




La grande mascarade : comment les agents IA se faufilent
Pendant des décennies, il existait un “gentleman’s agreement” général sur le web concernant le trafic automatisé. Les bons bots (comme les crawlers des moteurs de recherche) s’identifiaient clairement avec des chaînes d’agent utilisateur spécifiques (par exemple, `Googlebot`) et respectaient les règles établies dans robots.txt. Les mauvais bots se faisaient passer pour des utilisateurs légitimes pour extraire du contenu, rechercher des vulnérabilités ou lancer des attaques.
À l’ère de l’IA générative, cette distinction disparaît rapidement.
Poussés par le besoin de répondre instantanément aux demandes des utilisateurs et de contourner un environnement web de plus en plus hostile, certains des agents d’IA les plus avancés au monde abandonnent les protocoles polis. Comme l’a rapporté The Information dans “Inside Web Publishers’ Quest to Stamp Out AI Bots Posing as Humans” les éditeurs luttent maintenant contre une nouvelle vague de crawlers qui masquent leur identité pour passer à travers les défenses.
Ceci n’est pas une tendance isolée. Perplexity AI a récemment fait face à une poursuite d’Amazon pour avoir prétendument usurpé des utilisateurs humains pour contourner les blocages et faciliter ses fonctionnalités d’achat agentiques. De même, Reddit a eu recours à la mise en place d’un piège pour identifier les scrapers de Perplexity, accusés d’ignorer les protocoles d’exclusion standard.
Ces incidents mettent en évidence une réalité croissante : pour obtenir les données dont ils ont besoin, les agents d’IA adoptent les tactiques des acteurs adverses. Une analyse récente des journaux de serveur suite à une simple invite à Grok de xAI illustre de manière frappante cette nouvelle norme.
L’anatomie d’une seule invite
La configuration est simple. Nous avons demandé à Grok via l’interface de chat de récupérer une URL spécifique sur un site web configuré exclusivement à cet effet.
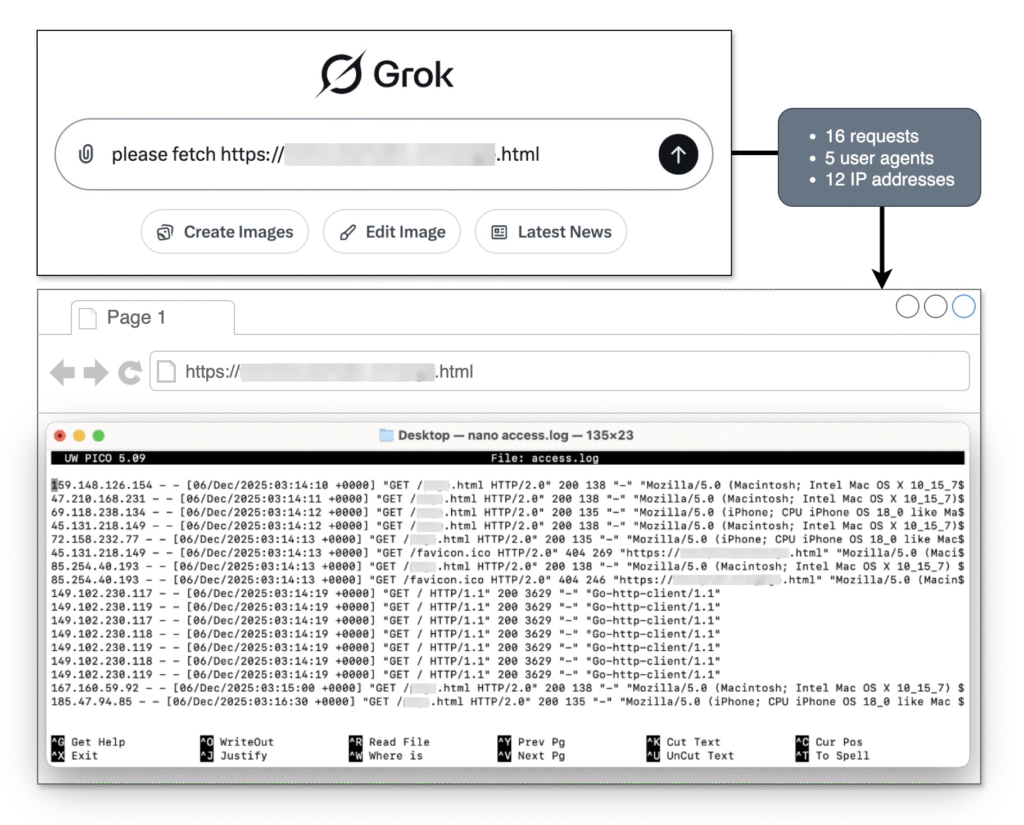
Vous pourriez vous attendre à voir quelques requêtes GET d’un crawler d’IA connu. Plutôt qu’une simple récupération de page, cette interaction unique a déclenché un essaim de requêtes qui ont frappé le site web sous plusieurs angles. Le fichier server access.log a enregistré 16 requêtes distinctes provenant de 12 adresses IP uniques.
Tactique 1 : Le déguisement
L’observation la plus immédiate des journaux est ce qui manquait : le mot “Grok”. Les crawlers d’IA s’identifient généralement par des chaînes d’agent utilisateur afin que les propriétaires de sites web puissent gérer leur accès. Cependant, dans ce cas, aucune requête ne s’est identifiée comme un agent xAI ou Grok.
Au lieu de cela, le trafic se faisait passer pour des utilisateurs humains standard. Grok a alterné entre divers agents utilisateurs courants, y compris différentes versions de Chrome sur macOS et Safari sur un iPhone.
Chaînes d’agent utilisateur:
- Go-http-client/1.1
- Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0 Safari/537.36
- Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/133.0.0.0 Safari/537.36
- Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/139.0.0.0 Safari/537.36
- Mozilla/5.0 (iPhone; CPU iPhone OS 18_0 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/18.0 Mobile/15E148 Safari/604.1
