




Authentification et autorisation des agents d’IA : guide de sécurité
Les agents IA font maintenant des achats, des réservations et des transactions au nom des utilisateurs. Mais comment les systèmes vérifient-ils que ces agents sont légitimes ? Et une fois vérifiés, que devraient-ils être autorisés à faire ? L’authentification des agents d’IA confirme leur identité. L’autorisation des agents d’IA contrôle l’accès. Ensemble, ils forment le fondement de la sécurité pour l’ère agentique.
Points clés
- L’authentification des agents d’IA confirme l’identité de l’agent faisant une demande. L’autorisation des agents d’IA détermine ce que cet agent peut réellement faire.
- Les protocoles standards comme OAuth 2.1 et mTLS fournissent une authentification sécurisée de machine à machine, tandis que MCP (Model Context Protocol) émerge comme la norme pour les interactions des agents.
- Les modèles de sécurité traditionnels axés sur les humains ne se traduisent pas pour les agents autonomes. De nouveaux cadres comme Agent Trust sont nécessaires.
- L’accès au moindre privilège et la vérification comportementale en temps réel sont essentiels pour gérer les permissions des agents autonomes.
Qu’est-ce que l’authentification des agents d’IA ?
L’authentification des agents d’IA est le processus de vérification de l’identité d’un agent d’IA avant qu’il ne puisse accéder à des systèmes, des API ou des données. Elle répond à une question simple : cet agent est-il vraiment qui (ou ce qu’) il prétend être ?
Contrairement à l’authentification humaine, où vous pourriez entrer un mot de passe ou scanner votre empreinte digitale, les agents d’IA ont besoin de justificatifs d’identité machine-à-machine. Ceux-ci incluent généralement des clés cryptographiques, des certificats ou des jetons qui prouvent l’identité de l’agent sans intervention humaine.
Les enjeux sont importants. Lorsqu’un agent IA réserve un voyage, traite des paiements ou accède à des données clients en votre nom, le système récepteur doit avoir la certitude absolue que la demande provient d’une source autorisée, et non d’un acteur malveillant se faisant passer pour un agent légitime.
Qu’est-ce que l’autorisation des agents d’IA ?
Alors que l’authentification confirme l’identité, l’autorisation des agents d’IA détermine ce qu’un agent authentifié peut réellement faire. C’est la différence entre franchir la porte d’entrée et être autorisé à entrer dans toutes les pièces du bâtiment. L’autorisation définit :
- quelles API un agent peut appeler ;
- quelles données il peut lire, écrire ou modifier ;
- quelles actions il peut exécuter ;
- à quelles ressources il peut accéder.
Pour les agents IA autonomes, l’autorisation devient particulièrement critique. Un agent réservant un vol ne devrait pas avoir accès à vos dossiers médicaux. Un agent de service client ne devrait pas pouvoir traiter des remboursements au-dessus d’un certain montant sans approbation humaine.
Pourquoi la sécurité des agents d’IA est-elle importante aujourd’hui ?
L’urgence autour de l’authentification et de l’autorisation des agents n’est pas théorique. Plusieurs tendances convergentes en font une préoccupation commerciale pressante.
L’IA agentique se développe rapidement
Selon Gartner, 33 % des applications logicielles d’entreprise incluront l’IA agentique d’ici 2028, contre moins de 1 % en 2024.¹ Cette projection s’étend aux flux de travail individuels : au moins 15 % des décisions de travail quotidiennes seront prises de manière autonome par l’IA agentique d’ici 2028.
L’opportunité commerciale est massive
McKinsey estime que le commerce agentique (achats alimentés par des agents d’IA) pourrait orchestrer jusqu’à 1 000 milliards de dollars de revenus de détail aux États-Unis d’ici 2030, avec des projections mondiales atteignant 3 à 5 000 milliards de dollars.² Les principaux acteurs, dont OpenAI, Google, Stripe et Shopify, construisent déjà l’infrastructure agent-commerçant.
Les risques de sécurité augmentent
Gartner prévoit qu’en 2028, 25 % des violations d’entreprise seront attribuées à l’abus d’agents d’IA, tant par des attaquants externes que par des acteurs internes malveillants.3 La surface de menace s’élargit considérablement lorsque les agents peuvent initier des chaînes d’événements et d’interactions qui ne sont pas visibles pour les opérateurs humains.
Méthodes d’authentification pour les agents d’IA
Les organisations disposent de plusieurs approches éprouvées pour authentifier les agents IA, chacune avec des compromis distincts.
