




Comment les scraper bots nuisent à votre SEO
Le référencement naturel (SEO) est un art complexe, difficile à maîtriser en raison des changements fréquents des attentes et des meilleures pratiques. Cependant, deux aspects du SEO restent constants :
- Le contenu dupliqué nuit au SEO.
- Les performances rapides du site sont récompensées dans les classements des moteurs de recherche.
Malheureusement, ces deux facteurs fondamentaux du SEO peuvent être sérieusement affectés par les scraper bots, souvent avant même que vous ne réalisiez qu’ils ciblent votre site web ou application mobile.
Nous avons constaté qu’un concurrent nous battait pour un résultat de recherche particulier et découvert qu’il le faisait en volant notre contenu. Nous avons alors émis un avis de retrait, mais tout cela n’était que réactif. En fait, nous n’avions aucune idée de l’ampleur de notre problème de scraping.
– Bill Salak, CTO chez Brainly
Lorsqu’ils sont utilisés à des fins malveillantes, les scraper bots peuvent permettre à des concurrents et/ou des fraudeurs de voler votre contenu, vos prix et d’autres informations propriétaires. Mais même les scrapers « inoffensifs » (comme les bots utilisés pour des recherches) peuvent entraîner des pics de trafic inattendus, augmentant ainsi les coûts d’infrastructure, ralentissant le chargement des pages, voire provoquant des pannes de votre site ou application.
Alors, comment empêcher les scrapers de nuire à votre référencement tout en permettant aux bots « amicaux » comme ceux de Google de parcourir votre site ? Continuez à lire pour le savoir.
Ce que nous allons aborder :
Quelle est la différence entre un bon et un mauvais bot ?
La première chose à comprendre est simple : l’automatisation n’est pas l’ennemi. Tous les bots ne sont pas nuisibles. L’automatisation et les bots sont des outils que les humains utilisent pour accomplir des tâches plus efficacement. Ce sont les intentions des développeurs et des utilisateurs de ces bots qui déterminent s’ils seront utilisés à bon ou à mauvais escient.
Mais qu’est-ce qui fait qu’un bot est « bon » ou « mauvais » ?
Dans certains cas, les « mauvais » bots sont faciles à identifier, comme ceux utilisés pour des fraudes en ligne, des attaques de credential stuffing, des account takeovers, ou des attaques DDoS. Toutefois, certaines zones sont plus floues, et le scraping en fait partie.
Quelle est la différence entre crawlers et scrapers ?
Voici une règle simple pour distinguer les bons bots des mauvais : les « crawlers » sont généralement considérés comme bons, tandis que les « scrapers » sont souvent nuisibles.

Les crawlers (ou robots d’indexation) sont utilisés pour indexer les informations d’une page (comme le font les moteurs de recherche tels que Google), tandis que les scrapers extraient des données spécifiques pour les réutiliser ou les vendre.
Voici quelques exemples de bons bots crawlers :
- les crawlers de moteurs de recherche (Googlebot, Bingbot, Yahoo! Slurp, Baiduspider) ;
- les crawlers de flux (Google Feedfetcher, Microsoft’s .NET WebClient, Android Framework Bot) ;
- les crawlers des réseaux sociaux (Facebook Crawler, SpiderDuck de Twitter, Pinterest Crawler).
Il existe des crawlers que vous souhaitez voir parcourir votre site web ou application mobile. Par exemple, la plupart des entreprises veulent que Googlebot explore leur site pour qu’elles soient référencées et facilement trouvées sur Google.
Cependant, si vous souhaitez bloquer certains crawlers, vous pouvez utiliser un fichier robots.txt pour leur indiquer qu’ils ne sont pas autorisés à explorer votre site. Les bons crawlers respecteront ces instructions, tandis que les bots malveillants (notamment la plupart des scrapers) les ignoreront.
Bien que le scraping ne soit pas toujours effectué dans le but de voler ou de plagier du contenu, même un scraping « bien intentionné » (si cela existe) peut entraîner des problèmes tels que :
- des pics de trafic imprévus ;
- des coûts d’infrastructure accrus ;
- des données d’analyse faussées ;
- des performances ralenties sur votre site ou application ;
- des pannes ou interruptions de service.
Chacune de ces conséquences peut nuire à votre SEO.
