents d’instances Spot lorsque nous avons besoin d’ajouter rapidement un grand nombre de nouvelles instances. Cela réduit considérablement le risque de perdre plusieurs instances à la fois, car il est extrêmement improbable que quelqu’un d’autre demande exactement la même combinaison de types de machines que nous, au même moment.
Nous avons initialement envisagé d’utiliser encore plus de types différents, mais il y avait des contraintes : notre application doit fonctionner sur tous les types de serveurs, et ceux-ci doivent avoir une capacité de calcul suffisante. En fin de compte, nous avons identifié 3 types qui fonctionnent, et jamais une perte de serveurs n’a eu d’impact négatif sur notre application en production.
Nous avons appliqué la configuration suivante sur nos groupes de mise à l’échelle automatique :
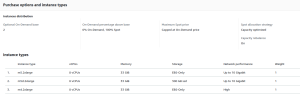
Nous avons une base de deux instances à la demande (le minimum pour notre groupe de mise à l’échelle automatique), les autres sont des instances Spot de trois types différents. Certaines régions n’ont que deux types d’instance, car m4.2xlarge n’est pas disponible partout.
Étape 5 : amélioration permanente
L’Autoscaler fait maison a permis d’améliorer considérablement les performances de notre infrastructure, mais il ne sera jamais complètement terminé. Nous continuons à mesurer, à tester et à améliorer quotidiennement notre infrastructure.
Minimiser le temps de démarrage de l’instance
Le temps de démarrage de l’instance est l’un des premiers domaines que nous avons identifié comme pouvant encore être optimisé.
Lorsqu’un événement de mise à l’échelle est déclenché (l’Autoscaler demande une nouvelle instance à AWS), celle-ci n’est pas disponible immédiatement, et notre application ne démarre pas non plus tout de suite sur la nouvelle instance. Pendant ce temps-là, l’attaque peut évoluer, et les instances que nous utilisons déjà peuvent atteindre leur pleine capacité.
Nous ne pouvons pas influencer le délai de disponibilité d’une nouvelle instance après l’événement de mise à l’échelle, cela dépend d’AWS. Nous avons donc décidé de minimiser le temps de démarrage de l’instance, entre le moment où un événement de mise à l’échelle est déclenché et celui où notre application est pleinement opérationnelle et peut gérer le trafic sur la nouvelle instance.
Nous avons pour cela testé et mesuré trois chemins différents.
Système d’exploitation (AL2, Centos7, Centos8 ?)
L’une des hypothèses était que le choix du système d’exploitation pouvait influencer le temps de démarrage. Nous utilisions Centos 7, donc nous avons testé Centos 8 et Amazon Linux 2 pour voir si cela changeait le temps de démarrage.
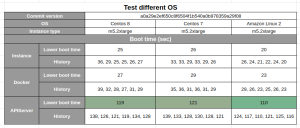
D’après nos tests, passer à Amazon Linux 2 nous aurait permis de réduire le temps de démarrage de l’instance d’environ 10 secondes. Cependant, il aurait également fallu faire de gros efforts de développement, et ce système d’exploitation n’aurait pas été utilisable sur nos POP qui ne sont pas sur AWS. Modifier la distribution a un impact sur les composants essentiels du système d’exploitation et peut entraîner des comportements très différents en production, compliquant ainsi le processus de débogage.
Nous en avons conclu qu’une amélioration de 10 secondes n’était pas suffisante pour justifier le coût et les inconvénients, et nous avons décidé de conserver Centos 7.
Type d’instance
Nous avons également testé différents types d’instance. Lorsque nous demandons une nouvelle instance, nous définissons la quantité de stockage, la mémoire interne et la capacité de calcul dont nous avons besoin. Nous utilisions m5.xlarge. Pourrions-nous utiliser un type de serveur plus petit ou plus grand ? Par exemple, la capacité supplémentaire des serveurs m5.2xlarge améliorerait-elle le temps de démarrage de l’instance ?
Après avoir testé toutes les autres instances m5 (et c5 également), nous avons constaté une amélioration potentielle de seulement quelques secondes, et nous avons estimé que le changement coûtait trop cher. Nous avons décidé de garder le type d’instance m5.xlarge.
Taille du disque
Nous avons enfin décidé d’expérimenter la taille des disques de nos instances EC2. Nous avons toujours utilisé des disques EBS de 50 Go. Mais en fait, notre application ne stocke aucun fichier sur l’instance. Nous n’avons donc pas besoin de cet espace de stockage.
Après quelques tests sur différentes instances, nous avons découvert qu’en effet, plus le disque est grand, plus le temps de démarrage est long.
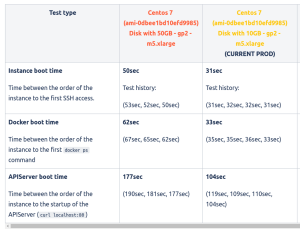
Cette découverte a été extrêmement intéressante : nous avons pu réduire le temps de démarrage d’environ 75 secondes simplement en utilisant des disques de 8 Go au lieu de 50 Go ! (Nous ne pouvons pas descendre en dessous de 8 Go, car en cas de problème, l’instance commencera à écrire une série de fichiers que nous devons pouvoir gérer avec un minimum de capacité).