| Extrait d’agent utilisateur | Type | OS | Navigateur |
| Go-http-client/1.1 | Bot/Script | N/A | Go Library |
| Chrome/124.0.0 | Desktop | macOS* | Chrome 124 |
| Chrome/133.0.0.0 | Desktop | macOS* | Chrome 133 |
| Chrome/139.0.0.0 | Desktop | macOS* | Chrome 139 |
| iPhone OS 18_0 | Mobile | iOS 18 | Safari 18 |
Tactique 2 : Récupération agressive et distribuée
Si se faire passer pour un humain est sournois, la tactique suivante est étonnamment directe. Alors que certaines requêtes imitaient le comportement normal du navigateur (comme récupérer un `favicon.ico` après la page principale), un groupe spécifique de trafic se distinguait par son agressivité.
Le site web a été frappé par sept requêtes quasi-simultanées en une seule seconde. Ces requêtes n’utilisaient pas les signatures de navigateur “humaines”; elles utilisaient un agent utilisateur de script générique (`Go-http-client/1.1`). Plus important encore, elles provenaient de trois adresses IP différentes et séquentielles, frappant rapidement le répertoire racine du site.
Ce comportement, des requêtes en rafale lancées en parallèle à partir de plusieurs IP pour sonder un serveur, est très similaire à l’activité générée par des bots malveillants.
| Adresse IP | ASN | Nom ASN (Legacy/Legal) | Catégorie |
| 45.131.218.149 | AS206264 | LONCONNECT LTD | Hébergement |
| 47.210.168.231 | AS19108 | SUDDENLINK-COMMUNICATIONS | Fournisseur d’accès Internet résidentiel |
| 69.118.238.134 | AS6128 | CABLE-NET-1 | Fournisseur d’accès Internet résidentiel |
| 72.158.232.77 | AS6389 | BELLSOUTH-NET-BLK | Fournisseur d’accès Internet résidentiel |
| 85.254.40.193 | AS210906 | UAB Bite Lietuva | Mobile/ISP |
| 149.102.230.117 | AS212238 | DATACAMP-LIMITED | Hébergement |
| 149.102.230.118 | AS212238 | DATACAMP-LIMITED | Hébergement |
| 149.102.230.119 | AS212238 | DATACAMP-LIMITED | Hébergement |
| 159.148.126.154 | AS210906 | UAB Bite Lietuva | Mobile/ISP |
| 167.160.59.92 | AS3257 | GTT Communications | Hébergement |
| 185.47.94.85 | AS210906 | UAB Bite Lietuva | Mobile/ISP |
Pourquoi agir comme un “mauvais bot”?
Pourquoi une plateforme d’IA sophistiquée emploierait-elle des tactiques généralement associées aux mauvais acteurs ? La réponse est probablement la fiabilité par la force brute. Le web moderne est de plus en plus fermé. Les propriétaires de sites veulent bloquer les scrapers d’IA connus pour protéger leur contenu. Pour s’assurer qu’ils peuvent répondre à la demande d’un utilisateur de “récupérer cette page”, l’agent d’IA ne peut pas compter sur une seule requête polie qui pourrait être bloquée.
Au lieu de cela, l’agent emploie une approche “spray and pray”:
- Distribué: Il utilise un réseau distribué pour lancer des requêtes depuis plusieurs points de vue. Si une IP est limitée en débit, d’autres peuvent passer.
- Collecte de contexte: Les requêtes parallèles agressives vers le répertoire racine suggèrent que l’agent ne se contente pas de récupérer la page demandée ; il cartographie rapidement la structure du site pour fournir un contexte à son modèle de langage large (LLM), imitant une méthodologie de “recherche approfondie”.
- Persistance: Les journaux ont montré que l’agent revenait plus de deux minutes plus tard pour une vérification finale, peut-être pour recueillir des informations supplémentaires.
