




The Great Masquerade: How AI Agents Are Spoofing Their Way In
For decades, there was a general “gentleman’s agreement” on the web regarding automated traffic. Good bots (like search engine crawlers) identified themselves clearly with specific user agent strings (e.g., `Googlebot`) and respected rules laid out in robots.txt. Bad bots masqueraded as legitimate users to scrape content, probe for vulnerabilities, or launch attacks.
In the age of generative AI, that distinction is rapidly vanishing.
Driven by the need to fulfill user requests instantly and bypass an increasingly hostile web environment, some of the world’s most advanced AI agents are abandoning polite protocols. As reported by The Information in “Inside Web Publishers’ Quest to Stamp Out AI Bots Posing as Humans” publishers are now fighting a new wave of crawlers that mask their identities to slip past defenses.
This is not an isolated trend. Perplexity AI recently faced a lawsuit from Amazon for allegedly spoofing human users to bypass blocks and facilitate its agentic shopping features. Similarly, Reddit resorted to setting a trap to identify Perplexity’s scrapers, which were accused of ignoring standard exclusion protocols.
These incidents highlight a growing reality: to get the data they need, AI agents are adopting the tactics of adversarial actors. A recent analysis of server logs following a simple prompt to xAI’s Grok provides a stark illustration of this new normal.
The anatomy of a single prompt
The setup is simple. We asked Grok via the chat interface to fetch a specific URL on a website set up exclusively for that purpose.
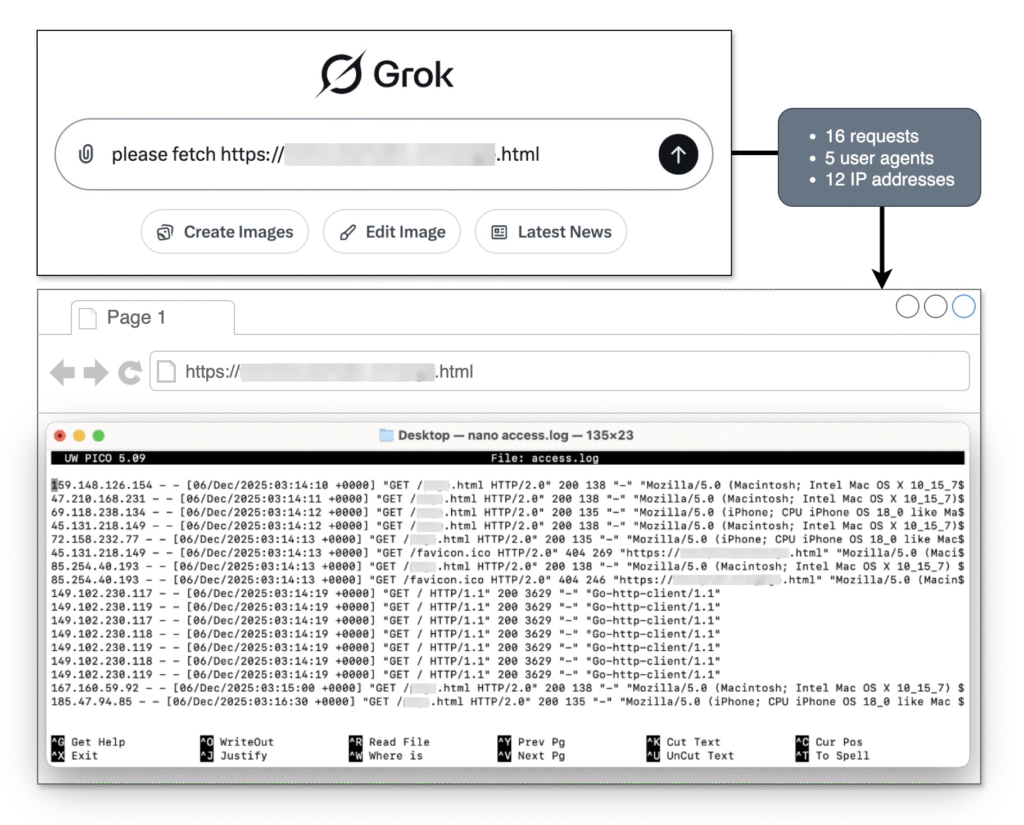
You might expect to see a couple of GET requests from a known AI crawler. Rather than a simple page fetch, this single interaction triggered a swarm of requests that hit the website from multiple angles. The server access.log file recorded 16 distinct requests originating from 12 unique IP addresses.
Tactic 1: The masquerade
The most immediate observation from the logs is what was missing: the word “Grok”. AI crawlers generally identify themselves through user agent strings so website owners can manage their access. However, in this instance, not a single request identified itself as an xAI or Grok agent.
Instead, the traffic masqueraded as standard human users. Grok rotated through various common user agents, including different versions of Chrome on macOS and Safari on an iPhone.
User agent strings:
- Go-http-client/1.1
- Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0 Safari/537.36
- Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/133.0.0.0 Safari/537.36
- Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/139.0.0.0 Safari/537.36
- Mozilla/5.0 (iPhone; CPU iPhone OS 18_0 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/18.0 Mobile/15E148 Safari/604.1
| User Agent Snippet | Type | OS | Browser |
| Go-http-client/1.1 | Bot/Script | N/A | Go Library |
| Chrome/124.0.0 | Desktop | macOS* | Chrome 124 |
| Chrome/133.0.0.0 | Desktop | macOS* | Chrome 133 |
| Chrome/139.0.0.0 | Desktop | macOS* | Chrome 139 |
| iPhone OS 18_0 | Mobile | iOS 18 | Safari 18 |
Tactic 2: Aggressive, distributed fetching
If masquerading as a human is sneaky, the next tactic is surprisingly blunt. While some requests mimicked regular browser behavior (like fetching a `favicon.ico` after the main page), a specific cluster of traffic stood out as highly aggressive.
The website was hit by seven near-simultaneous requests in a single second. These requests didn’t use the “human” browser signatures; they used a generic script user agent (`Go-http-client/1.1`). More importantly, they originated from three different, sequential IP addresses, rapidly hitting the root directory of the site.
This behavior, rapid-fire requests launched in parallel across multiple IPs to probe a server, is quite similar to the activity generated by malicious bots.
| IP Address | ASN | ASN Name (Legacy/Legal) | Category |
| 45.131.218.149 | AS206264 | LONCONNECT LTD | Hosting |
| 47.210.168.231 | AS19108 | SUDDENLINK-COMMUNICATIONS | Residential ISP |
| 69.118.238.134 | AS6128 | CABLE-NET-1 | Residential ISP |