OAuth 2.1 avec identifiants client
OAuth 2.1 devient la norme pour l’authentification des agents d’IA, en particulier pour ceux qui doivent accéder à des ressources protégées au nom des utilisateurs. Le flux d’identifiants client attribue à chaque agent un identifiant client et un secret uniques, générant des jetons d’accès de courte durée.
Comment ça fonctionne :
- L’agent présente des identifiants au serveur d’autorisation
- Le serveur valide les identifiants et renvoie un jeton d’accès
- L’agent utilise le jeton pour accéder aux ressources protégées
- Le jeton expire, l’agent en demande un nouveau
Idéal pour : Les agents opérant dans des environnements basés sur le web, accédant à des API ou interagissant avec des plateformes SaaS.
La spécification du Model Context Protocol (MCP), initialement introduite par Anthropic, impose OAuth 2.1 pour l’autorisation. Cela devient rapidement la norme pour la manière dont les agents d’IA interagissent avec des outils et ressources externes.
Mutual TLS (mTLS)
Le Mutual TLS fournit une authentification bidirectionnelle où l’agent et le service vérifient mutuellement leur identité à l’aide de certificats X.509. Contrairement au TLS standard où seul le serveur prouve son identité, le mTLS exige que les deux parties présentent des certificats.
Idéal pour : les environnements à haute sécurité, les services financiers, les soins de santé et les scénarios où la vérification de confiance bidirectionnelle est critique.
Compromis : plus complexe à mettre en œuvre et à gérer à grande échelle. La rotation et la révocation des certificats nécessitent des processus opérationnels soigneux.
Clés API et jetons
La méthode d’authentification la plus simple : chaque agent reçoit une clé unique qu’il présente à chaque requête.
Idéal pour : les systèmes internes, les opérations à faible risque ou les environnements de développement.
Limitation critique : les clés API offrent une sécurité faible pour les systèmes agentiques en production. Ce sont des identifiants statiques qui peuvent être volés, difficiles à délimiter, et qui ne fournissent pas le contrôle granulaire nécessaire pour les agents autonomes.
Modèles d’autorisation pour les agents d’IA
Une fois qu’un agent est authentifié, les cadres d’autorisation déterminent quelles actions il peut entreprendre.
Contrôle d’accès basé sur les rôles (RBAC)
Le RBAC regroupe les autorisations en rôles prédéfinis (admin, éditeur, spectateur) attribués aux agents. Un agent de support obtient le rôle “support” avec des capacités prédéfinies ; un agent de déploiement obtient le rôle “déployeur”.
Forces: simple à comprendre et à auditer. Fonctionne bien pour des fonctions d’agent clairement définies.
Limites: peut conduire à une accumulation des autorisations. A du mal avec les scénarios dynamiques et dépendants du contexte.
Contrôle d’accès basé sur les attributs (ABAC)
L’ABAC évalue plusieurs attributs avant d’accorder l’accès : identité de l’agent, sensibilité des ressources, heure de la journée, modèles de comportement récents, contexte de la tâche actuelle. Par exemple : “Autoriser l’accès aux données des clients uniquement pendant les heures de bureau, uniquement pour les clients qui ont opté pour le support IA, et uniquement si le comportement récent de l’agent correspond aux modèles attendus.”
Forces: très flexible et conscient du contexte. Peut implémenter une logique métier complexe.
Limites: plus difficile à auditer et à déboguer. Nécessite une gestion robuste des attributs.
Contrôle d’accès basé sur les relations (ReBAC)
Le ReBAC détermine l’accès en fonction des relations entre les entités. Un agent peut accéder à un document si l’utilisateur qu’il représente possède ce document, ou si l’utilisateur appartient à une équipe qui le partage.
Idéal pour: systèmes multi-locataires, environnements collaboratifs, scénarios où l’accès dépend des structures organisationnelles
Le cadre d’autorisation MCP
Le Model Context Protocol est devenu une norme critique pour les interactions des agents d’IA. Comprendre son modèle d’autorisation est essentiel pour quiconque construit ou sécurise des systèmes agentiques, et la sécurité MCP devient une discipline dédiée à mesure que l’adoption s’accélère.
