




Comment utiliser l’apprentissage automatique pour détecter les proxys résidentiels ?
L’apprentissage automatique (ou machine learning, ML) est un levier essentiel pour améliorer la protection à grande échelle contre les bots sophistiqués et la fraude en ligne. Chez DataDome, nous utilisons le ML, entre autres, pour identifier les proxys résidentiels.
Les proxys résidentiels sont de plus en plus utilisés par les attaquants car leurs adresses IP ressemblent à celles des utilisateurs humains ordinaires. La capacité à détecter si une requête provient d’un proxy résidentiel est donc cruciale pour améliorer la précision de la détection des menaces.
Dans ce guide, nous allons explorer l’un des modèles d’apprentissage automatique que DataDome utilise pour classifier les adresses IP résidentielles et déterminer si elles ont récemment été exploitées comme proxys résidentiels par des bots malveillants. Mais avant de plonger dans les détails du ML, commençons par une présentation des fondamentaux.
Qu’est-ce qu’une adresse IP ?
Une adresse IP (Internet Protocol) est une série de chiffres qui sert d’adresse numérique pour un appareil sur internet. Elle permet d’acheminer correctement le trafic entre l’appareil et un site web.
Toutefois, un appareil n’a pas toujours une adresse IP unique. Une même adresse IP peut être partagée par un seul utilisateur ou par des milliers d’utilisateurs (ou encore des bots) en même temps.
Les adresses IP résidentielles, fournies par les fournisseurs d’accès à internet (FAI), sont généralement partagées au sein d’un foyer et changent rarement. En revanche, les adresses IP mobiles peuvent être utilisées simultanément par des milliers d’appareils.
Qu’est-ce qu’un proxy ?
Un proxy est un programme qui permet aux utilisateurs de masquer leur adresse IP en redirigeant leur trafic via l’infrastructure d’un tiers. Les proxys sont souvent utilisés par des individus pour des raisons d’anonymat ou de confidentialité, mais ils sont également prisés par les opérateurs de bots malveillants pour éviter d’être bloqués.
Lorsqu’une activité suspecte ou malveillante est détectée à partir d’une adresse IP, de nombreux services en ligne bloquent cette IP pendant un certain temps. Pour contourner ces blocages, les développeurs de bots et les fraudeurs exploitent des proxys afin de faire transiter leur trafic par d’autres adresses IP.
Le schéma ci-dessous montre le parcours d’une requête HTTP, d’abord effectuée sans proxy, puis avec proxy.
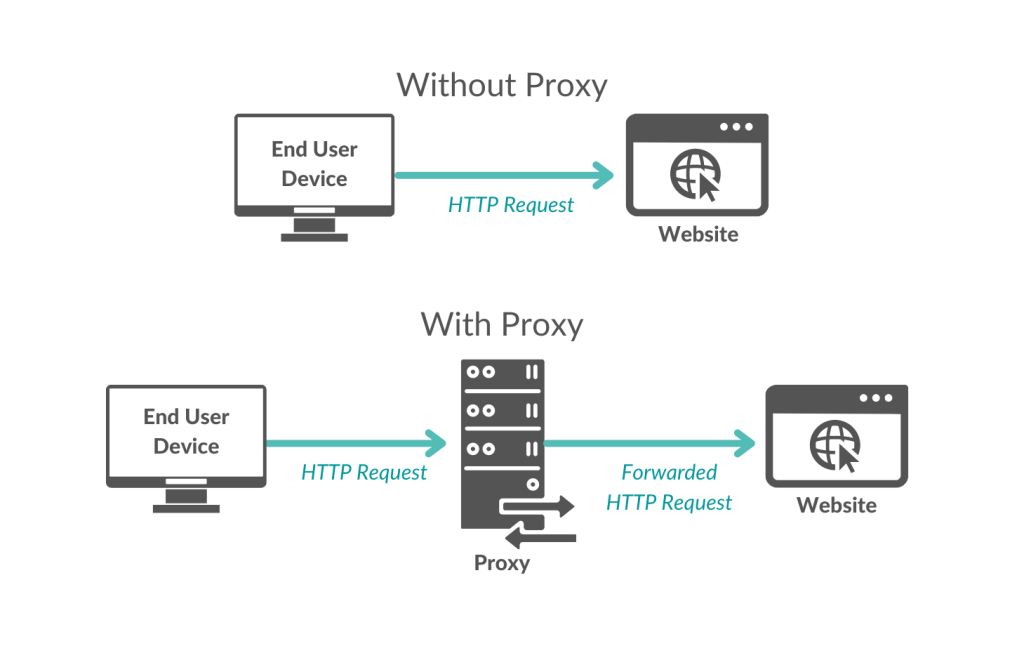
Lorsqu’un utilisateur (ou un bot) utilise un proxy, la requête est redirigée par le proxy vers le site web ou l’application mobile. Ainsi, du point de vue du site web, il semble que la requête provienne de l’adresse IP du proxy, et non de l’utilisateur final.
