




How Scraper Bots Hurt Your SEO
Search engine optimization (SEO) is a complex art that is difficult to master due to frequent changes in expectations and best practices. Yet two aspects of SEO never seem to change:
- Duplicate content has a negative impact on SEO.
- Speedy site performance is rewarded in search engine rankings.
Unfortunately, both foundational factors of SEO can be negatively affected by scraper bots before you even realize they are targeting your website or mobile app.
We’d see that a competitor was beating us for a particular search result, and discover that they were doing it by stealing our content. So we’d issue a takedown notice, but it was all reactive. In fact, we had no idea how bad our scraping problem was.
– Bill Salak, CTO at Brainly
When used for malicious purposes, scraper bots can help competitors and/or fraudsters steal your content, pricing, and other proprietary information. But even “harmless” scrapers (e.g. bots used to conduct research) can cause unexpected surges in traffic that increase infrastructure costs, slow down page loads, and can even crash your site or app.
So, how do you prevent scrapers from hurting your SEO while letting friendly bots like Google crawlers access your site? Keep reading to find out.
What we’ll cover:
Good Bots vs. Bad Bots
The first thing to understand is this—automation is not the enemy. Not all bots are bad. Automation and bots are just tools used by humans to make jobs easier. It’s up to the humans who program and operate the bots to decide whether they perform good or bad tasks.
So, what constitutes “good” and “bad”?
Sometimes, “bad” is obvious, such as using bots to commit online fraud, credential stuffing, account takeover, DDoS, etc. But there are also gray areas. “Scraping” can be one of them.
What’s the difference between crawlers and scrapers?
Here’s a general rule to help simplify the difference between good and bad bots browsing your content: “Crawlers” tend to be good and “scrapers” are often bad.