Comment fonctionne l’autorisation MCP
Les serveurs MCP agissent comme des serveurs de ressources OAuth 2.1, acceptant les demandes de ressources protégées à l’aide de jetons d’accès. Lorsqu’un agent d’IA (client MCP) a besoin d’accéder à une ressource protégée:
- L’agent fait une demande initiale au serveur MCP
- Le serveur répond avec 401 Non autorisé, fournissant un lien de découverte
- L’agent découvre le serveur d’autorisation et les portées requises
- L’agent initie le flux de code d’autorisation OAuth 2.1 avec PKCE
- Après le consentement de l’utilisateur, l’agent reçoit un jeton d’accès
- L’agent présente le jeton pour accéder aux ressources
Ce flux garantit que les agents peuvent découvrir dynamiquement les exigences d’autorisation à travers des systèmes hétérogènes, ce qui est crucial pour les agents qui interagissent avec des milliers d’API inconnues.
Pourquoi PKCE est important
Le Proof Key for Code Exchange (PKCE) est obligatoire dans OAuth 2.1 et essentiel pour les contextes MCP. De nombreux agents d’IA fonctionnent dans des environnements où il est difficile de stocker des secrets en toute sécurité : conteneurs, fonctions sans serveur ou systèmes distribués.
Le PKCE permet aux clients publics d’utiliser le flux de code d’autorisation en toute sécurité sans dépendre d’un secret client, réduisant ainsi le risque d’interception de jetons. Il lie le code d’autorisation au client spécifique qui l’a demandé.
Comment authentifier un agent d’IA étape par étape
La mise en place d’une authentification robuste des agents nécessite une attention systématique à chaque composant.
1. Établir des identités d’agent uniques
Chaque agent a besoin d’une identité unique et vérifiable. Cela signifie :
- émettre des identifiants clients uniques et des informations d’identification à chaque instance d’agent ;
- enregistrer les agents dans votre système de gestion des identités ;
- créer des conventions de nommage claires et des métadonnées pour le suivi.
Ne pas : partager les informations d’identification entre plusieurs agents. Si l’un est compromis, tous le sont.
2. Mettre en œuvre l’authentification machine à machine (M2M)
Configurez votre fournisseur d’identité pour le flux d’informations d’identification client OAuth 2.0 :
- enregistrez chaque agent en tant que client OAuth ;
- émettez un ID client et un secret client (ou un certificat pour mTLS) ;
- configurez les portées et les autorisations appropriées ;
- définissez des politiques d’expiration des jetons (plus court est plus sûr).
3. Sécuriser le stockage et la rotation des informations d’identification
Les informations d’identification des agents nécessitent la même protection que celles des humains, voire plus, car elles ont souvent un accès plus large :
- stocker les informations d’identification dans des systèmes de gestion des secrets (HashiCorp Vault, AWS Secrets Manager) ;
- mettre en œuvre une rotation automatisée des informations d’identification ;
- ne jamais coder en dur les informations d’identification dans le code de l’agent ;
- surveiller l’utilisation des informations d’identification pour détecter les anomalies.
4. Configurer la gestion du cycle de vie des jetons
Les jetons d’accès doivent être :
- de courte durée (minutes à heures, pas des jours),
- limités à des ressources et actions spécifiques,
- automatiquement rafraîchis si nécessaire,
- immédiatement révocables si un agent est compromis.
5. Mettre en œuvre des protocoles de découverte
Pour les environnements dynamiques, les agents doivent découvrir automatiquement les exigences d’autorisation. Mettre en place :
- OAuth 2.0 Authorization Server Metadata (RFC 8414),
- métadonnées des ressources protégées (RFC 9728),
- enregistrement dynamique des clients (RFC 7591) le cas échéant.
Bonnes pratiques pour autoriser les agents d’IA
Définir des autorisations granulaires et spécifiques aux tâches
Au lieu d’attributions de rôles larges, créez des ensembles de capacités précises liées à des fonctions commerciales spécifiques.
- Un agent de support doit avoir un accès en lecture aux profils clients, la permission de créer des tickets et l’accès à la base de connaissances. Rien de plus.
- Un agent de déploiement a besoin de la capacité d’exécuter des builds, d’accéder aux journaux et de déployer dans des environnements de staging, mais ne devrait pas toucher aux données clients.
- Un agent d’analyse peut lire des données agrégées, générer des rapports et accéder aux tableaux de bord, mais ne devrait pas avoir de permissions d’écriture nulle part.
La clé est de mapper chaque permission à un besoin commercial spécifique et justifié. Lorsque vous ne pouvez pas expliquer pourquoi un agent a besoin d’une capacité particulière, il ne l’a probablement pas.
Mettre en œuvre une autorisation contextuelle
Les permissions statiques ne tiennent pas compte des conditions commerciales dynamiques. Les politiques d’autorisation doivent évaluer plusieurs facteurs en temps réel : le contexte de la tâche actuelle, le niveau de sensibilité des données demandées, les facteurs de temps et de localisation, l’historique comportemental récent de l’agent et si l’utilisateur a donné son consentement explicite pour ce type d’action.