| 72.158.232.77 | AS6389 | BELLSOUTH-NET-BLK | Residential ISP |
| 85.254.40.193 | AS210906 | UAB Bite Lietuva | Mobile/ISP |
| 149.102.230.117 | AS212238 | DATACAMP-LIMITED | Hosting |
| 149.102.230.118 | AS212238 | DATACAMP-LIMITED | Hosting |
| 149.102.230.119 | AS212238 | DATACAMP-LIMITED | Hosting |
| 159.148.126.154 | AS210906 | UAB Bite Lietuva | Mobile/ISP |
| 167.160.59.92 | AS3257 | GTT Communications | Hosting |
| 185.47.94.85 | AS210906 | UAB Bite Lietuva | Mobile/ISP |
Why act like a “bad bot”?
Why would a sophisticated AI platform employ tactics usually associated with bad actors? The answer is likely reliability through brute force. The modern web is increasingly walled off. Site owners want to block known AI scrapers to protect their content. To ensure they can fulfill a user’s request to “fetch this page,” the AI agent cannot rely on a single, polite request that might get blocked.
Instead, the agent employs a “spray and pray” approach:
- Distributed: It utilizes a distributed network to launch requests from multiple vantage points. If one IP is rate-limited, others might get through.
- Context Gathering: The aggressive parallel requests to the root directory suggest the agent isn’t just fetching the requested page; it is rapidly mapping the site’s structure to provide context for its Large Language Model (LLM), mimicking a “deep search” methodology.
- Persistence: The logs showed the agent returning over two minutes later for a final check, perhaps to gather additional context.
The new normal for website defense
The implications for website owners and server administrators are significant. The era of easily distinguishing between “helpful AI crawler” and “malicious scraper” is over.
When legitimate AI services adopt the camouflage and aggressive request patterns of bad bots to ensure their own success, defenders are left in a difficult position.
The logs analyzed above reveal a critical turning point: reliance on user agent strings is no longer a viable defense strategy. When an AI agent rotates through residential IPs and spoofs standard browser signatures (like the iPhone and Mac OS strings observed in the Grok requests) legacy rules-based protection becomes obsolete. You cannot block these requests based on headers alone without blocking legitimate human users.
To counter this masquerade, we employ AI to detect AI. One of our AI models, Bernoulli, is specifically designed to automatically score and classify IP addresses, autonomous systems (ASNs), and user agents based on their observed behavior across DataDome’s global traffic.
Ultimately, when an AI agent lies about its identity, it invites the very resistance it seeks to avoid. By adopting the aggressive request patterns and camouflage of malicious actors, legitimate AI services inadvertently classify themselves as threats. This triggers sophisticated defense mechanisms that look beyond the “name tag” of the User Agent and analyze the behavior behind the request, resulting in challenges or blocks that degrade the user experience they are trying to optimize.
A better path forward
The “gentleman’s agreement” of the web may be fractured, but it doesn’t have to be broken permanently. If AI agents pivoted back toward respecting authentication protocols by adopting reliable standards such as Web Bot Auth, they would regain the opportunity to be correctly assessed by website owners.
Until that transparency returns, the distinction between a helpful assistant and a malicious scraper will remain dangerously blurred. For now, the only reliable defense is a system that takes what a bot says it is with a grain of salt and leverages multiple other data points to deduce its intent.
Want to learn more about how to ready your business for AI agent traffic? Download The Guide to Readying Your Business for Agentic Commerce.

Related posts

The AI Traffic Report Q2 2026: Agentic Traffic Surged 45%, With Meta Taking the Lead
Tell me more

Q2 2026 Product Roundup: Agent Trust, Priority Protect, & More
Tell me more

The Agentic Threats & Industry Trends Defining 2026 (So Far)
Tell me more

Libération Leverages DataDome + Arc XP to Neutralize Malicious AI Scraping in <2 Milliseconds
Tell me more