Crawlers are used to index the information on a page (essentially, crawlers do what search engines like Google do), as opposed to scrapers, which extract and use or sell specific data.
Some good crawler bots include:
- Search Engine Crawlers (Googlebot, Bingbot, Yahoo! Slurp, Baiduspider)
- Feed Fetcher Crawlers (Google Feedfetcher, Microsoft’s .NET WebClient, Android Framework Bot)
- Social Media Crawlers (Facebook Crawler, Twitter’s SpiderDuck, Pinterest Crawler)
There are actually some crawlers that you want visiting your website or mobile app. For example, most enterprises want the Googlebot to crawl their site so people can find them on Google.
But, if you ever want to block crawlers for any reason, you can use a robots.txt file to tell them they are not permitted to crawl your site. Good crawlers will respect the instructions in your robots.txt file. Bad bots (most scrapers) will ignore your robots.txt file if it forbids scraping.
While web scraping may not always be done with the intention of committing plagiarism or infringement, even well-intended scraping (if that’s a thing) leads to problems, such as:
- Spikes in Traffic
- Increased Infrastructure Costs
- Skewed Analytics
- Slower Site/App Performance
- Downtime
None of the consequences listed above have a positive impact on your SEO.
SEO Staples
Original Content
A key consideration for SEO is always original content—search engines favor original content and push non-original content down in rankings. (That makes your pages harder to discover after scrapers plagiarize your content.) While the exact algorithm Google uses to rank search results is unknown and changes frequently, unique and well-written content will always outrank information recycled across multiple pages or sites.
Duplicate Content & Plagiarism
Duplicate content can occur in a number of ways, and not all of them are malicious. For example, you could be using the same product image and description in a few places on your site, such as a standard category and then a sale category. Technically, that would be duplicate content. But you’re not intending to deceive, and anyone searching for your product will find at least one of the pages with the right content.
By comparison, if a scraper takes a product image and description from your site and the content shows up elsewhere online, there is now duplicate content on a third-party website. Anyone searching for your product might find your site, but they could also find the plagiarized content instead.
Plagiarism can affect your SEO when Google tries to get rid of duplicate results. As explained in Google’s advanced SEO documentation, “Google tries hard to index and show pages with distinct information.” Therefore, if your site has a “regular” and a “printer” version of an article, and neither version is blocked with a noindex tag, Google will choose one of them to list (which may not be the one you would have chosen).
If the same content appears in multiple places or sites, Google can’t always pick out which is the original author and which is the duplicate. Google will try to display the most relevant result, but there’s a chance they can get it wrong. According to SEMRush, not only can you be penalized as a result of someone plagiarizing your work, but in a worst-case scenario, your entire website can be stolen.
How Bots Impact Content Originality/Duplicity
Scraper bots make the task of stealing loads of data easy and automatic—they just have to be programmed and set loose to make thousands of requests on your site. The stolen data can then be used on a duplicate website, causing your SEO to suffer.
If you’re lower in the rankings than a site with your stolen content, you will receive fewer organic visitors, which can impact various KPIs for your company. Additionally, if your website accepts user-generated content, but the filtering and moderation is lacking, bots can automate data pollution by adding thousands of stolen or low-quality posts that make your site seem less trustworthy to Google and other search engines.
It can be much worse than just price scraping: Scrapers also stole product descriptions, images, and more from premium footwear brand Kurt Geiger. The bots slowed down the site with aggressive indexing and the sheer number of requests, overloading backend systems and creating a lot of extra work for the DevOps team.
Once the DataDome solution was implemented and an allowlist of partners and tools was established, the Kurt Geiger website became impervious to scraping.
High Performance/Speed
If a website loads slowly, are you more likely to wait around, or look for another site? Most people would move on to find the information elsewhere. Speed is key.
Perhaps even more important in SEO than original content are performance and user experience (UX), which should be top priorities for any online business. Google measures page performance with metrics called Core Web Vitals (CWVs) that help search algorithms get a clear picture of the end UX (increasingly important in Google rankings).
In effect since May 2021, most CWVs focus on:
- Speed
- Responsiveness
- Interactivity
- Mobile Friendliness
- HTTPS & Safe-Browsing (i.e. Protection Against Hackers, Viruses, and Malware)
The three key elements of CWVs that impact SEO are: Largest Contentful Paint (LCP), First Input Delay (FID), and Cumulative Layout Shift (CLS). Two out of three key elements suffer when scraper bots target your site or app:
- Largest Contentful Paint (LCP)
- First Input Delay (FID)
Largest Contentful Paint (LCP): Time it takes for the largest piece of content (image, video, interactive form, etc.) on a webpage to load. In a high-speed internet world where anything less than immediate is too slow, Google places significant emphasis on loading speeds. For Google, any page that loads in under 2.5 seconds is good. A page that takes longer than 6 seconds is considered poor.
First Input Delay (FID): FID measures responsiveness based on the delay between your page loading and users being able to interact with the content on it. For Google, relevant interactions include selecting a menu item, clicking a link, playing a video, etc. Continuous actions like scrolling or zooming in/out are not considered interactions in FID. “Good” FID is below 100 milliseconds, according to Google. Basically, the more stable your pages, the better the UX and the higher you’ll rank on Google.
How Bots Impact Web Performance/Speed
In some cases, bots represent 70% of a website’s traffic. Not only does this skew analytics, it slows down your website or app, creating a poor UX. Unfortunately, purchasing more bandwidth to keep your site speedy can easily become cost prohibitive due to the sheer volume of bot-driven traffic.
Case in point: Web scrapers stole content en masse from TheFork, a TripAdvisor company and leading online restaurant booking platform. The resulting Google Analytics bot traffic created unpredictable peaks and service interruptions on both the website and the mobile app, driving up TheFork’s hosting and maintenance costs.
Once TheFork chose DataDome’s bot management solution and integrated it into their architecture, all web scraping and bad bot-driven traffic were eliminated—and site performance improved. Just as scrapers slow down performance, create service interruptions, and cause SEO to suffer, controlling bot traffic helps improve all areas, including SEO. By using a good web scraping prevention plan, you can also improve your SEO.
Mobile Optimization
Mobile devices are responsible for over 50% of global website traffic. In many countries, the number of smartphones exceeds the number of personal computers, so it’s no surprise that Google places great emphasis on “mobile-friendliness” and responsive websites.
Since 2018, Google has been implementing mobile-first indexing, meaning Google indexes your mobile site before your desktop site, and the mobile site is weighted more heavily in search results. New domains are automatically indexed on the mobile site first. If your mobile site has minimal content, poor UX, and/or slow load time, your overall ranking in search results will suffer.
Because mobile devices are so prolific, most companies offer a mobile application instead of (or in addition to) a mobile website. Apps are meant to provide a more comfortable mobile UX. The best apps load quickly and work as well or better than their website counterparts.
How Bots Impact Mobile Optimization
Bots increasingly target mobile apps and APIs, in part because some bot management products still do not protect mobile apps and APIs. Understand that bot protection for your website alone is not enough. With mobile users already outnumbering desktop and laptop users, mobile apps and APIs require equal protection from bots.