Les fondamentaux du SEO
Contenu original
L’un des piliers essentiels du référencement naturel est le contenu original. Les moteurs de recherche favorisent le contenu unique et pénalisent celui qui est dupliqué, ce qui signifie que vos pages deviennent plus difficiles à trouver lorsque des scrapers plagient votre contenu. Bien que l’algorithme exact utilisé par Google pour classer les résultats de recherche soit inconnu et change fréquemment, il est toujours certain que du contenu bien rédigé et original sera mieux classé que des informations recyclées ou répliquées sur plusieurs pages ou sites.
Contenu dupliqué & plagiat
Le contenu dupliqué peut apparaître de différentes manières, et il n’est pas toujours malveillant. Par exemple, vous pourriez utiliser la même image ou description de produit à plusieurs endroits sur votre site : dans une catégorie standard et dans une catégorie de soldes. Techniquement, il s’agit de contenu dupliqué, mais sans intention de tromper. De plus, toute personne recherchant votre produit trouvera au moins l’une des pages contenant les bonnes informations.
En revanche, si un scraper copie une image ou une description de produit depuis votre site et que ce contenu apparaît ailleurs sur internet, il y a maintenant un doublon de contenu sur un site tiers. Toute personne recherchant votre produit pourrait tomber sur votre site, mais aussi sur la version plagiée.
Le plagiat peut nuire à votre SEO lorsque Google tente de se débarrasser des résultats en double. Comme expliqué dans la documentation avancée de Google sur le référencement, « Google fait de son mieux pour indexer et afficher des pages contenant des informations distinctes. » Ainsi, si votre site contient une version « classique » et une version « imprimable » d’un article, et que ni l’une ni l’autre n’est bloquée par une balise noindex, Google en choisira une à afficher (qui ne sera pas forcément celle que vous auriez préférée).
Si le même contenu apparaît à plusieurs endroits ou sur plusieurs sites, Google ne peut pas toujours déterminer avec certitude qui en est l’auteur original. Il essaiera d’afficher le résultat le plus pertinent, mais il se peut qu’il se trompe. Selon SEMRush, non seulement vous pouvez être pénalisé si quelqu’un plagie votre travail, mais dans le pire des cas, l’ensemble de votre site web peut être volé.
Impact des bots sur l’originalité et la duplication du contenu
Les scraper bots rendent le vol de données massif simple et automatique : une fois programmés, ils envoient des milliers de requêtes sur votre site sans intervention humaine. Les données volées peuvent ensuite être utilisées sur un site web dupliqué, ce qui nuit gravement à votre SEO.
Si vous êtes moins bien classé qu’un site dont le contenu a été volé, vous recevrez moins de visiteurs organiques, ce qui peut avoir une incidence sur divers indicateurs clés de performance de votre entreprise. En outre, si votre site web accepte du contenu généré par les utilisateurs, mais que le filtrage et la modération font défaut, les bots peuvent automatiser la pollution des données en ajoutant des milliers d’articles volés ou de mauvaise qualité qui font paraître votre site moins digne de confiance aux yeux de Google et d’autres moteurs de recherche.
Cela peut aller bien au-delà du simple scraping de prix : par exemple, les scrapers ont également volé des descriptions de produits, des images, etc. à la marque de chaussures de luxe Kurt Geiger. Ces bots ont ralenti le site en surchargeant les systèmes avec des demandes agressives et répétées, causant des surcharges de serveurs et créant un surcroît de travail pour l’équipe DevOps.
Une fois la solution DataDome mise en place, accompagnée d’une liste blanche de partenaires et d’outils autorisés, le site de Kurt Geiger est devenu imperméable au scraping.
Haute performance et vitesse
Si un site web met trop de temps à charger, allez-vous patienter ou chercher un autre site ? La plupart des gens choisiront la deuxième option. La vitesse est essentielle.
Peut-être encore plus importante que le contenu original en matière de SEO, la performance et l’expérience utilisateur (UX) devraient être des priorités absolues pour toute entreprise en ligne. Google mesure la performance des pages à l’aide de métriques appelées Core Web Vitals (CWV), qui aident ses algorithmes de recherche à évaluer l’expérience utilisateur finale, un critère de plus en plus déterminant dans les classements.