Exploiter l’apprentissage automatique basé sur le comportement pour détecter les proxys résidentiels
Pourquoi utiliser des signaux comportementaux ?
Chez DataDome, nous utilisons l’apprentissage automatique supervisé pour déterminer si une adresse IP résidentielle est utilisée comme proxy. Bien que plusieurs types de signaux (comme les indicateurs réseau) puissent aider à détecter les proxys résidentiels, l’approche que nous présentons ici se concentre sur les signaux comportementaux.
Pourquoi ce choix ? Parce que la majorité des proxys résidentiels sont partagés par plusieurs développeurs de bots. Bien que les adresses IP mobiles et d’entreprises soient également fortement partagées, le trafic provenant de ces adresses montre des schémas différents de ceux des proxys résidentiels.
Chaque développeur de bots crée des bots avec des empreintes HTTP et des comportements différents. Certains utilisent les proxys de manière persistante (c’est-à-dire qu’une séquence de requêtes du même bot passe par le même proxy), tandis que d’autres utilisent des proxys de manière rotative (chaque requête du bot passe par un proxy différent).
Dans tous les cas, le trafic des adresses IP de proxys résidentiels se distingue nettement de celui des IP utilisées uniquement par des utilisateurs humains.
Remarque : la différence ne réside pas seulement dans le volume des requêtes, mais principalement dans le comportement des adresses IP.
Collecte d’un jeu de données pour entraîner et évaluer notre modèle ML
Pour entraîner et évaluer notre modèle de machine learning (ML), nous avons conçu un processus permettant de constituer un jeu de données composé de :
- Adresses IP de proxys résidentiels (étiquettes positives)
- Adresses IP résidentielles non utilisées comme proxys (étiquettes négatives)
1. Collecte des adresses IP de proxys résidentiels :
Pour rassembler les adresses IP de proxys résidentiels, nous nous sommes abonnés à plusieurs fournisseurs de proxys résidentiels. Nous avons développé des programmes qui s’exécutent sur notre infrastructure et utilisent ces proxys pour envoyer continuellement des requêtes vers des points de terminaison que nous contrôlons.
Cela nous permet de marquer et de stocker les adresses IP associées aux proxys résidentiels utilisés lors de ces requêtes. Cette approche nous garantit des étiquettes fiables et nous permet d’analyser l’activité liée à ces proxys.
Le schéma ci-dessous illustre le pipeline que nous avons conçu pour collecter des étiquettes de vérité terrain (ground truth) concernant les adresses IP utilisées comme proxys résidentiels.

Grâce à cette méthode, nous disposons en permanence d’un ensemble actualisé d’adresses IP de proxys résidentiels. L’avantage est que nous sommes sûrs à 100 % que ces IPs sont des proxys résidentiels, car nous avons pu faire transiter des requêtes HTTP via ces adresses.
2. Collecte des adresses IP résidentielles non utilisées comme proxys :
Pour construire un jeu de données d’entraînement fiable, nous devons également inclure des adresses IP résidentielles qui ne sont pas utilisées comme proxys. Notre jeu de données négatif (non-proxys) inclut les adresses IP résidentielles qui :
- Ne sont associées à aucun fournisseur de proxys, ET
- Ne correspondent à aucune des heuristiques de détection des proxys résidentiels déjà en place dans notre moteur de détection.
Contrairement à la méthode de collecte des adresses IP de proxys résidentiels, cette approche ne garantit pas des étiquettes 100 % fiables. Il est possible que certaines adresses IP résidentielles soient en réalité des proxys résidentiels cachés dans notre jeu de données négatif.