Where bots swarm, performance issues follow. As with websites, bot traffic on mobile apps and APIs causes unpredictable traffic spikes and interruptions—in addition to putting user data at risk. And if your mobile website, app, or API performs poorly, your SEO rankings will suffer.
How Bot Management Impacts Mobile Optimization
Detecting malicious bots on a mobile app or API requires a much different approach than protection for a website. Because users don’t interact with apps the same way they do with web browsers and websites, mobile user behavior cannot be tracked using the same signals or with server-side detection alone.
Mobile app and API bot protection must leverage both client-side and server-side detection. This is important because (no matter what some bot protection vendors may argue), client-side detection is the only way to detect all different kinds of bot traffic at all endpoints on all devices. With client-side detection and machine learning models built solely to determine whether certain interactions are consistent with human behavior, your mobile users can be thoroughly protected.
But what about the mobile user experience?
The wrong bot management tools hinder mobile optimization. Subpar protection tends to have a high false positive rate—meaning real users see CAPTCHAs or get blocked entirely. CAPTCHAs create a lot of extra friction for the end user, particularly at key conversion points. A bot management solution with a very low false positive rate (like our false positive rate: 0.01%) will support mobile optimization while also protecting your users.
The speed with which a bot management tool detects, analyzes, and responds to requests will also either support or impede mobile optimization. For example, DataDome processes all requests in under 2 milliseconds, having no negative impact on the end user experience. If your bot management responds more slowly, your mobile user experience will be suboptimal.
Other aspects of online fraud and bot protection that support mobile optimization include a small footprint (e.g. DataDome’s is less than 100kb) and extremely low memory and CPU usage. The right solution will ensure mobile app users never notice bot protection is there.
How Scrapers Work
Web scraping occurs when automated bots extract data from your websites, mobile apps, and/or APIs—typically for harmful purposes (plagiarism, reselling your data to competitors, etc.).
Scrapers (or “scraper bots”) can vary wildly across different programming languages, but bad scrapers have the same general principles:
- The developer writes the scraper script or programs it using web scraper software.
- The developer masks the scraper to make it appear benign.
- The scraper targets a URL address and its parameter values, scraping and downloading the HTML of the targeted websites, mobile apps, and/or APIs.
- The scraper alters and manipulates the data in whatever way it was programmed to, and then pours the data into its own database or spreadsheet.
Web scrapers, if left unchallenged, steal your proprietary content and pricing information, drain your team’s resources, and degrade your website, mobile app, and API performance—hurting your SEO. Scraping can be so resource-intensive that attackers resort to bots as a service (BaaS) to hit websites with powerful, heavily distributed scraping attacks. The schema below shows how BaaS operate.