En vigueur depuis mai 2021, les CWV se concentrent principalement sur :
- la vitesse,
- la réactivité,
- l’interactivité,
- la compatibilité mobile,
- la sécurité (HTTPS & Safe Browsing : protection contre les hackers, virus et malwares).
Les trois éléments clés des CWV qui influencent le SEO sont : Largest Contentful Paint (LCP), First Input Delay (FID), et Cumulative Layout Shift (CLS). Deux de ces trois éléments sont directement affectés lorsque des scraper bots ciblent votre site ou application :
- Largest Contentful Paint (LCP)
- First Input Delay (FID)
Largest Contentful Paint (LCP) : il s’agit du temps nécessaire pour charger le plus grand élément de contenu (image, vidéo, formulaire interactif, etc.) sur une page web. Dans un monde où la vitesse d’internet est cruciale et où tout ce qui n’est pas immédiat est considéré comme lent, Google accorde une grande importance à la rapidité de chargement. Pour Google, une page qui charge en moins de 2,5 secondes est jugée rapide. Si elle prend plus de 6 secondes, elle est considérée comme médiocre.
First Input Delay (FID) : il mesure la réactivité en fonction du délai entre le chargement de la page et la possibilité pour l’utilisateur d’interagir avec le contenu. Pour Google, les interactions pertinentes incluent la sélection d’un élément de menu, le clic sur un lien ou la lecture d’une vidéo. Les actions continues comme le défilement ou le zoom ne sont pas prises en compte dans le FID. Selon Google, un bon FID doit être inférieur à 100 millisecondes. Plus vos pages sont stables, meilleure est l’UX, et plus votre classement sera élevé.
Impact des bots sur les performances et la vitesse des sites web
Dans certains cas, les bots représentent jusqu’à 70 % du trafic d’un site web. Non seulement cela fausse les analyses, mais cela ralentit également votre site ou application, créant ainsi une mauvaise expérience utilisateur. Malheureusement, acheter plus de bande passante pour maintenir une bonne vitesse de chargement peut rapidement devenir coûteux en raison du volume de trafic généré par les bots.
Un exemple concret : les scrapers web ont volé massivement du contenu sur La Fourchette, filiale de TripAdvisor et plateforme leader de réservation de restaurants en ligne. Le trafic généré par ces bots sur Google Analytics a provoqué des pics imprévisibles et des interruptions de service sur le site et l’application mobile, ce qui a augmenté les coûts d’hébergement et de maintenance.
Après l’intégration de la solution de gestion des bots de DataDome dans leur architecture, tout le trafic provenant des bots malveillants et du scraping web a été éliminé, et la performance du site s’est améliorée. De la même manière que les scrapers ralentissent les performances, créent des interruptions de service et affectent négativement le SEO, contrôler le trafic des bots permet d’améliorer tous ces aspects. En mettant en place une bonne stratégie de prévention du scraping, vous pouvez également améliorer votre référencement naturel.
Optimisation mobile
Les appareils mobiles génèrent désormais plus de 50 % du trafic web mondial. Dans de nombreux pays, les smartphones sont plus nombreux que les ordinateurs personnels. Il n’est donc pas étonnant que Google mette l’accent sur la compatibilité mobile et les sites web réactifs.
Depuis 2018, Google a introduit l’indexation mobile-first, ce qui signifie que Google indexe votre site mobile en priorité par rapport à votre site desktop, et que ce dernier a un poids plus faible dans les résultats de recherche. Pour les nouveaux domaines, le site mobile est automatiquement indexé en premier. Si votre site mobile offre une mauvaise expérience utilisateur (UX), un contenu minimal, ou des temps de chargement lents, cela pénalisera votre classement global dans les résultats de recherche.
Avec l’essor des appareils mobiles, la majorité des entreprises proposent désormais une application mobile en complément (ou à la place) d’un site web mobile. Les applications sont conçues pour offrir une expérience utilisateur encore plus fluide sur mobile. Les meilleures applications se chargent rapidement et fonctionnent aussi bien, voire mieux, que leurs versions web.
Impact des bots sur l’optimisation mobile
Les bots ciblent de plus en plus les applications mobiles et les API, en partie parce que certaines solutions de gestion des bots ne protègent toujours pas suffisamment ces environnements spécifiques. Protéger uniquement votre site web n’est plus suffisant. Avec le nombre d’utilisateurs mobiles dépassant désormais celui des utilisateurs d’ordinateur, il est crucial de protéger vos applications mobiles et vos API des bots au même niveau que votre site web.