Avant cette optimisation, lorsque nous demandions une nouvelle instance, notre application mettait environ 2 à 2,5 minutes à être opérationnelle et capable de traiter les requêtes entrantes. Nous avons maintenant le bon nombre d’instances opérationnelles en 1,5 minute. Notre infrastructure peut à tout moment gérer le trafic que nous avions il y a 90 secondes, et tout cela se fait automatiquement.
Personnaliser la RAM
Notre prochain chantier est d’augmenter le nombre de types d’instances compatibles que nous pouvons utiliser. L’objectif est de pouvoir répartir notre charge sur un plus grand nombre de types de serveurs supplémentaires pour réduire le risque de perdre de nombreuses instances en une seule fois (voir la section « Une combinaison de machines optimisée » ci-dessus).
L’idée est de personnaliser la RAM que notre application Java utilise, en fonction de la RAM disponible dans une instance donnée. Cela devrait nous permettre d’utiliser des instances plus importantes à l’avenir.
Notre application fonctionne actuellement très bien sur des instances de 32 Go de RAM. Elle pourrait également fonctionner avec des instances de 64 Go, mais cela n’est évidemment pas gratuit.
De plus, lorsque notre application démarre, elle doit connaître la RAM disponible de l’instance et s’en attribuer un pourcentage adéquat. Par exemple, l’application doit savoir qu’elle dispose de 64 Go de RAM et l’utiliser dans sa totalité. Il n’est pas logique de payer une machine plus grande si l’application n’utilise pas la totalité. Inversement, si l’instance ne dispose que de 16 Go de RAM, l’application ne devra pas démarrer avec la supposition qu’il y a 32 Go disponibles.
Lorsque ce texte a été rédigé, cette optimisation n’avait pas été encore terminée. Surveillez les prochains billets pour connaître les résultats !
Simulations avancées
Enfin, nous explorons une piste d’amélioration dans l’Autoscaler : la prise en compte des métriques passées.
L’Autoscaler ne réagit aujourd’hui qu’aux dernières métriques. Par exemple, 120 > 100 = ajouter 10 hôtes, 150 > 120 = ajouter 20 hôtes, etc.
Nous pourrions remplacer ce feedback linéaire par une interpolation polynomiale ou effectuer des simulations plus complexes basées sur les dernières métriques Y. Cela nous permettrait d’anticiper non seulement la croissance actuelle du trafic, mais aussi celle à venir.
À retenir
La solution de détection des bots de DataDome gère fréquemment d’énormes pics de trafic que nous ne pouvons pas anticiper du fait de la nature du trafic de nos clients. Si nous voulons optimiser l’efficacité de notre détection par apprentissage automatique à la périphérie, même lors d’importantes attaques de bots, nous devrons pouvoir faire évoluer notre capacité de calcul aussi rapidement que possible, à n’importe quelle heure du jour ou de la nuit.
Utiliser les indicateurs de performance de CloudWatch est devenu un facteur limitant en raison de cette importance du temps réel. Nous avons choisi de baser nos décisions de mise à l’échelle sur une métrique de notre propre application (les requêtes par seconde, ou RPS) au lieu d’attendre que CloudWatch analyse nos métriques ASC ou NLB et déclenche l’opération de mise à l’échelle.
En ce qui concerne les décisions de mise à l’échelle, nous avons remplacé CloudWatch par une application développée en interne qui prend désormais une décision toutes les secondes. Grâce à d’autres optimisations, toutes les instances dont nous avons besoin sont désormais disponibles et pleinement opérationnelles dans les 90 secondes qui suivent le premier signe d’augmentation du trafic. Peu importe que nous ayons besoin de multiplier notre capacité par 2 ou par 200, tout est entièrement automatisé.
- Remettez en question votre pile existante, y compris les composants de bas niveau.
- N’assumez pas ; évaluez. Soyez orienté(e) par les données et suivez vos problèmes ainsi que vos progrès.
- N’en faites pas trop en termes d’ingénierie. Utilisez d’abord des outils simples (ici : CloudWatch), puis évaluez leurs limites.
- Identifier les goulets d’étranglement. Remplacer les composants limités. Les développer en interne si nécessaire.
- Identifier les sources de coûts, surveiller et optimiser à long terme (FinOps).
- Planifier des améliorations continues.

Articles liés

DataDome désigné comme leader dans The Forrester Wave™ : Bot And Agent Trust Management Software, Q2 2026
En savoir plus

Que sont les « sneaker bots » ? Comment les détecter et les éviter ?
En savoir plus

Salles d'attente virtuelles : la faille que les bots exploitent
En savoir plus

Comment choisir un système de gestion de file d'attente en ligne
En savoir plus