Cette approche permet des politiques comme « autoriser l’accès aux données clients uniquement pendant les heures de bureau, uniquement pour les clients qui ont opté pour le support IA, et uniquement si le comportement récent de l’agent correspond aux modèles attendus. » L’autorisation contextuelle détecte des scénarios que les attributions de rôles statiques manquent complètement.
Définir des fenêtres d’accès limitées dans le temps
Les agents avec des privilèges élevés ne devraient pas conserver ces privilèges en permanence. Accorder l’accès au déploiement uniquement pendant les fenêtres de publication programmées. Définir des permissions élevées temporaires qui expirent automatiquement après une période définie. Exiger une ré-autorisation pour les opérations sensibles plutôt que de permettre un accès indéfini basé sur une seule approbation.
La limitation temporelle des permissions réduit la fenêtre de potentiel abus, que ce soit d’un agent compromis ou d’un agent opérant simplement en dehors de son champ d’application prévu.
Concevoir pour des conditions avec intervention humaine
Tout ne devrait pas être automatisé. Définir des seuils d’escalade clairs où l’autonomie de l’agent s’arrête pour une approbation humaine : transactions financières au-dessus d’un certain montant, actions qui affectent les données clients, décisions avec des implications de conformité et opérations dans des environnements de production.
Construire des flux de travail d’approbation qui arrêtent l’exécution de l’agent jusqu’à ce que l’autorisation humaine soit reçue. Le but n’est pas de tout ralentir. C’est de s’assurer que les humains restent en contrôle des décisions à enjeux élevés tandis que les agents gèrent les opérations de routine de manière autonome.
Surveiller et auditer en continu
L’autorisation n’est pas à définir et à oublier. Consigner chaque vérification de permission et décision d’accès. Suivre les modèles d’activité des agents au fil du temps pour établir des bases comportementales. Alerter sur l’utilisation anormale des permissions qui dévie de ces bases. Examiner et élaguer régulièrement les permissions inutilisées. Si un agent n’a pas utilisé une capacité depuis des mois, il n’en a probablement pas besoin.
La surveillance continue transforme l’autorisation d’une barrière ponctuelle en un processus de vérification continue.
L’approche de DataDome pour sécuriser les agents d’IA
La détection traditionnelle des bots a évolué à partir de l’identification d’un trafic automatisé simple. L’ère agentique exige quelque chose de fondamentalement différent : vérifier non seulement qui agit, mais pourquoi et comment.
Et le défi s’étend au-delà des systèmes agentiques sophistiqués. Les organisations doivent également gérer les robots d’indexation des LLM, qui récoltent du contenu pour les données d’entraînement, et bloquer les bots IA qui automatisent les attaques à grande échelle, tout en permettant aux agents légitimes de fonctionner librement.
Le cadre de confiance des agents de DataDome aborde cela par la vérification en temps réel de :
- l’identité : vérification cryptographique des identifiants des agents ;
- l’intention : analyse comportementale pour détecter si les actions des agents correspondent à l’objectif déclaré ;
- l’autorisation : application dynamique des permissions en fonction du contexte.
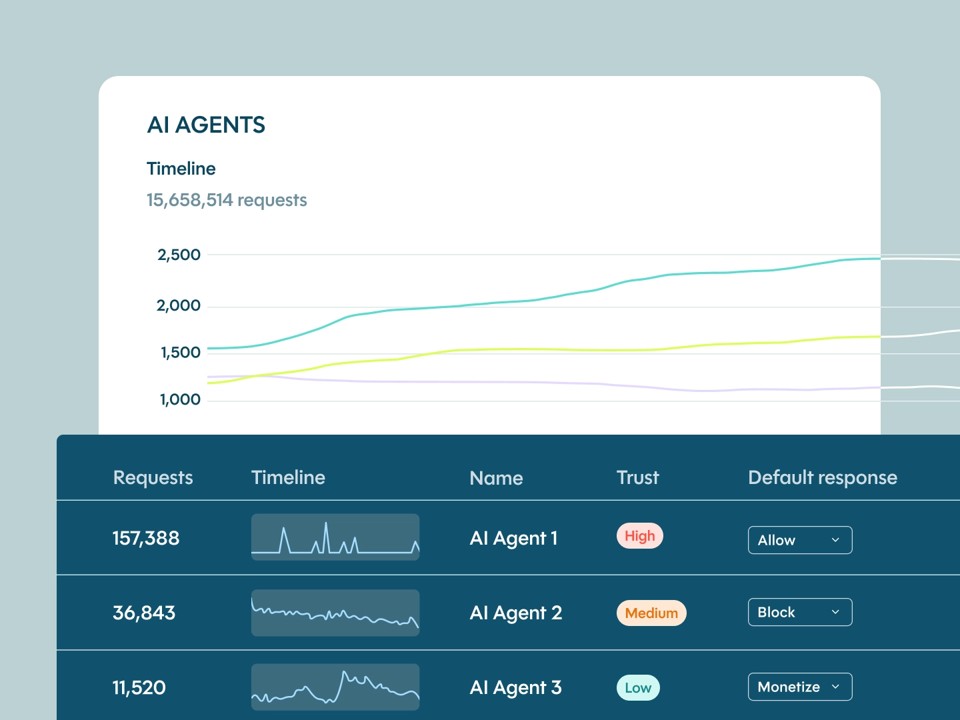
Voyez clairement le trafic de vos agents d’IA, faites confiance aux bons agents et bloquez automatiquement les mauvais.