Lorsque les bots envahissent une application ou une API, des problèmes de performance suivent inévitablement. Tout comme pour les sites web, le trafic des bots sur les applications mobiles et les API provoque des pics de trafic imprévisibles et des interruptions de service, en plus de mettre les données des utilisateurs en danger. Et si votre site mobile, application ou API connaît des problèmes de performance, votre classement SEO en pâtira.
L’impact de la gestion des bots sur l’optimisation mobile
Détecter les bots malveillants sur une application mobile ou une API nécessite une approche bien différente de celle utilisée pour protéger un site web. Les utilisateurs n’interagissent pas avec les applications mobiles de la même manière qu’avec des navigateurs ou des sites web, ce qui signifie que le comportement des utilisateurs mobiles ne peut pas être suivi à l’aide des mêmes signaux ou uniquement avec une détection côté serveur.
La protection des applications mobiles et des API contre les bots doit s’appuyer sur une détection à la fois côté client et côté serveur. C’est crucial, car (contrairement à ce que certains fournisseurs de protection contre les bots pourraient dire), la détection côté client est le seul moyen d’identifier tous les types de trafic de bots à chaque point d’entrée et sur tous les appareils. En combinant détection côté client et modèles d’apprentissage automatique conçus pour analyser si certains comportements correspondent à des interactions humaines, vous pouvez garantir une protection complète à vos utilisateurs mobiles.
Et l’expérience utilisateur mobile dans tout ça ?
Les mauvais outils de gestion des bots nuisent à l’optimisation mobile. Une protection médiocre entraîne souvent un taux élevé de faux positifs, ce qui signifie que de vrais utilisateurs se retrouvent confrontés à des CAPTCHA ou sont bloqués complètement. Les CAPTCHA augmentent considérablement la friction pour les utilisateurs, notamment aux moments clés des conversions. Une solution de gestion des bots avec un taux de faux positifs très faible (comme celui de DataDome, qui est de 0,01 %) soutient l’optimisation mobile tout en protégeant vos utilisateurs.
La rapidité avec laquelle un outil de gestion des bots détecte, analyse et répond aux requêtes influence directement l’optimisation mobile. Par exemple, DataDome traite toutes les requêtes en moins de 2 millisecondes, ce qui n’a aucun impact négatif sur l’expérience utilisateur. Si votre gestion des bots est plus lente, l’expérience utilisateur sur mobile en pâtira.
D’autres aspects de la fraude en ligne et de la protection contre les bots qui favorisent l’optimisation mobile comprennent un faible encombrement (par exemple, celui de DataDome est inférieur à 100 kb) et une utilisation extrêmement faible de la mémoire et de l’unité centrale. La bonne solution permettra aux utilisateurs d’applications mobiles de ne jamais s’apercevoir de la présence d’une protection contre les bots.
Comment fonctionnent les scrapers ?
Le scraping web se produit lorsqu’un bot automatisé extrait des données de vos sites web, applications mobiles et/ou API, souvent à des fins malveillantes (plagiat, revente de vos données à des concurrents, etc.).
Les scrapers (ou scraper bots) peuvent différer selon les langages de programmation utilisés, mais les scrapers malveillants suivent généralement ces mêmes étapes :
- Le développeur crée un script de scraping ou utilise un logiciel dédié pour le programmer.
- Le développeur masque le scraper afin de le faire passer pour un bot inoffensif.
- Le scraper cible une URL et ses paramètres, extrait et télécharge le code HTML des sites web, applications mobiles et/ou API visés.
- Le scraper manipule et traite les données selon sa programmation, puis les stocke dans une base de données ou une feuille de calcul.
Si les scrapers ne sont pas bloqués, ils volent votre contenu et vos informations tarifaires exclusifs, drainent les ressources de votre équipe et dégradent les performances de votre site web, application mobile ou API, ce qui nuit à votre SEO. Le scraping peut être tellement gourmand en ressources que les attaquants recourent au Bots as a Service (BaaS), pour lancer des attaques de scraping massivement distribuées et très puissantes. Le schéma ci-dessous montre comment les BaaS fonctionnent.