Cependant, nous faisons l’hypothèse que même s’il existe quelques proxys résidentiels non détectés dans ce jeu de données, leur proportion sera suffisamment faible pour ne pas nuire à l’entraînement du modèle.
Caractéristiques comportementales du modèle ML
Nous avons choisi de développer un modèle supervisé d’apprentissage automatique en nous appuyant sur des caractéristiques comportementales, car l’analyse réalisée par notre équipe de recherche a révélé des différences de comportement significatives entre les proxys résidentiels et les adresses IP utilisées uniquement par des humains, même dans le cas d’IP partagées.
Les principales différences observées sont les suivantes :
- Les proxys résidentiels contactent un grand nombre de sites différents protégés par DataDome, souvent situés dans plusieurs pays.
- En moyenne, une session sur une IP proxy effectue peu de requêtes sur un site donné (cela s’explique par l’utilisation de proxys rotatifs).
- Le trafic provenant des proxys résidentiels affiche une grande diversité d’user-agents.
- Le trafic des proxys résidentiels présente également une variété de langues utilisateur distinctes.
Ces observations sont logiques puisque la majorité des proxys résidentiels sont partagés entre plusieurs bots (en plus des utilisateurs humains légitimes sur la même IP). Les développeurs de bots visent différents sites, utilisent divers user-agents, différentes langues, etc. Par conséquent, le trafic sortant de ces IPs se distingue de celui des adresses IP authentiques, même lorsqu’elles sont partagées.
Nous avons donc décidé de créer un modèle supervisé d’apprentissage automatique basé sur les signaux bruts suivants, agrégés par adresse IP :
- le nombre total de requêtes ;
- le nombre de sites ou applications protégés par DataDome auxquels l’IP a fait une requête ;
- le nombre distinct de user-agents ;
- le nombre distinct de langues utilisateur ;
- l’âge médian de la session.
À partir de ces signaux bruts, nous pouvons dériver des caractéristiques supplémentaires telles que :
- le nombre moyen de requêtes par IP et par site contacté ;
- le ratio entre le nombre de langues par user-agent.
Le tableau ci-dessous résume les principales caractéristiques utilisées par notre modèle ML :
| Caractéristique | Description |
| Nombre de requêtes/IP | Nombre total de requêtes observées pour une adresse IP sur une période donnée. |
| Nombre distinct de sites/IP | Nombre distinct de sites web ou applications protégés par DataDome auxquels l’IP a fait une requête. |
| Nombre distinct de user-agents/IP | Nombre distinct d’en-têtes user-agent observés sur cette adresse IP. |
| Nombre distinct de langues/IP | Nombre distinct d’en-têtes accept-language observés sur cette adresse IP. |
| Âge médian de la session | Âge médian d’une session DataDome en secondes. |
| Ratio : nombre de langues par user-agent | Ratio entre le nombre distinct d’en-têtes accept-language et le nombre distinct de user-agents observés sur l’adresse IP. |
Nous avons pris soin d’éviter toute caractéristique liée directement à la détection de bots, comme le nombre de requêtes bloquées, afin d’éviter de créer une boucle de rétroaction qui pourrait générer des faux positifs à long terme.
Par exemple, si nous avions utilisé une caractéristique comme le pourcentage de requêtes bloquées par IP, cela aurait influencé la prédiction du modèle, augmentant les chances de marquer les IP à fort taux de requêtes suspectes comme des proxys.
Être signalé comme un proxy résidentiel pose problème, car il s’agit d’un signal négatif, ce qui signifie que l’adresse IP marquée est plus susceptible de voir certaines de ses requêtes bloquées.
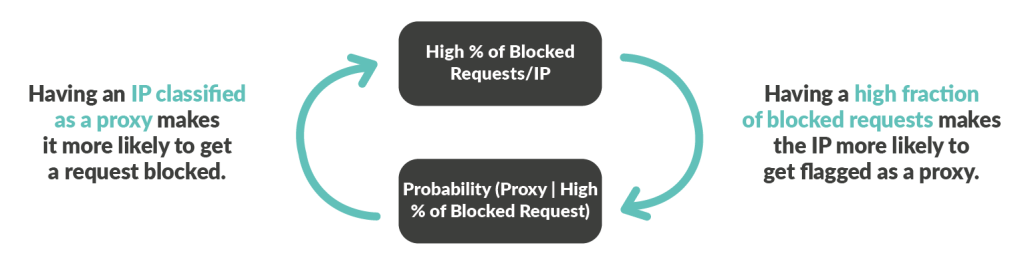
Ainsi, utiliser des caractéristiques directement liées à la détection des bots aurait créé une dépendance négative, qui aurait progressivement dégradé la performance du modèle au fil du temps.