Pour les organisations construisant ou consommant des systèmes basés sur MCP, la protection MCP de DataDome fournit une sécurité pour les points d’accès Model Context Protocol, ce qui garantit que les agents d’IA accédant à vos outils et données sont légitimes, autorisés et se comportent de manière appropriée.
Le différenciateur clé : la confiance n’est pas binaire. L’approche de DataDome fournit une évaluation continue de la confiance basée sur le comportement qui s’ajuste en quelques millisecondes en fonction des signaux d’intention, et pas seulement sur une authentification unique à l’entrée.
Conclusion
L’authentification et l’autorisation des agents d’IA sont des exigences fondamentales pour toute organisation déployant une IA autonome. À mesure que les agents traitent plus de transactions, prennent plus de décisions et accèdent à des systèmes plus sensibles, l’infrastructure de sécurité qui les soutient doit être tout aussi sophistiquée.
La technologie pour le faire existe déjà. OAuth 2.1, MCP et les modèles de contrôle d’accès établis fournissent les éléments de base. Le défi réside dans la mise en œuvre : concevoir des systèmes qui équilibrent l’autonomie des agents avec des contrôles appropriés, la supervision humaine avec l’efficacité opérationnelle.
Les organisations qui réussissent cela captureront les gains de productivité de l’IA agentique tout en gérant les risques. Celles qui ne le font pas font face à un avenir où leurs outils les plus puissants deviennent leurs plus grandes vulnérabilités.
La plateforme de gestion de la confiance des agents de DataDome aide les entreprises à vérifier l’identité, l’intention et l’autorisation des agents d’IA en temps réel, afin que vous puissiez adopter le commerce agentique sans compromettre la sécurité. Demandez une démo pour voir comment cela fonctionne.
FAQ
Mettre en place une défense en profondeur : autorisations au moindre privilège, accès limité dans le temps, surveillance comportementale et coupe-circuits qui arrêtent l’activité suspecte. Partir du principe que les agents peuvent être compromis et concevoir le confinement en conséquence. Limiter le rayon d’impact par la segmentation et garantir des capacités de révocation rapide des identifiants.
Enregistrer chaque événement d’authentification, vérification d’autorisation et action significative. Suivre les modèles comportementaux au fil du temps pour établir des références. Utiliser la détection d’anomalies pour signaler les déviations. Garantir que les journaux d’audit sont inviolables et soutiennent l’investigation criminalistique lorsque des incidents se produisent.
Références
- https://www.gartner.com/en/articles/ai-agents
- https://www.mckinsey.com/capabilities/quantumblack/our-insights/the-agentic-commerce-opportunity-how-ai-agents-are-ushering-in-a-new-era-for-consumers-and-merchants
- https://www.gartner.com/en/newsroom/press-releases/2024-10-22-gartner-unveils-top-predictions-for-it-organizations-and-users-in-2025-and-beyond

Articles liés

Les attaques contre les plateformes de paris sportifs s'intensifient à l'approche de la Coupe du monde de la FIFA 2026
En savoir plus

Libération utilise DataDome + Arc XP pour neutraliser le scraping IA malveillant en moins de 2 millisecondes
En savoir plus

Présentation de Proof of Browser: comment DataDome a bloqué 14 millions de tentatives de contournement
En savoir plus

DataDome désigné comme leader dans The Forrester Wave™ : Bot And Agent Trust Management Software, Q2 2026
En savoir plus