3 conséquences majeures des scrapers
Les scrapers web peuvent avoir les impacts négatifs suivants (entre autres) sur votre entreprise :
1. Contenu volé
Les scrapers volent du contenu original, y compris des informations tarifaires, qui peuvent être utilisées pour sous-coter votre entreprise. Ce vol de contenu peut également nuire à vos classements SEO.
La plateforme e-commerce d’Hydradyne rencontrait des problèmes de scraping, ses concurrents volant des informations exclusives sur les produits et les prix, ce qui leur permettait de proposer de meilleurs tarifs. Le simple équilibrage de charge n’a pas suffi à contrer ces attaques, qui utilisaient une large gamme d’adresses IP.
Il est facile de sous-estimer l’ampleur du scraping. Ceux qui pensent ne pas avoir de problème de scraping sont probablement mal informés.
– Felipe Maurer, Senior Web Developer chez Hydradyne
Après avoir collaboré avec DataDome, tout le trafic des bots — en particulier ceux dédiés au scraping web — a été éliminé du site, protégeant ainsi les informations exclusives d’Hydradyne.
2. Problèmes de performance sur vos sites web, applications mobiles et/ou API
Les scrapers dégradent les performances de vos applications mobiles, sites web et API en générant des pics de trafic et en surchargant les serveurs avec des requêtes de scraping, ce qui entraîne une baisse des classements SEO.
3. Ressources gaspillées
Les scrapers épuisent vos ressources en augmentant les coûts d’infrastructure et en obligeant vos équipes à :
- atténuer manuellement les attaques de bots ;
- réévaluer constamment vos analyses de performance faussées ;
- résoudre des problèmes de référencement et repenser vos stratégies affectées.
Trouver le bon équilibre de protection
Le défi
Les scrapers évoluent sans cesse, ce qui signifie que les solutions internes et les produits de gestion des bots moins performants peinent souvent à s’adapter rapidement aux nouveaux types de bots. De nombreuses méthodes courantes de prévention du scraping sont inefficaces face à ces menaces modernes :
- Les CAPTCHA et reCAPTCHA peuvent être contournés par des fermes CAPTCHA, qu’il s’agisse de reCAPTCHA v2 ou v3.
- Les pare-feux d’applications web (WAF) ne bloquent que les menaces connues et ne parviennent pas à contrer les attaques de scraping sophistiquées, car les services BaaS (Bots as a Service) facilitent l’envoi de requêtes multiples depuis différentes adresses IP.
- Les conditions générales d’utilisation (CGU) peuvent offrir une protection juridique contre les scrapers, mais elles sont réactives et nécessitent que vous puissiez engager des poursuites contre les attaquants. Elles ne protègent donc pas activement contre le scraping en temps réel.
Maintenir le SEO tout en bloquant les bots malveillants
Pour optimiser votre SEO, il est crucial de permettre l’accès aux « bons » bots (ceux des moteurs de recherche, des collecteurs de flux et des réseaux sociaux) tout en bloquant les bots qui tentent de scraper votre contenu.
Il est souvent impossible pour une entreprise de trouver le juste équilibre en bloquant tous les bots en permanence. La solution idéale doit donc être suffisamment flexible pour s’adapter à vos besoins spécifiques. Les fonctionnalités ajustables essentielles doivent inclure :
- des modes de protection capables de moduler le niveau de détection et de réponse en fonction du contexte. Par exemple, les modes de protection intégrés de DataDome incluent : Équilibré (protection générale), Ventes Flash, Dernières actualités, et Sous attaque. Chaque mode ajuste la granularité de la détection et la stratégie de réponse en fonction des besoins spécifiques du moment ;
- des règles personnalisables, en complément des modes de protection par défaut « prêts à l’emploi ». En fonction de votre activité, il peut être nécessaire de créer des exceptions spéciales. Ces règles personnalisées doivent comprendre une liste autorisée pour laisser passer certains bots ou IP, et des options de planification temporelle pour définir quand les bons bots peuvent explorer votre contenu. Des fonctionnalités comme la limitation du taux, les CAPTCHA et les règles de blocage doivent être facilement ajustables. Les utilisateurs de DataDome peuvent également personnaliser leurs réponses aux menaces en fonction de plus de 15 critères pour chaque type d’attaque et point d’entrée.