Entraînement du modèle
Nous avons entraîné notre modèle d’apprentissage automatique supervisé en utilisant CatBoost, une bibliothèque open source, sur un sous-ensemble de notre jeu de données (collecté comme décrit précédemment).
Pour optimiser les performances du modèle, nous avons utilisé une grille de recherche afin de déterminer les meilleurs hyperparamètres pour CatBoost et ajuster les paramètres optimaux du modèle. Un paramètre clé est la fenêtre temporelle durant laquelle nous calculons les statistiques comportementales pour chaque adresse IP.
Si la fenêtre temporelle est trop courte, le calcul des caractéristiques sera moins coûteux, mais la performance du modèle en souffrira. À l’inverse, une fenêtre plus longue peut améliorer les performances du modèle (jusqu’à un certain seuil), mais elle est plus coûteuse en termes de calcul.
Après optimisation des hyperparamètres, nous avons identifié que le meilleur compromis entre l’efficacité des ressources et les performances du modèle était une fenêtre temporelle de 12 heures.
Évaluation hors ligne du modèle
Avant qu’un modèle ne soit déployé en production, nous évaluons ses performances hors ligne après chaque phase d’entraînement. Cette évaluation vise à analyser :
- La capacité du modèle à détecter correctement les adresses IP utilisées comme proxys résidentiels (en optimisant la réduction des faux négatifs).
- Tout en évitant de classer à tort les adresses IP résidentielles légitimes comme proxys (en optimisant la réduction des faux positifs).
Pour évaluer la performance globale du modèle, nous utilisons la surface sous la courbe (AUC – Area Under the Curve), qui est un indicateur clé de la qualité du modèle.
Inférence du modèle en production
Nous avons développé un service dédié qui exploite notre modèle d’apprentissage automatique pour détecter en continu si une adresse IP résidentielle a récemment été utilisée comme proxy, en se basant sur son comportement des dernières 12 heures.
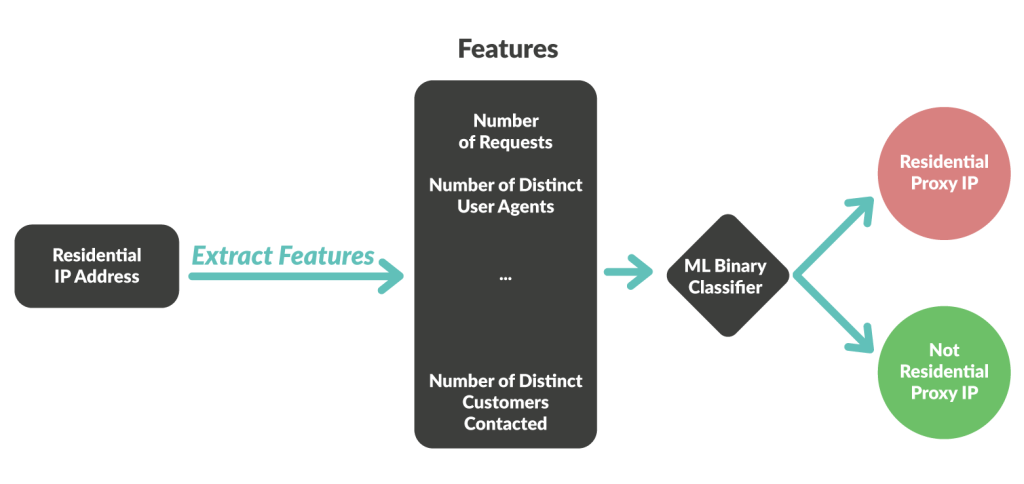
Chaque fois qu’une adresse IP est identifiée comme un proxy résidentiel, cette information est stockée dans une base de données constamment lue par notre moteur de détection. Ainsi, notre moteur de détection bénéficie en temps réel de ces nouvelles informations pour analyser chaque nouvelle requête.