3 Key Consequences of Scrapers
Web scrapers can have the following negative impacts (among others) on your business:
1. Stolen Content
Scrapers steal original content, including prices that can be used to undercut your business. Stolen content can also negatively impact your SEO rankings.
Hydradyne’s e-commerce platform was struggling with scrapers stealing proprietary product and pricing information, which made it easy for competitors to beat their prices. Simple load balancing could not prevent the attacks, which used a wide range of IP addresses.
It’s easy to underestimate the level of scraping that’s out there. People who think they don’t have a scraping problem are probably uninformed.
– Felipe Maurer, Senior Web Developer at Hydradyne
Once Hydradyne partnered with DataDome, all bot traffic—especially bots used for web scraping—was eradicated from the site and Hydradyne’s proprietary information was safe.
2. Performance Issues on Your Websites, Mobile Apps, and/or APIs
Scrapers degrade your mobile app, website, and API performance by creating traffic spikes and overloading servers with scraping requests. Poor performance lowers SEO rankings.
3. Wasted Resources
Scrapers drain resources by driving up infrastructure costs and requiring your employees to spend time:
- Manually mitigating bot attacks.
- Constantly reassessing your skewed performance analytics.
- Troubleshooting and rethinking your suffering SEO strategy.
Finding the Right Protection Balance
The Challenge
Scrapers are constantly evolving, meaning in-house solutions and subpar bot management products often can’t adapt quickly enough to detect new types of bots. Many common scraping prevention methods fall short:
- CAPTCHAs and reCAPTCHAs can be solved by CAPTCHA farms, whether you’re considering reCAPTCHA v2 vs v3 or not.
- Web Application Firewalls (WAFs) can block familiar threats only, not sophisticated scraping attacks because BaaS make it easy to send several requests from different IPs.
- Terms and Conditions (T&Cs) help protect you in litigation against web scrapers, but T&Cs are reactive and you need to be able to bring the attackers to court. T&Cs don’t actively prevent web scraping.
Supporting SEO While Blocking Bad Bots
The key to supporting SEO is letting the “good” search engine, feed fetcher, and social media crawler bots through while blocking the bad bots attempting to scrape your content.
Most businesses can not achieve the right balance by blocking all bots at all times. Therefore, the right solution must be easy to customize to best fit your business needs. Adjustable features should include:
- Protection modes that adapt the detection and response aggressiveness to fit certain contexts. DataDome’s built-in protection modes, for example, include: Balanced (general protection mode), Flash Sales, Breaking News, and Under Attack. Each mode optimizes your detection granularity and response strategy based on context.
- Custom rules should be available—in addition to “set-and-forget” default protection modes—in case your business calls for special exceptions. Custom rules should include an allowlist for bots and IPs you want to permit on your platform and timeblocking so you can schedule when good bots are allowed to crawl your content. Rate limiting, CAPTCHA, and block rules should all be easily adjustable. DataDome users can also customize all responses (if needed) via 15+ criteria for each threat, attack, and endpoint.
Evaluating Your Risk
Whether or not you already have a bot protection tool in place, the easiest first step you can take to keep scraper bots away from your content, pricing, performance, and SEO rankings is to evaluate your level of risk. You need to see your bot traffic and threats in real time.
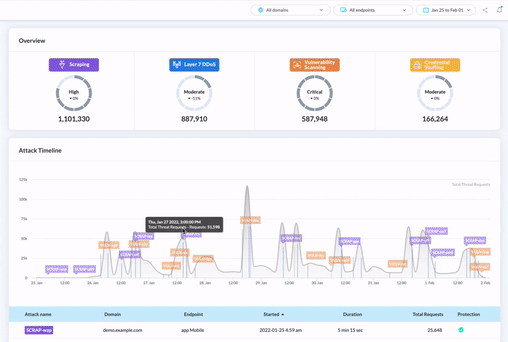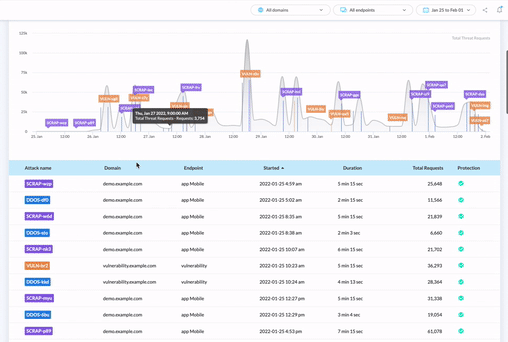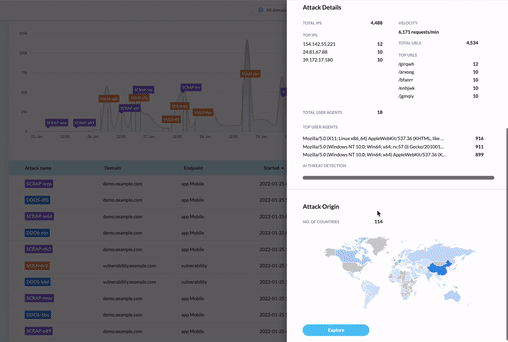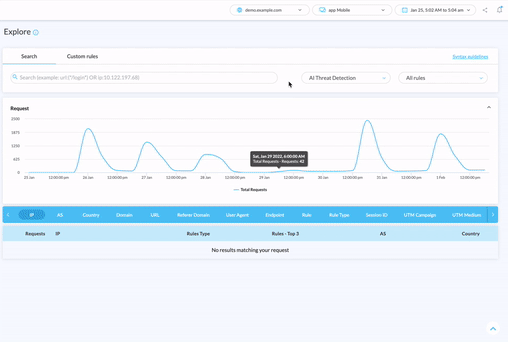
If you want to find out which bots are sneaking past your existing tool, or you just want to scope out your automated threats through a user-friendly dashboard, our free threat audit and 30-day trial is a great place to start.
If you decide now is the time to bolster your protection at all endpoints across your mobile app, website, and APIs, we’re here to help. Our bot protection solution uses multiple algorithms to protect each specific endpoint against web scraping attacks, analyzing every request to your sites, apps, and/or APIs to either block or authorize it in real-time.
Our 0.01% false positive rate means that real users are never blocked. And because DataDome is uniquely focused on bot and online fraud protection, our solution is constantly up to date on the latest threats. We have a dedicated threat research team/security operations center (SOC) that is always ahead of hackers and the latest bad bot trends.

Related posts

How BPX Protected Revenue-Critical APIs from 6.6M Price Scraping Attacks
Tell me more

Etix Stops Ticket Scalping Without Slowing Down Real Fans
Tell me more

What Is an Anti-Bot Solution and How Does It Protect Your Business?
Tell me more

How DataDome Blocked an 80M-Request Scraping Attack on a Leading Review Platform
Tell me more