Évaluer votre risque
Que vous ayez déjà un outil de protection contre les bots ou non, la première étape pour protéger votre contenu, vos prix, vos performances et votre SEO des scraper bots est d’évaluer votre niveau de risque. Vous devez être capable de surveiller le trafic des bots et les menaces en temps réel.
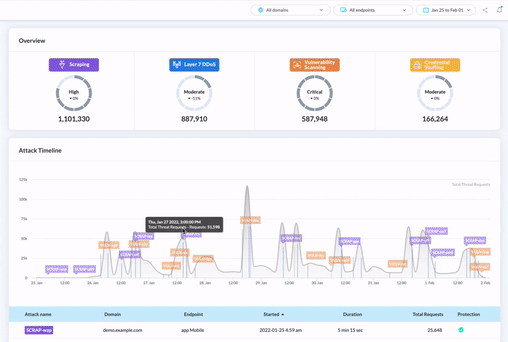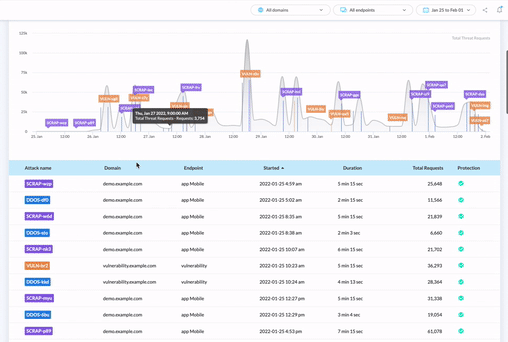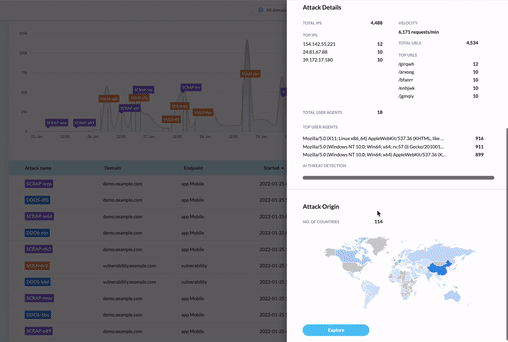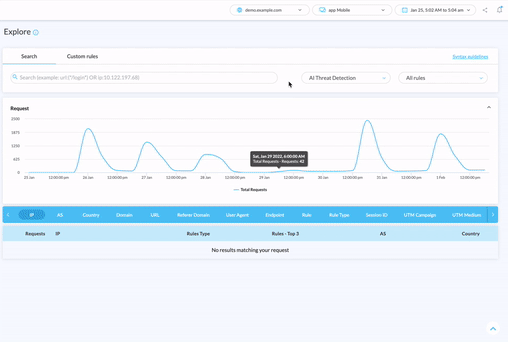
Si vous souhaitez découvrir quels bots échappent à votre outil actuel, ou simplement avoir une vue d’ensemble des menaces automatisées via un tableau de bord simple à utiliser, notre audit gratuit des menaces et essai de 30 jours est un excellent point de départ.
Si vous décidez qu’il est temps de renforcer votre protection sur tous vos points d’entrée (site web, application mobile et API), nous sommes là pour vous aider. Notre solution de protection contre les bots utilise plusieurs algorithmes pour sécuriser chaque point d’entrée spécifique contre les attaques de scraping, en analysant chaque requête adressée à vos sites, apps et/ou API pour l’autoriser ou la bloquer en temps réel.
Avec un taux de faux positifs de seulement 0,01 %, les vrais utilisateurs ne sont jamais bloqués. Et comme DataDome est entièrement dédiée à la protection contre les bots et la fraude en ligne, notre solution est toujours à jour sur les dernières menaces. Notre équipe de recherche sur les menaces et notre centre d’opérations de sécurité (SOC) sont constamment en avance sur les hackers et les nouvelles tendances des bots malveillants.

Articles liés

DataDome désigné comme leader dans The Forrester Wave™ : Bot And Agent Trust Management Software, Q2 2026
En savoir plus

Que sont les « sneaker bots » ? Comment les détecter et les éviter ?
En savoir plus

Salles d'attente virtuelles : la faille que les bots exploitent
En savoir plus

Comment choisir un système de gestion de file d'attente en ligne
En savoir plus