Ces données sont ensuite ajoutées aux requêtes provenant des IP signalées lors de l’étape d’enrichissement des signaux dans notre moteur de détection (illustré dans le schéma ci-dessous). À partir de là, le fait qu’une adresse IP ait été récemment classée comme proxy devient un signal clé pour les autres modèles de détection et règles d’apprentissage automatique, ce qui permet d’ajuster leur niveau d’agressivité.
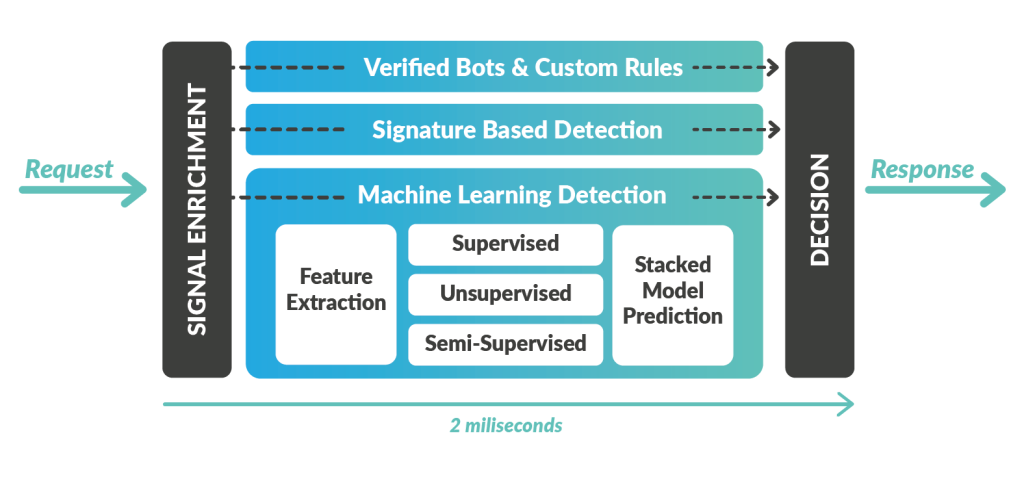
Période de rétention des adresses IP de proxys résidentiels
Une fois qu’une adresse IP a été identifiée comme proxy résidentiel par notre modèle d’apprentissage automatique , il est essentiel de définir la durée pendant laquelle elle doit rester signalée comme telle. Ce paramètre est appelé période de rétention.
Les informations concernant les adresses IP ne sont pas figées. D’une part, plusieurs utilisateurs peuvent partager la même adresse IP. D’autre part, les adresses IP résidentielles sont souvent réaffectées dynamiquement, ce qui signifie qu’un utilisateur légitime pourrait se voir attribuer une adresse IP récemment signalée comme proxy.
Si nous conservons une adresse IP marquée comme proxy résidentiel trop longtemps, nous risquons d’augmenter les faux positifs. À l’inverse, si la durée est trop courte, nous risquons d’augmenter les faux négatifs.
Après avoir affiné la durée de rétention pour obtenir le meilleur compromis entre faux positifs et faux négatifs (exploré plus en détail dans la section suivante), nous avons déterminé qu’une période de rétention de trois jours offrait le meilleur équilibre.
Note : si une adresse IP est de nouveau signalée comme proxy au cours de cette période de trois jours, la durée de rétention est prolongée de trois jours supplémentaires.
Surveillance en ligne du modèle et réentraînement
Les deux principales mesures d’apprentissage automatique que nous surveillons sont :
- les faux négatifs (faciles à mesurer) ;
- les faux positifs (plus difficile à mesurer).
1. Surveillance des faux négatifs
La surveillance des faux négatifs est relativement simple. Nous nous connectons à plusieurs fournisseurs de proxys résidentiels, ce qui nous permet d’évaluer l’efficacité de notre modèle à identifier correctement les adresses IP des proxys que nous utilisons pour nos requêtes.
Faux négatifs (FN) = nombre d’adresses IP de proxys résidentiels incorrectement classées comme des IP résidentielles légitimes / nombre total d’adresses IP de proxys résidentiels
2. Surveillance des faux positifs
La surveillance des faux positifs est plus complexe. En effet, lorsque notre modèle identifie une adresse IP résidentielle comme étant un proxy sans qu’aucun autre modèle de ML ou heuristique ne l’ait signalée auparavant, deux scénarios sont possibles : soit notre modèle a découvert un nouveau proxy, soit il a fait une erreur. Comme il est difficile de vérifier directement si une IP est réellement un proxy, nous ne pouvons pas mesurer le taux de faux positifs de manière directe. Toutefois, nous utilisons une mesure corrélée au taux de faux positifs que nous pouvons mesurer.