La nouvelle norme pour la défense des sites web
Les implications pour les propriétaires de sites web et les administrateurs de serveurs sont significatives. L’ère où l’on pouvait facilement distinguer entre “crawler IA utile” et “scraper malveillant” est révolue.
Lorsque des services d’IA légitimes adoptent le camouflage et les schémas de requêtes agressives des mauvais bots pour assurer leur propre succès, les défenseurs se retrouvent dans une position difficile.
Les journaux analysés ci-dessus révèlent un tournant critique : la dépendance aux chaînes d’agent utilisateur n’est plus une stratégie de défense viable. Lorsqu’un agent d’IA alterne entre des IP résidentielles et usurpe des signatures de navigateur standard (comme les chaînes iPhone et Mac OS observées dans les requêtes Grok), la protection basée sur des règles héritées devient obsolète. Vous ne pouvez pas bloquer ces requêtes en vous basant uniquement sur les en-têtes sans bloquer les utilisateurs humains légitimes.
Pour contrer ce déguisement, nous employons l’IA pour détecter l’IA. L’un de nos modèles d’IA, Bernoulli, est spécifiquement conçu pour évaluer et classer automatiquement les adresses IP, les systèmes autonomes (ASN) et les agents utilisateurs en fonction de leur comportement observé à travers le trafic mondial de DataDome.
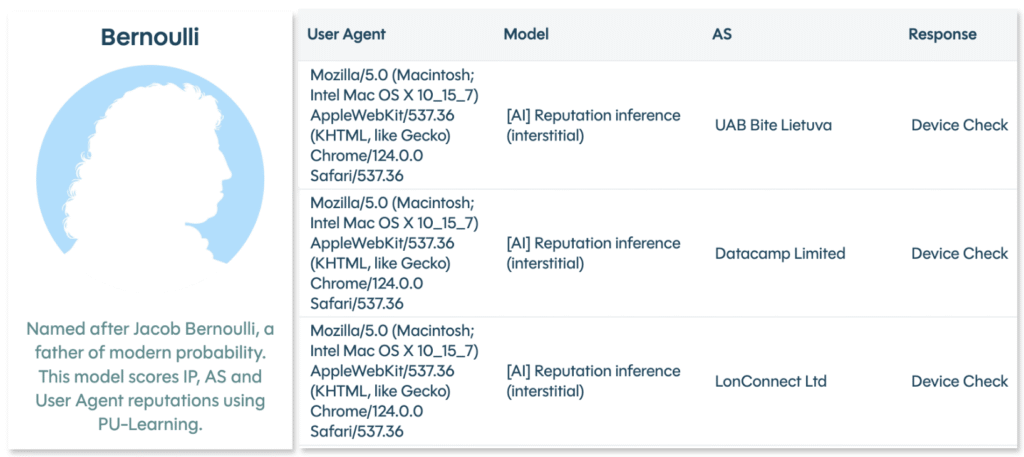
En fin de compte, lorsqu’un agent d’IA ment sur son identité, il invite la résistance qu’il cherche à éviter. En adoptant les schémas de requêtes agressives et le camouflage des acteurs malveillants, les services d’IA légitimes se classent involontairement comme des menaces. Cela déclenche des mécanismes de défense sophistiqués qui vont au-delà du “badge” de l’agent utilisateur et analysent le comportement derrière la requête, entraînant des défis ou des blocages qui dégradent l’expérience utilisateur qu’ils essaient d’optimiser.
Un meilleur chemin à suivre
Le “gentleman’s agreement” du web peut être fracturé, mais il n’a pas à être brisé de façon permanente. Si les agents d’IA revenaient à respecter les protocoles d’authentification en adoptant des normes fiables telles que Web Bot Auth, ils retrouveraient l’opportunité d’être correctement évalués par les propriétaires de sites web.
Jusqu’à ce que cette transparence revienne, la distinction entre un assistant utile et un scraper malveillant restera dangereusement floue. Pour l’instant, la seule défense fiable est un système qui prend ce qu’un bot dit être avec un grain de sel et utilise plusieurs autres points de données pour déduire son intention.
Vous voulez en savoir plus sur la façon de préparer votre entreprise au trafic des agents d’IA ? Téléchargez Le Guide pour Préparer Votre Entreprise au Commerce Agentique.

Articles liés

Libération utilise DataDome + Arc XP pour neutraliser le scraping IA malveillant en moins de 2 millisecondes
En savoir plus

DataDome désigné comme leader dans The Forrester Wave™ : Bot And Agent Trust Management Software, Q2 2026
En savoir plus
La page d'accueil de DataDome : votre centre de commande pour la confiance & le contrôle
En savoir plus

Comment les éditeurs de navigateurs rendent discrètement l'automatisation plus difficile à détecter
En savoir plus