L’idée est de comparer les décisions de blocage basées sur les étiquettes générées par notre modèle de détection de proxys résidentiels aux décisions de blocage effectuées à partir des étiquettes de référence (provenant d’adresses IP de proxys que nous savons fiables). Pour cela, nous marquons toutes les adresses IP résidentielles récemment utilisées comme proxys par chaque fournisseur de proxys que nous infiltrons avec un tag spécifique Tproxy_provider_i.
Ensuite, nous définissons un ensemble de règles de blocage pour identifier et bloquer le trafic suspect, signalé par un tag de fournisseur de proxy et correspondant à des signatures spécifiques. Pour chaque fournisseur de proxy que nous infiltrons, nous établissons les règles suivantes :
Règle de blocage pour le fournisseur de proxys A (BPa) :
- Signature1 ET Tproxy_providerA
- Signature2 ET Tproxy_providerA
- Signature3 ET Tproxy_providerA
- …
- SignatureN ET Tproxy_providerA
Règle de blocage pour le fournisseur de proxys B (BPb) :
- Signature1 ET Tproxy_providerB
- Signature2 ET Tproxy_providerB
- Signature3 ET Tproxy_providerB
- …
- SignatureN ET Tproxy_providerB
Règle de blocage pour le fournisseur de proxys Z (BPz) :
- Signature1 ET Tproxy_providerZ
- Signature2 ET Tproxy_providerZ
- Signature3 ET Tproxy_providerZ
- …
- SignatureN ET Tproxy_providerZ
Ces règles permettent de croiser les signatures de comportement du trafic suspect avec les tags des fournisseurs de proxy pour s’assurer que le trafic bloqué est correctement identifié comme étant malveillant.
Ainsi, nous disposons de Z ensembles distincts de règles de blocage, chacun étant associé à un fournisseur de proxy spécifique. Tous ces ensembles utilisent les mêmes signatures de blocage. La seule différence est que chaque ensemble de règles de blocage (BPi) s’applique uniquement aux adresses IP marquées comme proxys et appartenant à un fournisseur de proxy donné (PPi).
De manière similaire, nous créons un autre ensemble de règles de blocage pour les adresses IP signalées comme proxys résidentiels par notre modèle d’apprentissage automatique :
Règles de blocage pour les proxys résidentiels ML (BPml) :
- Signature1 ET Tml_proxy
- Signature2 ET Tml_proxy
- Signature3 ET Tml_proxy
- …
- SignatureN ET Tml_proxy
Cet ensemble de règles utilise les mêmes signatures que celles associées aux proxys résidentiels fournis par des fournisseurs de proxys. La seule différence est qu’il s’applique uniquement aux adresses IP identifiées comme proxys résidentiels par notre modèle d’apprentissage automatique.
Ces règles de blocage sont appliquées à une fraction du trafic. Pour chaque ensemble de règles (BPi), nous surveillons le taux de CAPTCHA résolu en utilisant la formule suivante :
Taux de CAPTCHA résolu = nombre de CAPTCHA résolus par des requêtes bloquées par BPi / nombre de requêtes bloquées par BPi
Ainsi, nous recueillons les données de performance suivantes :
| Modèle de blocage | Taux de réussite CAPTCHA | Temps |
| BPa | 0.0000373333 | t0 |
| BPb | 0.0000134363 | t0 |
| … | … | … |
| BPz | 0.0000514961 | t0 |
| BPml_proxy | 0.0000238363 | t0 |
| … | … | … |
| BPa | 0.0000253633 | tn |
| BPb | 0.0000237313 | tn |
| … | … | … |
| BPz | 0.0000424431 | tn |
| BPml_proxy | 0.0000312343 | tn |
À un instant donné t_i, nous voulons évaluer les performances de notre modèle entre t_i et t_{i-j}, où j correspond à la durée sur laquelle nous mesurons ces performances.
Nous réalisons Z tests statistiques (Z étant le nombre de fournisseurs de proxys) pour mesurer, pour chacun d’entre eux, si les performances de notre modèle d’apprentissage automatique sont significativement différentes de celles du fournisseur de proxy correspondant. Le test statistique utilisé est un test t de Student (ou t-test), qui permet de déterminer si deux ensembles de données (dans ce cas, le taux de réussite des CAPTCHA lié à un fournisseur de proxys et celui lié à notre modèle ML) présentent une différence statistiquement significative au niveau de la moyenne.
Pour chaque t-test, nous utilisons deux ensembles de données :
- Taux de réussite CAPTCHA associé au modèle ML entre t_i et t_{i-j}.
- Taux de réussite CAPTCHA associé au fournisseur de proxys entre t_i et t_{i-j}.
Ainsi, à chaque instant t_i, nous pouvons comparer les performances de notre modèle ML aux données de référence (ground truth) entre t_i et t_{i-j}.
Lorsque les performances de notre modèle ML commencent à se dégrader, elles deviennent souvent inférieures à celles des données de référence. Cela déclenche une alerte, activant automatiquement un réentraînement du modèle à partir de données plus récentes, selon le processus décrit dans la section précédente « Entraînement du modèle ».
Le graphique ci-dessous illustre l’évolution du taux de réussite des CAPTCHA, un indicateur clé pour évaluer la performance du modèle d’apprentissage automatique en détection des proxys résidentiels (ligne verte) par rapport au fournisseur de proxys A (ligne jaune).

En moyenne, nous observons que les schémas de blocage basés sur les prédictions de notre modèle ML engendrent un taux de réussite des CAPTCHA inférieur à celui des schémas liés au fournisseur de proxys A. Cela indique qu’il n’y a pas de différence significative entre la qualité des étiquettes générées par notre modèle ML et celle des étiquettes de référence obtenues en acheminant des requêtes à travers des proxys résidentiels.
Remarque : le fait que le taux de réussite des CAPTCHA soit inférieur avec les étiquettes de notre modèle ML, par rapport aux étiquettes de référence, ne signifie pas nécessairement que notre modèle est supérieur. Le marquage d’une IP comme proxy n’est qu’une étape du processus global de détection des bots. Les adresses IP peuvent être partagées entre des utilisateurs humains et des bots, ou réassignées à des utilisateurs humains à différents intervalles, ce qui peut influer sur la probabilité de générer des faux positifs.
Résultats
Notre modèle supervisé de détection des proxys résidentiels est en production depuis environ un an. Le graphique ci-dessous montre l’évolution du nombre d’adresses IP traitées par notre modèle d’apprentissage automatique au fil du temps (les données sont agrégées par heure).
- Ligne bleue : nombre total d’adresses IP résidentielles signalées comme proxys par notre modèle ML à un instant donné (en prenant en compte la période de rétention de trois jours).
- Ligne verte : nombre d’adresses IP résidentielles traitées par heure par notre modèle (~350 000 IPs/heure).
- Ligne jaune : nombre distinct d’adresses IP résidentielles nouvellement classées comme proxys par heure (~35 000 IPs/heure). Remarque : nous utilisons un cache pour éviter de retraiter les IP récemment classées comme proxys.

Mesurer le trafic bloqué en raison du marquage d’une adresse IP comme proxy résidentiel est un défi. Chaque jour, le moteur de détection de DataDome traite 1 billion de signaux liés aux empreintes serveur et navigateur, au comportement des utilisateurs, à la réputation des IP, et à la réputation des sessions pour prendre ses décisions.
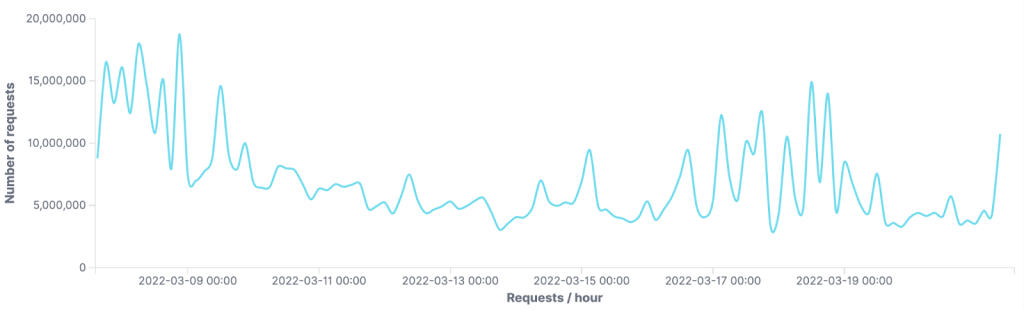
Le graphique ci-dessous montre l’évolution du nombre de requêtes marquées comme provenant de proxys résidentiels par notre modèle ML. En moyenne, nous bloquons environ 7,5 millions de requêtes par heure provenant de proxys résidentiels identifiés par le modèle.
Le tableau ci-dessous présente le nombre de requêtes bloquées, associées aux proxys résidentiels signalés par le modèle ML, sur une période de deux semaines, classées par système autonome.
| Système autonome (AS) | Nombre de requêtes bloquées | Pays |
| Orange | 96,463,055 | France |
| COMCAST-7922 | 60,140,834 | États-Unis |
| ATT-INTERNET4 | 32,369,010 | États-Unis |
| Free SAS | 24,522,304 | France |
| SFR SA | 21,112,281 | France |
| UUNET | 20,047,784 | États-Unis |
| BACOM | 15,866,747 | Canada |
| ROGERS-COMMUNICATIONS | 15,056,092 | Canada |
| CHARTER-20115 | 13,387,401 | États-Unis |
| Bouygues Telecom SA | 11,947,906 | France |
Notre modèle de détection des proxys résidentiels, basé sur l’apprentissage automatique, est particulièrement efficace pour contrer les attaques provenant d’IP dispersées. Le graphique ci-dessous montre le nombre de requêtes bloquées par heure sur la page de connexion d’un de nos clients :
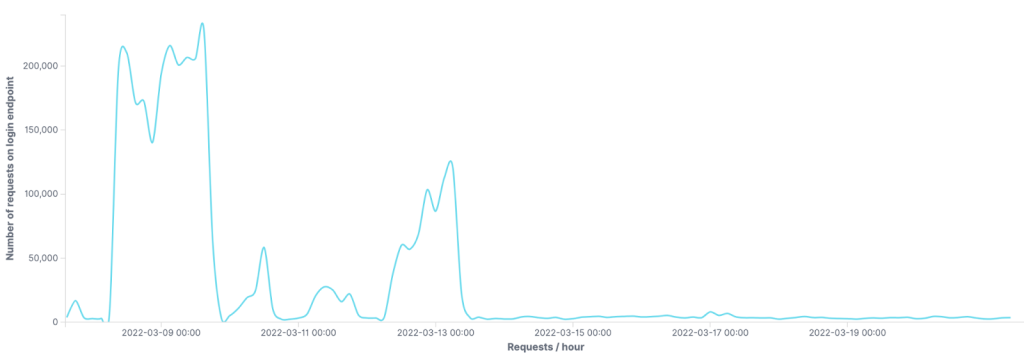
On remarque des pics dans le trafic de bots bloqué, provenant d’adresses IP signalées comme proxys résidentiels par notre modèle d’apprentissage automatique.
Conclusion
L’apprentissage automatique est un outil incontournable pour améliorer la protection contre les bots sophistiqués et la fraude en ligne à grande échelle. Cependant, développer un modèle de ML efficace est bien plus complexe qu’il n’y paraît. Cela nécessite de suivre plusieurs étapes clés : identifier les bons signaux, entraîner le modèle, valider les résultats hors ligne, surveiller les performances en temps réel, et ajuster ou réentraîner le modèle si nécessaire.
Pour garantir une solution performante, il est essentiel que des experts en cybersécurité surveillent, testent, et optimisent continuellement chaque modèle de ML afin de maintenir un faible taux de faux positifs et de faux négatifs.
C’est pourquoi il est crucial de choisir un fournisseur de solutions qui dispose d’une équipe SOC bot dédiée en interne, comme chez DataDome. Cet aperçu du modèle d’apprentissage automatique de DataDome pour l’identification des proxys résidentiels vous a, espérons-le, permis de mieux comprendre les coulisses de l’utilisation du ML dans la protection contre les bots.

Articles liés

DataDome désigné comme leader dans The Forrester Wave™ : Bot And Agent Trust Management Software, Q2 2026
En savoir plus

Que sont les « sneaker bots » ? Comment les détecter et les éviter ?
En savoir plus

Salles d'attente virtuelles : la faille que les bots exploitent
En savoir plus

Comment choisir un système de gestion de file d'attente en ligne
En savoir plus

